2010年11月25日 (木) 佐川メール便。ネットで散々言われてる佐川だけど今日までは何とも思ってなかった。でもね、ポストに入らない大きさのアマゾンのメール便の角をポストに突き立てて、全体の80%を表の道路に露出させておくのってどう? 今日なんて CDサイズのメール便が表の道路に落ちてたけど!!!配達する品に責任が持てないなら運送業やめちまえ。よっぽど「届いてない。どうするんだ(拾って再配達するか、見つけられないなら賠償しろ)」って電話しようかと思った。一応書いておくと毎回こうなのではなくて、袋に入れて玄関のドアノブにかけてあったり、ドアにたてかけてあったりすることの方が多い。でも今日は腹立った。発売を待ちかねてた商品だからなおさら。ジュンク堂はヤマトかゆうパックで配送なんだね。ゆうパック(元ペリカン)のおっちゃんが一番感じがいいのだ。近畿2府4県を対象にしたジュンクお急ぎ便も嬉しい。しばらくはアマゾンで探してジュンク堂で買ってみよう。お急ぎ便やプライムが始まってから発送まで一日余計にかかるようにもなってたしね(ジュンク堂がそれより遅いか早いかはわからんけど)。
最終更新: 2014-06-24T05:36+0900
♪ [javascript] アマゾンの URLに含まれる ISBNっぽい数字をジュンク堂で検索するブックマークレット。
@2010-12-24 ISBN-10はチェックディジットが Xになることがあるんだった。修正。
スクリプト
void function() {
var isbn = (location.href.match(/\b[0-9]{9}[0-9X]\b/)||[])[0];
if (isbn) {
var url = "http://www.junkudo.co.jp/find.jsp?isbn="+ isbn;
open(url);
}
}();
URLエンコードしたもの
javascript:void%20function()%20{%20var%20isbn%20=%20(location.href.match(/\b[0-9]{9}[0-9X]\b/)||[])[0];%20if%20(isbn)%20{%20%20var%20url%20=%20"http://www.junkudo.co.jp/find.jsp?isbn="+%20isbn;%20%20open(url);%20}%20}();
@2013-04-29
24日に行われたらしいリニューアルの影響だろう。ISBN検索の URLが変わっててブックマークレットを実行してもトップページへ飛ぶ。
- トップページにある検索ボックス。ページを行って戻るたびに中身をクリアするな。
- トップページにある検索ボタンの隣の詳細検索ボタン。ボタンではなくリンクでないといけない。
- 詳細検索でISBNを検索したときに POSTしてるパラメータをフォームの ACTION(/mj/products/list.php, 検索結果ページ)に付加して GETしてもダメみたいなので、ブックマークレットはおしまい。なんで POSTでなければいけないと思ったんだろう。なんで GETであるべきだと考えなかったんだろう。
ユーザビリティとアクセシビリティの下がるリニューアルでしたね。買いたい本にね、たどり着けないんですよ。いちいちいちいち検索してカートに入れて検索してカートに入れて、やらないよ? あ、間違えた、と戻ったらまたイチから入力せんならんのですよ。
@2013-04-30 しょうもない。実にしょうもない。
void function() {
var h = function(text) {
var map = {"&":"&", "<":"<", ">":">", "\"":"""};
return text.replace(/[&<>"]/g, function(m0){ return map[m0]; })
};
var post = function(url) {
var _ = url.split(/[?;&]/);
var form = document.createElement("form");
form.method = "post";
form.acceptCharset = "utf-8";
form.action = _.shift();
for (var i = 0; i < _.length; ++i) {
var nv = _[i].split("=", 2);
_[i] = '<input type="hidden" name="'+h(nv[0])+'" value="'+h(nv[1])+'" />';
}
form.innerHTML = _.join("");
document.body.appendChild(form).submit();
};
var url_frag = "http://www.junkudo.co.jp/mj/products/list.php?zssearch_isbn=";
var isbn = (location.href.match(/\b[0-9]{9}[0-9X]\b/)||[])[0];
if (isbn) {
post(url_frag + isbn);
}
}();
動作することを Firefox 20.0でだけ確認。
javascript:void%20function(){var%20h=function(text){var%20map={"&":"&",%20"<":"<",%20">":">",%20"\"":"""};return%20text.replace(/[&<>"]/g,function(m0){return%20map[m0];})};var%20post=function(url){var%20_=url.split(/[?;&]/);var%20form=document.createElement("form");form.method="post";form.acceptCharset="utf-8";form.action=_.shift();for(var%20i=0;i<_.length;++i){var%20nv=_[i].split("=",2);_[i]='<input%20type="hidden"%20name="'+h(nv[0])+'"%20value="'+h(nv[1])+'"%20/>';}form.innerHTML=_.join("");document.body.appendChild(form).submit();};var%20url_frag="http://www.junkudo.co.jp/mj/products/list.php?zssearch_isbn=";var%20isbn=(location.href.match(/\b[0-9]{9}[0-9X]\b/)||[])[0];if(isbn){post(url_frag+isbn);}}();
詳細検索の ISBNの欄にはハイフン抜きの10桁または13桁っていう但し書きがあるけど、チェックディジットが Xの ISBN-10に対して詳細検索が本を見つけられない(普通の検索なら問題ない)。試したのは「477415654X」と「404886775X」と「404854473X」。どこまでも買わせないつもりなんだな(二度目の
@2013-09-25 やっと買える。
チェックディジットが Xの ISBN-10を詳細検索して本が見つけられるようになってた。5か月かかったね。
2010年01月31日 (日) PS3 + リーンベル + torne = 買うしか
最終更新: 2010-04-17T12:23+0900
♪ [javascript] JSLint
コマンドプロンプトで利用できる WSH版がある。
「JavaScriptの構文チェッカーJSLintをEmacsから使う - 檜山正幸のキマイラ飼育記」にならって、サクラエディタで、編集中の .jsファイルをチェックできるようにしよう。
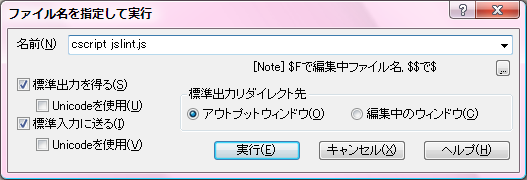
といっても、ダウンロードしてきた jslint.jsをパスの通った場所(ちょっと試してみるだけならエディタで開いているファイルと同じディレクトリ)に置いて、「ツール」>「外部コマンド実行」で「cscript jslint.js」と入力するだけだった。
jslint.js自身を開いた状態で実行した結果はこう。
#============================================================
#DateTime : 2010-02-01 06:44:29
#CmdLine : cscript jslint.js
#============================================================
Microsoft (R) Windows Script Host Version 5.7
Copyright (C) Microsoft Corporation 1996-2001. All rights reserved.
Lint at line 312 character 9: All 'debugger' statements should be removed.
debugger;if(!/^[A-Za-z][A-Za-z0-9._:\-]*$/.test(v)){warning("Bad id: '{a}'.",nexttoken,v);}else if(option.adsafe){if(adsafe_id){if(v.slice(0,adsafe_id.length)!==adsafe_id){warning("ADsafe violation: An id must have a '{a}' prefix",nexttoken,adsafe_id);}else if(!/^[A-Z]+_[A-Z]+$/.test(v)){warning("ADSAFE violation: bad id.");}}else{adsafe_id=v;if(!/^[A-Z]+_$/.test(v)){warning("ADSAFE violation: bad id.");}}}
終了コード: 1

- debuggerの使い道って何だろう。
- jslint.jsの copyrightは 2002年だけど、コメントを除いた一番最初に "use strict" なんて書いてある。それは「Final final final final draft Standard ECMA-262 5th edition」というタイトルの PDFファイルで少し前に見たものだ。実装が先にあったのか知らないけど、対応が早い!
- jslint.jsの出力は StdErrなんだけどサクラエディタはお構いなしに標準出力と合わせて取得している。面倒なことを考えずに済んで助かった。
2009年10月16日 (金) [SakuraEditor]「折り返ししている物理行末を、キーボードで左から右へ矩形選択しようとすると、次の物理行にカーソルが移動して意図した通りに選択できません」折り返されている行末へカーソルがたどり着いた瞬間、次の行の頭に移動していて右端の一列が選択できない。たしかに問題。折り返し込みの矩形選択とか、コピペしたときにどうなるのが正しいのか想像できないんだけど……。矩形選択は図形的な操作だから、折り返しがあろうが改行があろうが、右へ範囲を広げている最中にキャレットが左へ戻ってしまうというのが意外な感じはする。
最終更新: 2009-10-17T03:43+0900
♪ [javascript] 空文字列にマッチした後の lastIndexの値は IEの挙動が妥当。
var re = /\b/g; var match = re.exec( "012" ); alert( match.index ); //=> 0 alert( re.lastIndex ); //=> 0(ECMAScript仕様), 1(IE)
仕様では 何度 re.execを実行しても re.lastIndexが 0から増加しないから、re.execをループで実行するときにはマッチ結果が幅0のときに限り特別に lastIndexをインクリメントする処理が必要になる。
lastIndexが 1ではいけないの?
マッチの範囲は "0"の直前から "0"の直前までで、lastIndexは範囲の末尾の次の位置を指すもの。マッチの幅は0。
index = 0; lastIndex = 1; であればマッチ範囲は "0"(幅1)ということになってしまい正しくない。
index = 0; lastIndex = 0; であればマッチの幅が 0だということも、その位置が "0"の手前だということも表現できていて正しい気がする。
でも、lastIndexってパターンオブジェクトのプロパティ……
indexはマッチ結果のプロパティだけど、lastIndexはパターンオブジェクトのプロパティなのだ。match.index...re.lastIndexの範囲が正しいとか正しくないとかは考慮に値しないのではないか。
検索結果に影響があるかといえば、スクリプトエンジンが行ってくれないことを、スクリプトを書く人間が手作業で行っているだけなのだから影響はないだろう。
IEは至極まっとうな実装をしたと思う。
2008年12月23日 (火) 新☆はてブ < スクロールが重いからピンを抜いたのにカテゴリを選び直すだけで元に戻る鳥頭。そこは Cookieを使うべきところです。(潔癖症の人はどうせ拒否設定してるでしょう)
♪ [SHJS][javascript] SHJS-0.6がリリースされていた。(2008年12月15日)
アナウンスされている変更点は…… (注: 日本語部分は俺の勝手な訳のような注釈のようなもの)
December 15, 2008 - SHJS 0.6
SHJS 0.6 is available for download.
SHJS 0.6 includes several new features, improvements and bug fixes:
SHJS is now distributed under version 3 of the GNU General Public License. (Older releases of SHJS were distributed under version 2 of the GNU GPL.)
ライセンスが GPLv2から GPLv3へ変更。
Markup inside pre elements is now preserved.
PREタグの中の HTMLマークアップが保存される。(以前は Node.dataを再帰的に取り出したもの。乱暴にいうと PRE.{innerText|textContent}に相当するものが利用されていた。ver.0.5ではマークアップとして <br>のみが考慮されていた。)
Several new languages (from the latest release of GNU Source-highlight) are included: S-Lang, Scala, Java properties files, Desktop files, LSM (Linux Software Map) files, Xorg configuration files, RPM spec files, Haxe, LDAP files, GLSL, Objective Caml, Standard ML, JavaScript with DOM, and C (separate from the C++ language file).
最新の GNU Source-highlightから新しい言語ファイルを追加。JavaScriptには DOMキーワードを含んだ lang/sh_javascript_dom.jsが追加された。(sh_javascript_dom = sh_javascript + applicationCache|closed|Components|content|controllers|crypto|defaultStatus|dialogArguments|directories|document|frameElement|frames|fullScreen|globalStorage|history|innerHeight|innerWidth|length|location|locationbar|menubar|name|navigator|opener|outerHeight|outerWidth|pageXOffset|pageYOffset|parent|personalbar|pkcs11|returnValue|screen|availTop|availLeft|availHeight|availWidth|colorDepth|height|left|pixelDepth|top|width|screenX|screenY|scrollbars|scrollMaxX|scrollMaxY|scrollX|scrollY|self|sessionStorage|sidebar|status|statusbar|toolbar|top|window + alert|addEventListener|atob|back|blur|btoa|captureEvents|clearInterval|clearTimeout|close|confirm|dump|escape|find|focus|forward|getAttention|getComputedStyle|getSelection|home|moveBy|moveTo|open|openDialog|postMessage|print|prompt|releaseEvents|removeEventListener|resizeBy|resizeTo|scroll|scrollBy|scrollByLines|scrollByPages|scrollTo|setInterval|setTimeout|showModalDialog|sizeToContent|stop|unescape|updateCommands|onabort|onbeforeunload|onblur|onchange|onclick|onclose|oncontextmenu|ondragdrop|onerror|onfocus|onkeydown|onkeypress|onkeyup|onload|onmousedown|onmousemove|onmouseout|onmouseover|onmouseup|onpaint|onreset|onresize|onscroll|onselect|onsubmit|onunload)
Many other languages have minor improvements.
言語ファイルのアップデート。
Compressed .min.css stylesheets are now included in the distribution.
最小化した CSSファイルを同梱。(.jsも .cssも YUI Compressorを使用。ver.0.5までは .jsのみが JSMinで処理されていた)
Please note that the format of language-specific JavaScript files has changed in SHJS 0.6. JavaScript language files from version 0.6 will not work with sh_main.js from previous releases, and vice versa. Make sure you upgrade both the sh_main.js file and language-specific files.
古い言語ファイル(lang/*.js)と新しいメインスクリプト(sh_main.js)は互換性がない(逆も同じ)。両方入れ替えるべし。
大きな変更は <pre></pre>内の HTMLマークアップがシンタックスハイライト後も保存されること。(タグがたすき掛けになるときはどうするんだろ?)
言語ファイルの変更は小さくて、"next"、"regex"、"style"、"exit"というプロパティを持ったパターンオブジェクトが、3要素の配列になっている。
異種document対応が必要では? (sh_main.js)
function sh_highlightElement(element, language) {
sh_addClass(element, 'sh_sourceCode');
var originalTags = [];
var inputString = sh_extractTags(element, originalTags);
var highlightTags = sh_highlightString(inputString, language);
var tags = sh_mergeTags(originalTags, highlightTags);
// この documentFragmentはグローバル変数の document由来。
var documentFragment = sh_insertTags(tags, inputString);
while (element.hasChildNodes()) {
element.removeChild(element.firstChild);
}
// element.ownerDocument != documentFragment.ownerDocumentのとき失敗しませんか?
element.appendChild(documentFragment);
}
コメントを参照のこと。IEのバージョンが 5.5くらいだった時に失敗したような記憶が根拠で、確証はないし、レアケースだとは思うけど。(フレームをまたいで sh_highlightElement(element, language)を呼び出したとき(=スクリプトとエレメントが異なるドキュメントに属するとき)に起こるかなぁ?)
タグのたすき掛けの結果
before
<pre class="sh_ruby"> require 'sqlite3' <strong>require</strong> 'sqlite3' <strong>req</strong>uire 'sqlite3' </pre> <pre class="sh_javascript"> /* http://example.com http://example<em>.</em>com */ </pre>
after
<pre class="sh_ruby sh_sourceCode"> <span class="sh_preproc">require</span> <span class="sh_string">'sqlite3'</span> <strong><span class="sh_preproc">require</span></strong> <span class="sh_string">'sqlite3'</span> <strong><span class="sh_preproc">req</span></strong><span class="sh_preproc">uire</span> <span class="sh_string">'sqlite3'</span> </pre> <pre class="sh_javascript sh_sourceCode"> <span class="sh_comment">/*</span> <a href="http://example.com" class="sh_url">http://example.com</a> <a href="http://example.com" class="sh_url">http://example</a><em><a href="http://example.com" class="sh_url">.</a></em><a href="http://example.com" class="sh_url">com</a> <span class="sh_comment">*/</span> </pre>
SHJSの挿入するタグは必要に応じてぶつ切りにされるみたい。
追記@2009-02-25: 手製の言語ファイル( rubyと javascript)を 0.6フォーマットに変換した。(最小化方法は依然として JSMin)
- /shjs/0.6/lang/sh_javascript.js
- /shjs/0.6/lang/sh_javascript.min.js
- /shjs/0.6/lang/sh_ruby.js
- /shjs/0.6/lang/sh_ruby.min.js
移行スクリプトはこれ( migrate_05_06.js )。shjs-0.5までの lang/sh_*.jsファイルをドロップすると lang/sh_*.06.jsというファイルができてくるという寸法。ちなみに JScript製。
テストもかねてバージョン 0.6を走らせてみたけど、軽くなってる道理がない*ので、この日記では shjs-0.4.2に手を入れたものを使い続けている。
追記@2009-04-06: 0.6いいね。
言語ファイルのフォーマット変更は速度的に有利。
パターンマッチの結果を Stateをまたいで保存するようになっているので、この日記の sh_ruby.jsのようにあっちこっち跳びまわる言語ファイルに有利に働く。いちばん時間を消費しているのが RegExp.exec()と DOMツリーへの HTML断片の追加なのでパターンマッチ結果のキャッシュは大事。(もっとも 0.4.2のときからキャッシュの拡大は個人的にやっていた)
* <pre>内のマークアップを保存するためにハイライト前と後の、二つの HTML文字列をマージしている。でもその機能、俺個人はいらないのよね。
2008年10月24日 (金) [HTML] Logicoolのサイトはキーボードでもタブの切り替えができて偉い。(スクリプトをOFFにするとマウスを使ってさえ表示を切り替えられなくなったが……)
♪ [HTML][javascript] 補助に徹する賢い JavaScriptの使い方
基本はこう。
- HTMLのみで情報を配置する。
- CSSで見栄えを整える。
- スクリプトで効果やアクションを付け加える。
Logicoolのサイトのタブコントロールはキーボードインターフェイスを具えていて偉い、と書いたばかりだが、スクリプトがオフだと、タブの切り替えができないばかりか、タブの中身、肝心の情報が表示されないのはイクナイ。
スクリプトで各タブの表示・非表示を切り替えているのだろうが
- タブの状態のデフォルトは非表示
- スクリプトで一つだけを表示に切り替え
ではなく
- タブの中身はデフォルトで表示
- スクリプトで一つ以外を非表示に切り替え
が、より良いやり方ではないか。(一瞬全ての情報が表示されてすぐに消える、というのは気にすることではないと思っている)
ロジのサイトのこのスクリプトは見栄えをいじるだけなので、HTMLとスクリプトを切り離して、最初に HTMLのみでページを作り、スクリプトは後からアタッチするものだと考えて欲しかった。
スクリプトに依存する要素があって切り離せない場合は、Amazon.co.jpがやっているように
- <noscript>の中に、スクリプトを使わない代替 HTMLを用意する (できなければないで仕方がない)
- <script>の中で、スクリプトを必要とする要素を、スクリプトを使って配置する
方法が賢いと思っている。
ちょっとだけ関連
2008年05月27日 (火) [Firefox] 領域を選択してのソース表示は、スクリプトに書き換えられた最新の HTMLを反映しているのが便利。
♪ [Firefox][javascript][SHJS] <pre>が真っ白になり、黒色の領域が出現する。
例えばこのページ http://vvvvvv.sakura.ne.jp/ds14050/diary/20080112-7.html 。Endキーで末尾に移動して PageUpで戻っていくと空白の PREが目に入ると思う。その少し上にはページの内容を覆い隠す黒い領域があるはず。(そうでなければ修正されたのだろう。Firefox2で最初に確認し、Firefox3.0RC1でも直っていなかったが)
大量の PREが存在したり、一つだけでも巨大な PREが存在する場合に起こる様子。innerHTMLで PREの内容を置き換えているのも原因になっているかもしれない。
画面の末端にスクロールした状態でページをリロード(F5 or Ctrl+R)すると下方の PREが正常に表示される反面、上端付近の PREに同じ問題が生じる。遠方の PREの書き換えに問題があるのでは?
真っ白の PREの中で、右クリックしたりテキストを選択したりといったアクションを起こせば正常に表示されることが多い。
あと、PREの中から開始した選択は PREの外に出られなかったり。(これは TEXTAREAと違い PREでは Ctrl+Aで全文選択ができないために用意された代替手段だという気もする)
2008年05月14日 (水) DFAエンジンのマッチの仕組みは謎のまま残された。正規表現を利用する側からはコントロールできる部分が皆無で、常に同じ結果が返ってくるおもしろみのないものらしいけど、その魔法の実現方法は大いに知りたい。
♪ [正規表現][javascript][大型本] Jeffrey E.F. Friedl【詳説 正規表現 第3版】 オライリージャパン
読んだ。この日記で以前書いたようなこと(20080116p01, 20080111p01)は全て書いてあった。もちろんそれ以上に知らないこと(NFAのマッチングのしかた、NFA型正規表現エンジンに適用できる正規表現のチューニングの具体例、Unicodeサポート、Perl, .NET, Java, PHPの正規表現、\Gの使い方などなど)が書かれていた。
非常に読みやすい文章で書かれているし、必要なところでは必ず前後のページへの参照先が書かれている。章の始めには Overviewがあり、その章から読み始めた読者への配慮も忘れない。当たり前のことだけど、徹底されている。「まずこの本を読め。正規表現について話すのはそれからだ。」と言い切れる良い本。正規表現を初めて学ぶ人にも、効率について考える余地ができてくるほど既に正規表現を使っている人にも役に立つ。
すごく実用的なテクニックで、でも全く想像が及ばなかったものがある。168ページの「4.5.8.1 肯定の先読みを使ったアトミックグループの模倣」がそれ。
肯定の先読みを使ったアトミックグループの模倣
/(?>pattern)/ // アトミックグループを使ったパターン /(?=(pattern))\1/ // 先読みでアトミックグループを模倣したパターン
高機能化する他の実装にくらべて、昔のままの JavaScriptの正規表現はバックトラックを抑制する構文を持っていない。JavaScriptでは非常に有用。
20080116p01でも書いたが、次の終わらない正規表現
/"(?:[^\\"]+|\\.)*"/ // マッチに失敗するとき死ぬほど遅い
はアトミックグループや絶対最大量指定子が使えるなら次のように書けるが JavaScriptは両方ともサポートしていない。
/"(?:[^\\"]+|\\.)*+"/ // JavaScriptでは使えない /"(?>(?:[^\\"]+|\\.)*)"/g // JavaScriptでは使えない /"(?:[^\\"]++|\\.)*"/ // JavaScriptでは使えない。※上2つとは少し意味が違う
次のように先読みでアトミックグループを模倣すると組み合わせの爆発を避けることができる。
/"(?=((?:[^\\"]+|\\.)*))\1"/ /"\1"/ // 上のパターンから先読み部分を取り除いたもの。
先読みを取り除いたパターンを見ると一目瞭然だが、引用符がペアになっていなくて \1 の後ろの " のマッチに失敗したとしても戻る場所がない。あるのは " と \1 にマッチしたという結果で、どちらもオプションではないので取り消すことはできず、繰り返しでもないのでマッチした部分を少しずつ手放させることもできない。なので、ちょっとずつ後じさりしながら延々とあらゆる組み合わせのマッチを試行することなしに、マッチが失敗に終わったことが即座に判断できるようになるというわけ。本物のアトミックグループよりは劣るが効率も悪くない。同じ働きをする次の二つのパターンとかかる時間を比較してみた。
/"[^\\"]*(?:\\.[^\\"]*)*"/ /"(?:[^\\"]|\\.)*"/
手順
バックトラックによる組み合わせの爆発が起きない 3つのパターンでかかる時間を比較。3回実行した。(3回繰り返しても一回一回の中の試行順が固定されていたら傾向は同じになるわな。無意味。あてみやむいみ)
var re = [
/"(?:[^\\"]|\\.)*"/,
/"(?=((?:[^\\"]+|\\.)*))\1"/,
/"[^\\"]*(?:\\.[^\\"]*)*"/
];
var s = [
'"'+ new Array(5000+1).join('\\"'), // 1/100
'"'+ new Array(500000+1).join('\\"') +'"',
'"'+ new Array(500000+1).join("\\'"),
'"'+ new Array(500000+1).join("\\'") +'"',
'"'+ new Array(500000+1).join('a'),
'"'+ new Array(500000+1).join('a') +'"'
];
var results = [];
for(var j = 0; j !== s.length; ++j) {
var result = [];
for(var i = 0; i !== re.length; ++i) {
var t0 = new Date();
var m = re[i].exec(s[j]);
result[i] = new Date() - t0;
}
results[j] = result;
}
WScript.Echo(results.join("\n"));
結果
数の単位は msec。
| パターン1 | パターン2 | パターン3 | |||
| 工夫なし | アトミックグループの模倣 | ループ展開 | |||
| /"(?:[^\\"]|\\.)*"/ | /"(?=((?:[^\\"]+|\\.)*))\1"/ | /"[^\\"]*(?:\\.[^\\"]*)*"/ | |||
|---|---|---|---|---|---|
| 文字列1 | マッチしない(F) | "\"\"......\"\" | 2910×100, 2928×100, 2914×100 | 2551×100, 2581×100, 2595×100 | 2372×100, 2387×100, 2377×100 |
| マッチする(T) | "\"\"......\"\"" | 124, 124, 124 | 138, 137, 134 | 108, 107, 108 | |
| 文字列2 | マッチしない(F) | "\'\'......\'\' | 138, 140, 151 | 125, 127, 125 | 122, 118, 118 |
| マッチする(T) | "\'\'......\'\'" | 138, 126, 126 | 140, 128, 133 | 135, 105, 106 | |
| 文字列3 | マッチしない(F) | "aa..........aa | 174, 172, 166 | 14, 11, 13 | 96, 90, 92 |
| マッチする(T) | "aa..........aa" | 155, 119, 126 | 32, 15, 14 | 15, 12, 11 | |
みどころ
- マッチに失敗するときの、成功するときに比べた遅さ。
- パターン2は例外
- パターン2(アトミックグループの模倣)ではしばしばマッチに失敗する方が速い。
- \1のマッチが成功だと判断するにはキャプチャした長い長い文字列を最後までたどって比較する必要があるため、\1のマッチに失敗するほうが速くなる?
- 文字列1Fの特筆すべき遅さ。
- 遅いとはいえ「終わらない」と形容するほど遅くはない。(これでも!)
- 文字列長に比例したバックトラックが行われているせい?
- 文字列2Fの結果と比較するに、\" という形で " が文字列の途中に含まれていることが最適化を阻んでいる?
- パターン3(ループ展開)は特定の場合を除いてパターン2(アトミックグループの模倣)より若干速い。
- ループ展開は『詳説 正規表現』に載っていた言葉。
- 特定の場合とは文字列3Fのことで、不用意なパターンを用いると処理が終わらなくなる場合のこと。
- パターン2(アトミックグループの模倣)は、(今回の眼目である)組み合わせの爆発が起こるような場合に、顕著な速さを見せる。
- 他の文字列ではパターン3(ループ展開)に半歩譲るが。
ところで、文字列1Fがどのパターンでも一様に遅いのは文字列長に比例したバックトラックが行われているからなんだろうが、パターン2(先読みによるアトミックグループの模倣)でもそれを抑制できていないのは、なんとかできないものか。それでこそ若干のオーバーヘッドをのんででもアトミックグループの模倣を採用する理由になるのだが。
2008年02月21日 (木) エクスプローラはバカだエクスプローラはバカだエクスプローラはバカだ。desktop.iniは目障りな上に役に立っていない。(C:\Windowsが音楽フォルダって何? 実体のないフォルダ(マイコンピュータ、ごみ箱、デスクトップ、ユーザー)の表示設定も保存して)
♪ [javascript] JavaScriptの、空文字列にまつわる微妙な点 (String.split(), RegExp.lastIndex)
空文字列を split()
split()の第一パラメータ separatorが空文字列にマッチするかどうかで結果が異なる。
"".split(" ").length; // 1 (空文字列にマッチしないから)
"".split("").length; // 0 (空文字列にマッチするので)
"".split(/\s+/).length; // 1 (空文字列にマッチしないから)
"".split(/^$|\s+/).length; // 0 (空文字列にマッチするので)
function getClasses(element) {
return element.className.split(/^$|\s+/);
}
追記@2008-05-28: 空白で始まったり空白で終わるときのことを考えていなかった。
上の functionでは classNameが空っぽの時には空文字列の要素を作らないが、頭や尻尾に空白が付いていると空文字列の要素が残る (IEを除いて)。事前にトリミングする手間をかけるくらいなら一個二個の空文字列を気にせず(だけど連続する空文字列の要素は気にしてる) className.split(/\s+/) とする方が好みだな。
空文字列にマッチした後の lastIndex
IE7と Firefox2で異なる。Firefox2の方が正しいが無限ループに陥りやすい。
var re = /\b/g; // 単語境界にマッチする、幅0のメタ文字。
var str = "012 456 89A";
re.lastIndex = 0;
for(var i = 0; i !== 5; ++i) {
alert("("+ re.exec(str).index +","+ re.lastIndex +")");
// IE7: (0,1) (3,4) (4,5) (7,8) (8,9) ...
// Fx2: (0,0) (0,0) (0,0) (0,0) (0,0) ...
}
空文字列にマッチしていれば(IE7でスキップされるマッチがでてくる) exec()の前後で lastIndexの値が変わっていなければ(Fx2でのマッチ回数が IE7より増える) indexと lastIndexが同じならば lastIndexを 1インクリメント、としておくとどちらでも間違いが起こらない。
var re = /\b/g;
var str = "012 456 89A";
re.lastIndex = 0;
for(var i = 0; i !== 5; ++i) {
var index = re.exec(str).index;
alert("("+ index +","+ re.lastIndex +")");
// IE7: (0,1) (3,4) (4,5) (7,8) (8,9) ...
// Fx2: (0,0) (3,3) (4,4) (7,7) (8,8) ...
if(index === re.lastIndex) {
++re.lastIndex;
}
}
ループで
if(index === re.lastIndex) {
++re.lastIndex;
}
なんて分岐を増やすより、文字列末尾にマッチする /$/ を例外として*、正規表現から空文字列にマッチする可能性を排除する方が良さそう。
* /$/.exec("str") の後の lastIndexプロパティは IE7、Fx2とも、最後の文字の次を指す。
2008年02月15日 (金) [かな変換] F6にかえてCtrl+U。[カナ変換] F7にかえてCtrl+I。[部分確定]↓にかえてCtrl+N。[辞書検索/辞書ページ送り] End。[電子辞典切替メニュー] Ctrl+End。
♪ [javascript]Re: Javascriptのstring型とboolean型、oneOfメソッド他 (agenda)
コメント欄がないのでここでひっそりつっこんでおきます。
それは valueOf()で
Stringと Boolean(と Numberと Date)だけこのように比較方法を === から == にしたりする必要はなくて、
String.prototype.equals = Boolean.prototype.equals = function(arg){
return this == arg;
};
こう。
Object.prototype.equals = function(that) {
return this.valueOf() === that.valueOf();
}
これでオブジェクトに関しては同一性をチェックし、プリミティブでは値が等しいかどうかをチェックする。
ところで、配列の場合、
valueOf メソッドの動作は、オブジェクトの種類に応じて異なります
配列の要素は、カンマによって連結される文字列に変換されます。Array.toString メソッドや Array.join メソッドと同じように動作します。
Microsoft JScript 5.5 リファレンス (chm)
と書かれていて同一性のチェックができなさそうに思えるけど、JScript5.7、Firefox(javascript1.5)ともにチェックできていた。
追記
Array.prototype.valueOf() は String、Boolean、Number、Dateのそれと違って特別に用意されてはいなかった。
参照: 15.4 Array オブジェクト (Array Objects)
ということは Object.prototype.valueOf()が呼ばれるはずで、これは thisを返す。
var a = [1]; alert(a.valueOf() === a); // true
JScript5.5のいいかげんなリファレンスを書いた人、出てきなさい。(はじめての言語だった JScriptと HSPのヘルプには、変数の概念から始まる丁寧な説明を受けました。大変感謝しています)
2008年02月12日 (火) エクスプローラがメモリを放さない。プライベートワーキングセットは 14MBでも、Vistaより前のタスクマネージャが表示していた数字では 215MBになる。仮想メモリ不足ってメッセージが何度も出るんですけどー。
最終更新: 2010-03-21T03:27+0900
♪ [javascript][SHJS] JSLint <http://www.jslint.com>
SHJSの sh_main.jsを高速化したことを以前書いた。(20080204p01)
対応ブラウザ
SHJSのページには動作を確認したブラウザとして以下が挙げられている。
- Firefox 2
- Internet Explorer 6
- Internet Explorer 7
- Opera 9
- Safari 3
sh_main.jsの修正版は Firefox2と IE7と Opera9で正しく動作することの確認と速度の比較を行っている。
IE6での確認は IE7から戻すのが面倒なので省略する。
Sarari3は Vistaで動くものがダウンロードできるので確認してみたところ動いた。(表示も正常)
いじったことで対応ブラウザが減っていなくて良かった。(IE6は?)
JSLint
SHJSの作者は Code Conventions for the JavaScript Programming Language や jslint: The JavaScript Verifier かそれに類似した文書を読んでいるに違いない。(これらのページを今日発見した)
というのも、sh_main.jsを JSLintでチェックしてみたが、こういうエラーしか出なかった。
Error: Implied global: document 362, sh_languages 347, window 332
このエラーは JSLint向けにコメントを埋め込めば取り除けるものだし、そうしないと不可避だともいえるもの。
さてさて、自分がいじったことでどれだけお行儀の悪いスタイルが混入したのでしょうか
Error:
Implied global: document 207 360, sh_languages 332, window 329
Problem at line 73 character 48: Use the array literal notation [].
matchCaches = language.matchCaches = new Array(language.length);
Problem at line 86 character 17: 'i' is already defined.
for(var i = matchCaches.length-1; i !== -1; --i) {
Problem at line 97 character 22: 'i' is already defined.
for (var i = state.length-1; i !== -1; --i) {
Problem at line 110 character 17: 'i' is already defined.
var i = (pair[0] & 0x3F);
Problem at line 280 character 15: Use '!==' to compare with '0'.
while(0 != this._currentStyles.length) {
Problem at line 389 character 14: 'node' is already defined.
var node = this.free_;
いいわけ
- ローカル変数の再宣言に関するものは全て forループで初期化される変数が原因。(i と node)
「var array = new Array(length);」を「var array = []; array.length = length;」や「var array = Array.prototype.slice.call({length:length}, 0);」 と書き換えることは拒否する。
(new Array(length)が一番簡潔で自然な書き方)
(JavaScript 1.7の配列内包に書き換えるのには吝かでない)
- != 0 の代わりに !== 0 と書け? 書き換えましたm( __ __ )m。
(一つを除いて) 無視できる警告*ばかりで良かった。
* 無視したら警告の意味がない。forループの変数なんて(古い VC使い以外には)スコープの誤解を招きやすいという理由で、避けなければいけないものの筆頭ともいえる。
2008年02月08日 (金) 寝ているすきに腕まくらをされに来ていたにゃんこ。これだから冬は(≧∀≦)
♪ [javascript] Arrayと Stringの故意に汎用的なメソッドたち (1)
Under Translation of ECMA-262 3rd Edition を読んでいて見つけた「故意にに汎用的である」と書かれたメソッド群。Arrayと Stringのほとんどのメソッドが該当する。
Firefoxが Array.prototype.methodなどを Array.methodからも参照できるようにする(している)のも 仕様が汎用的で再利用が可能になっているからだろう。
それら汎用的なメソッドを使い回してやるために、その動作を javascriptのコードで表してみる。
Array.prototype.concat([item1[, item2[, ...]]])
function() {
var array = [];
var array_index = 0;
var item = this;
var arg_index = 0;
do {
if(item instanceof Array) { // (1)
var item_index = 0;
while(item_index !== item.length) {
if(item_index in item) {
array[array_index++] = item[item_index++];
} else {
++array_index; ++item_index; // (2)
}
}
} else {
array[array_index++] = item;
}
} while(arg_index !== arguments.length &&
(item = arguments[arg_index++] || true)
);
array.length = array_length;
return array;
}
- thisと引数は Arrayであるかどうかをチェックされ、扱いが変わる。(1)
- 新しい配列にコピーするときに、(Arrayである) thisや引数の疎な部分が省略されることはない。(2)
- thisが Arrayでない場合、単に戻り配列の "0" プロパティに thisオブジェクトが入っているというだけである。(余計な引数なしで呼び出して、Arrayでなければ配列化、という使い方ができる。うれしいか?)
Array.prototype.join(separator)
function(separator) {
var length = this.length>>>0; // (1)-1
if(typeof(separator) === "undefined") {
separator = ",";
}
separator = ToString(separator);
if(length === 0) {
return "";
}
var result;
var index = 0;
var item = this[index++];
item = (item == null) ? "" : ToString(item);
result = item;
while(index !== length) { // (1)-2
item = this[index++];
item = (item == null) ? "" : ToString(item);
result += separator + item;
}
return result;
}
// argが数値の場合は厳密には違うかも。
// 以後もたびたび登場する予定。
function ToString(arg) {
return ""+arg.valueOf();
}
- 0 から数値化された lengthプロパティの値までを処理する。(1)
- 戻り値は必ず文字列であり、this.length-1 個のセパレータを必ず含む。
- thisが Arrayでない場合、例えば Array.prototype.join.call({length:10+1}, " ") で長さが 10 のスペースを得ることが期待される。
♪ [javascript] Arrayと Stringの故意に汎用的なメソッドたち (2)
Array.prototype.pop()
function() {
var length = this.length>>>0;
if(length === 0) {
this.length = length; // (1)-1
return; // undefined
}
length -= 1;
var result = this[length];
delete this[length];
this.length = length; // (1)-2
return result;
}
- (数値化された) this.lengthを 1つデクリメントしたプロパティを削除し、その値を返す。
- pop()を呼び出すと副作用で lengthプロパティが数値になる。(1)
Array.prototype.push([item1[, item2[, ...]]])
function() {
var length = this.length>>>0;
for(var i = 0; i < arguments.length; ++i) {
this[length++] = arguments[i];
}
this.length = length; // (1)
return length;
}
- (数値化された) this.lengthをインクリメントしながら引数をプロパティに設定していく。
- push()を呼び出すと副作用で lengthプロパティが必ず数値になる。(1)
♪ [javascript] Arrayと Stringの故意に汎用的なメソッドたち (3)
Array.prototype.reverse()
function() {
var length = this.length>>>0;
var mid = Math.floor(length/2);
for(var p = 0; p !== mid; ++p) {
var q = length-p-1;
var P = this[p], Q = this[q];
if(!(q in this)) {
delete[p];
} else {
this[p] = Q;
}
if(!(p in this)) {
delete[q];
} else {
this[q] = P;
}
}
return this;
}
- 0 から数値化された lengthプロパティの値までを処理する。
- reverse呼び出し前後でプロパティ(疎な要素など)が増えたり減ったりはしない。
Array.prototype.sort(comparefn)
sort()については、this.length>>>0 が用いられることと、thisを変更して thisを返すことだけを書いておいて、i, j要素を比較する手順について。
function compare(i, j) {
// (A) 存在しない要素を最後尾へ。
if(!(i in this)) {
if(!(j in this)) {
return +0; // (1)
} else {
return 1;
}
} else if(!(j in this)) {
return -1;
}
var I = this[i], J = this[j];
// (B) undefinedな要素を後ろへ。
if(typeof(I) === "undefined") {
if(typeof(J) === "undefined") {
return +0; // (1)
} else {
return 1;
}
} else if(typeof(J) === "undefined") {
return -1;
}
// (C) ユーザー比較関数
if(typeof(comparefn) !== "undefined") {
return comparefn(I, J);
}
// (D) デフォルト比較方法 (文字列化して昇順)
I = ToString(I), J = ToSTring(J);
if(I < J) {
return -1;
} else if(I > J) {
return 1;
}
return +0;
}
- デフォルトの比較関数はやっぱり要素を文字列化していた。(20080207p01。数値配列を期待通りにソートすることはできない)
- +0 と書いてみたが、スクリプトで +0 と -0 を区別することはできない。(1)
♪ [javascript] Arrayと Stringの故意に汎用的なメソッドたち (4)
Array.prototype.shift()
function() {
var length = this.length>>>0;
if(length === 0) {
this.length = length; // (1)
return; // undefined
}
var result = this[0];
// ひとつずつ前へスライド
for(var k = 1; k !== length; ++k) {
if(k in this) {
this[k-1] = this[k];
} else {
delete this[k-1];
}
}
delete this[length-1];
this.length = length-1;
return result;
}
- 0 から数値化された lengthプロパティの値までを処理する。
- shift()を呼び出すと副作用で lengthプロパティが必ず数値になる。(1)
Array.prototype.unshift([item1[, item2[, ...]]])
function() {
var length = this.length>>>0;
// 要素を引数の数だけ後ろへシフト。
for(var k = length; k !== 0; --k) {
var j = k-1;
if(j in this) {
this[j + arguments.length] = this[j];
} else {
delete this[j + arguments.length];
}
}
// 先頭に引数をコピー
for(var k = 0; k !== arguments.length; ++k) {
this[k] = arguments[k];
}
this.length = length + arguments.length; // (1)
return this.length;
}
- 0 から数値化された lengthプロパティの値までを処理する。
- unshift()を呼び出すと副作用で lengthプロパティが必ず数値になる。(1)
♪ [javascript] Arrayと Stringの故意に汎用的なメソッドたち (5)
- Arrayと Stringの故意に汎用的なメソッドたち (1)
- Arrayと Stringの故意に汎用的なメソッドたち (2)
- Arrayと Stringの故意に汎用的なメソッドたち (3)
- Arrayと Stringの故意に汎用的なメソッドたち (4)
Array.prototype.slice(start, end)
function(start, end) {
var array = [];
var array_index = 0;
var length = this.length>>>0;
start = ToInteger(start);
start = (start < 0) ? Math.max(length+start, 0) : Math.min(start, length);
end = (typeof(end) === "undefined") ? length : ToInteger(end);
end = (end < 0) ? Math.max(length+end, 0) : Math.min(end, length);
for(var k = start; k < end; ++k) {
if(k in this) {
array[array_index++] = this[k];
} else {
++array_index; // (1)
}
}
array.length = array_index;
return array;
}
function ToInteger(x) {
x = +x;
if(isNaN(x)) {
return +0; // (2)
}
if(x === 0 || !isFinite(x)) {
return x;
}
// 0 に近づける。(小数点以下を切り捨てる)
return (0 <= x) ? Math.floor(x) : Math.ceil(x);
}
- 数値化された this.lengthと引数 start, end を元に範囲を決定し処理する。
- startと endには負数も使用可。
- thisの存在しない要素がコピーされることはないが、無視されるわけではない。(1)
- +0 と書いたがスクリプトが +0 と -0 を区別することはできない。(2)
Array.prototype.splice(start, deleteCount[, item1[, item2[, ...]]])
function(start, deleteCount) {
var array = [];
var length = this.length>>>0;
start = ToInteger(start);
start = (start < 0) ? Math.max(length+start, 0) : Math.min(start, le deleteCount = ToInteger(deleteCount);
deleteCount = Math.min(Math.max(deleteCount, 0), length-start);
// 取り出す要素をコピー。(まだ削除はしない)
for(var k = 0; k !== deleteCount; ++k) {
var l = start+k;
if(l in this) {
array[k] = this[l];
}
}
// (A) 要素を後ろへずらして空きを作る
// (後で上書きされてしまう要素までずらしてない?)
if(deleteCount < arguments.length) {
for(var k = length-deleteCount; k !== start; --k) {
var l = k + deleteCount -1;
var m = k + arguments.length -1;
if(l in this) {
this[m] = this[l];
} else {
delete this[m];
}
}
// (B) 要素を前へ詰めて、空きを新要素と同じ数にする
} else if(arguments.length < deleteCount) {
for(var k = start; k !== length-deleteCount; ++k) {
var l = k + arguments.length;
var m = k + deleteCount;
if(m in this) {
this[l] = this[m];
} else {
delete this[l];
}
}
// (なぜ逆順で削除する?)
for(var k = length; k !== length-deleteCount+arguments.length; --k) {
delete this[k-1];
}
}
// 追加する要素で thisを上書き
if(arguments.length === deleteCount) {
for(var k = 0; k !== arguments.length; ++k) {
this[start+k] = arguments[k];
}
}
this.length = length - deleteCount + arguments.length;
return array;
}
- 数値化された this.lengthと引数 start を元に範囲を決定し処理する。
- startには負数も使用可。
- splice()を呼び出すと副作用で lengthプロパティが必ず数値になる。
- splice()は仕事を抱え込みすぎ。
♪ [javascript] Arrayと Stringの故意に汎用的なメソッドたち (6)
- Arrayと Stringの故意に汎用的なメソッドたち (1)
- Arrayと Stringの故意に汎用的なメソッドたち (2)
- Arrayと Stringの故意に汎用的なメソッドたち (3)
- Arrayと Stringの故意に汎用的なメソッドたち (4)
- Arrayと Stringの故意に汎用的なメソッドたち (5)
パターンがわかってきた。
Arrayのビルトインメソッドは concat()を除いて、this.lengthを 32-bit unsigned int(UINT32)に変換したものを処理範囲の上限として利用する。(下限はもちろん 0)
- concat()は thisや引数が Arrayかどうかで処理を変えるから、(利用するときは) this.lengthを直接用いる。
自身の長さを変更するメソッド(pop(), push(), shift(), unshift(), splice())を呼び出すと lengthプロパティは必ず UINT32に変更される。
- 自身の長さを変更しない reverse(), sort()や、自身を変更しない concat(), join(), slice()を呼び出しても lengthは変化しない。
あんまり使えない。
Arrayの多くのメソッドは自己破壊的で、Stringに適用することができない。
Firefox(JavaScript1.5?)では適用すると Array.prototype.method.call(string) is read-onlyという警告がいくつも出る。
一度の呼び出しでいくつも出ることから read-onlyなのはメソッドではなく、自己破壊的な Array.prototype.method()を適用された stringだと思われる。
警告が出るだけで、戻り値は得られるので pop()で末尾の文字、shift()で先頭の文字が得られる。
unshift()、push()の返す数値は使えない。(その長さを持った文字列は存在しないので)
reverse(), sort()は全く役に立たない。役に立つ値を返さないし、並べ替えには失敗しているから。
slice()は String.prototypeに同名のメソッドがすでに存在する。
splice()がちょっと面白く、splice(startと deleteCount) の引数はちょうど String.prototype.substr(start, length)と対応するが、返ってくるのが substr()->"文字列" なのに対し、splice()->["文","字","列"] となる。
string.split("")の代わりに Array.prototype.splice.call(string, 0)としてみるのはいかが? (警告が出る上に IE7では使えませんが)
そもそも IEの JScript5.7では文字列に添え字を使ってアクセスできないので Arrayのメソッドを適用しても意味がない。
Stringではなく、配列のようなオブジェクト(コレクションとか argumentsとか)に適用するのが正解か。
concat()と join()は広く使える。
配列化1 (びみょ〜)
// unknown_objectが配列なら unknown_objectのコピー、 // それ以外なら unknown_objectを唯一の要素とする配列が返る。 var array = Array.prototype.concat.call(unknown_object);
配列化2 (IEでは使えない)
// lengthプロパティと [] での要素アクセスが可能な、
// 配列っぽいオブジェクト(NodeListとか argumentsとか)を配列化。
var array = Array.prototype.slice.call(document.getElementsByTagName("pre"), 0);
繰り返し文字列 (けっこう使える)
// " " が得られます。
var softtab = Array.prototype.join.call({length:8+1}, " ");
// softtabを使ったレベル3のインデントが得られます。
var indent = new Array(3+1).join(softtab); // prototypeいらねー
二番目の書き方を使うなら Arrayのビルトインメソッドを他のオブジェクトに使い回すという趣旨が……。
♪ [javascript] Arrayと Stringの故意に汎用的なメソッドたち (7)
- Arrayと Stringの故意に汎用的なメソッドたち (1)
- Arrayと Stringの故意に汎用的なメソッドたち (2)
- Arrayと Stringの故意に汎用的なメソッドたち (3)
- Arrayと Stringの故意に汎用的なメソッドたち (4)
- Arrayと Stringの故意に汎用的なメソッドたち (5)
- Arrayと Stringの故意に汎用的なメソッドたち (6)
今回から String.prototypeのメソッド。Stringは自己破壊的なメソッドを持っていないから、Arrayのビルトインメソッドと違って適用範囲が広いことを期待している。
……と思ったが、Stringのビルトインメソッドはどれも事前に ToString(this)を呼んでしまう。(ToString()については (1))
indexOfで配列の探索ができるんじゃないかと期待していたが無理だった。がっかり。
これにて終了。
split()に渡す正規表現のサブマッチに特別な意味があるとか、split()はグローバルフラグを無視するとか、グローバルフラグの立った正規表現で exec(string)を呼んで空文字列にマッチしたときはこちらで lastIndexプロパティを 1増やさないといけないとか、もやもやしてたことが Under Translation of ECMA-262 3rd Editionにはいろいろ書いてありました。訳者に感謝。
2008年02月07日 (木)
♪ [javascript] 普通に使ってて驚いた JavaScriptのヘンなところ
switch-caseのラベル部分に何でも書ける*という変態的な部分は置いておいて、1/2が 0.5になるのと同じ類の話。
[1, 5, 10].sort()
返るのは [1, 10, 5]。どうも文字列としてソートされている。数字だけの配列だ(と自分が知っている)からって無駄な期待をしてはいけない。
for(var i in [1, 5, 10]) { alert(typeof i) }
stringと表示される。i に入るのが配列の要素 1, 5, 10 ではなく添え字(key)だというだけで意外だが、さらに意表をついてそれが数字でもなく、"0", "1", "2" 。i+1 としても隣の要素にはアクセスできない。array[1] = 5; と数字の添え字で代入した後でも同じだった。
for-in ループは遅いと評判だったので使っておらず、最近まで知らなかった。
ついでにいうと for-inとは別の in 演算子の存在も、つい最近まで知らなかった。(SHJSのソースを読んで発見した)
グローバル変数の存在確認方法も SHJSを読んで知った。今までは typeof(global_var) == "undefined" とやっていた。これは存在確認とは微妙に意味が違う。
deleteできるグローバル変数とできないグローバル変数については amachangのブログを読んで知った。
オブジェクトのプロパティ名、連想配列のキー、配列の添え字、ぜんぶ同じぜんぶ文字列。
- プロパティ名はすべて文字列化されてからオブジェクトに渡されること
- 配列は特殊な lengthプロパティを持った Object
ということを知っていれば for-inループで文字列が渡されても驚くことはない。(じゃあなぜ驚いた)
var object = {};
alert(""+ (1==="1")); // false
o[1] = 1;
o["1"] = "1";
alert(""+ (o[1]===o["1"])); // true
var a = [1,2,3];
var b = [1,2,3];
alert(""+ (a===b)); // false
o[a] = a;
o[b] = b;
alert(""+ (o[a]===o[b])); // true
var s = "1,2,3";
alert(""+ (a===s)); // false
o[s] = s;
alert(""+ (o[a]===o[s])); // true
* http://arton.no-ip.info/diary/20061224.html#p02
2008年02月06日 (水) パスワードを間違えたときに Caps Lockがオンと教えてくれる Vista。
♪ [javascript] 継承。prototypeへの代入
こんなやりとりがあった。
dankogaiの指摘の一つ、「MyObject.prototype = { /* ... */ }は避けるべし」について。
MyBox.prototype = Box.prototype; // ここで継承しているのに
MyBox.prototype = { // ここで台無し
speed:8
};
指摘には同意するが、上の例だと親の Boxにも MyBoxと共通のクラス変数 speedが追加されている。
amachangの反論にあるように、継承するなら次の書き方の方が優れている。
MyBox.prototype = new Box; // new Box()と同じ
ところで、amachangはこう続けている。これがプロトタイプ継承の正しい形式であり
MyBox.prototype = {};
MyBox.prototype = new Object;
指摘を受けた上段の書き方は下段のシンタックスシュガーなので両方とも Objectからの正しい継承方法である。このことがわかっていれば、他から継承しておきながら Objectからも継承して台無しにするような間違いは犯さない。(だから必要に応じて違う書き方をすれば良いし、必要がなければ .prototype={}と書いても良い)。
でも違う理由で MyObject.prototype = {}; という書き方は避けている。 理由は一つで
MyObject = function(){};
MyObject.prototype = {/* MyObjectの定義 */};
alert(new MyObject().constructor); // function Object(){ [natiive code] } と表示
constructorプロパティが MyObjectではなくなってしまっている。これは MyObject.prototype = new MyParent; としたときも同じで constructorは MyParentになる。
constructorプロパティだけを気にするなら
MyObject.prototype = { constructor:MyObject.prototype.constructor };
というように明示的にコピーすればごまかせるが、一時しのぎ感がぷんぷんしている。(constructor以外のプロパティが追加されたらその都度書き換えるの?)
だから、継承の仕方で逆につっこまれてしまったが、dankogaiが提示した 3つの方法に自分は同意していて、そのうちの一つ目を自分は使っている。