2017年03月15日 (水)
WSH(JScript)で COBOLアプリケーションのデータファイルを読んで XMLとして書き出して XSLTでソート&HTML化して JavaScriptでフィルタリングして、Firefoxで印刷するなどしていた>20170307, 20170227。フィルタリングは早いうちに特にソートよりも前にしたいのだけど、URLを通して XSLにフィルタリングパラメータを渡す方法がなかったのでしかたなく。パソコンにデータがあるのに手書きでフォームを埋めるとか嫌だよね。フォームごと印刷したれ。■JScriptでやるっていうのは、まあ、.NETがある今は「特にインストールする必要がないっていうのも重要な要素」だとしても意味のない縛りなんだけど、JScript.Netは後付け言語仕様にこれじゃない感があるし、C#はコンパイルが必要だし(他の方法もある?)、PowerShellは実行するまでが面倒くさい>「Windows PowerShell スクリプトを実行する」。それにランタイムは入っていても jsc.exeや csc.exeはないだろう……と思ったけど、例えば C:\Windows\Microsoft.NET\Framework64\v4.0.30319\ にあるのだから、やっぱりどこでも入ってるのかも。今では実行時にコードをあれこれ操作したり作り出したりすることもできるみたいだから、コンパイラのコアもランタイムの一部で、コンパイラはただの UI(ガワ)だったりするだろうか。■データファイルはヘッダ+固定長レコードだった。Shift_JISで読み込むと文字数とバイト数が比例しないし文字コードとバイナリも素直に対応しないので、2バイト単位になるけど Unicodeテキストとして読み込むことでバイナリデータにアクセスできる。こういうときサロゲートペアが2文字扱いになる仕様が重要。ECMAScriptがそうかは知らないけど、よく聞く仕様ではある。■データの型は(桁数を無視すると)3種類だった。Shift_JISの文字列と、Shift_JISの半角数字(※ASCII数字ともいう)と、唯一混ざり込んだバイナリっぽいものが10進1桁を4ビットで表現して最後を 0xC(正符号)でターミネイトした packed decimalだった。これがあるせいで、このバイナリっぽいものがたまたま Shift_JISの先行バイトだったときに、文字数とバイト数の対応や文字コードとバイナリの対応が崩れるせいで、全体を Shift_JISテキストとして読み込んで切り分けることができなかったのだった。■固定長だということや Shift_JISや ASCII文字だということや、16進1桁をそのまま 10進1桁として使用することが、どれもエディタで見てわかることに繋がっていて非常に助かる。可変長だったらヘッダの特定のバイトを読んで長さを確定しないといけないし、テキストデータだからって圧縮されていたら展開しないといけないし、10進3桁(1000通り)を表現するには2進10桁(1024通り)もあれば十分だぜなんて効率を考え出したらバイナリエディタで開いただけで数字が読めたりはしなくなるので。■■■意外に難しい。「4nビットを用いて整数を表現するとき,符号なし固定小数点表示法で表現できる最大値をaとし,BCD(2進化10進符号)で表現できる最大値をbとする。nが大きくなるとa/bはどれに近づくか。」さっきも書いたけど、BCDって言われて10ビットで10進3桁を表現することを考え出すと答えから遠ざかってしまう。■これをダブルクリックしたら入力済みのフォームが表示されるからメニューから印刷したらいいよと一人に説明したら、パソコンに手入力したものを印刷してたのだと思ってたとのこと。そうね、パソコンって使いにくいワープロかもしれないね。
最終更新: 2018-06-09T23:02+0900
♪ [javascript] ビット演算子多めのヘルパーメソッド群
用途はタイトル欄(↑)を参照のこと。JavaScriptのビット演算は事前に整数化が必要なため遅いらしいですよ。
あと、これは JavaScriptではなく JScriptです。関数名でインチキしてるので、って書くまでもなく new ActiveXObject してるのだから明らかだった。
function String.prototype.trim()
{
return this.replace(/^[\s ]+|[\s ]+$/g, "");
}
function String.prototype.atoi(offset, width) // 引数の単位はバイト。Unicodeにマッピングされた ASCIIではなく、UTF-16の符号単位2バイトを2つの ASCII数字として解釈する。符号は非対応。省略したら文字列の端から端まですべてが対象。
{ // 0x30(0),..., 0x39(9)
var Offset = offset != null && 0 <= offset && offset < 2*this.length ? (offset>>>0) : 0;
var Width = width != null && 0 <= width && Offset + width < 2*this.length ? (width>>>0) : 2*this.length - Offset;
if (Width == 0) {
return 0; // NaN もありか?
}
var x = 0, i = (Offset + 1)>>>1, I = (Offset + Width)>>>1;
if (Offset & 1) {
x += (this.charCodeAt(i-1)>>>8) & 0xF;
}
if (x == 0) {
// ありがちな場合のショートカット
while (i < I && this.charCodeAt(i) == 0x3030) {
i += 1;
}
}
for (; i < I; ++i) {
var Ch = this.charCodeAt(i);
x = x * 10 + (Ch & 0xF);
x = x * 10 + ((Ch>>>8) & 0xF);
}
if ((Offset + Width) & 1) {
x = x * 10 + (this.charCodeAt(I) & 0xF);
}
return x;
}
function String.prototype.asPackedSigned(offset, width) // 引数の単位はいずれもパックされた10進1桁(=4bit)。省略したら文字列の端から端まですべてが対象。
{
// assert(0 != this.length);
offset = 0 <= offset ? offset>>>0 : 0;
width = 1 <= width && width <= 4*this.length-offset ? width>>>0 : 4*this.length-offset;
var decstr = "";
for (var i = offset>>>2; i < (offset+width)/4; ++i) {
var LLHH = this.charCodeAt(i);
decstr += String.fromCharCode((LLHH>>>4)&0xF|0x30, LLHH&0xF|0x30, (LLHH>>>12)&0xF|0x30, (LLHH>>>8)&0xF|0x30);
}
offset &= 3;
var Sign = {
"<"/*0x3C*/:+1, "3"/*0x33*/:+1,
"="/*0x3D*/:-1, "7"/*0x37*/:-1
}[decstr.charAt(offset+width-1)] || 1;
return Sign * decstr.substr(offset, width-1); // decstrが 0-9以外の文字(:;<=>?)を含んでると NaN。
}
function String.prototype.endWithSJISLead()
{
if (! this) {
return false;
}
var Ch = this.charCodeAt(this.length-1) >>> 8;
return 0x81 <= Ch && Ch <= 0x9F || 0xE0 <= Ch && Ch <= 0xEF;
}
function String.prototype.asSJIS(Mask) // 先頭1バイトを捨てる(Mask=0xFF00), 末尾1バイトを捨てる(Mask=0x00FF), 両方捨てる(Mask=0x0000), そのまま(Mask=0xFFFF,null,undefined)
{
var Share = {
old: arguments.callee,
path: FSO().BuildPath(
FSO().GetSpecialFolder(2/*TemporaryFolder*/),
FSO().GetTempName()
),
temp: null
};
Share.temp = {
fou: FSO().OpenTextFile(Share.path, 2/*ForWriting*/, true/*creat*/, -1/*Unicode*/),
fin: FSO().OpenTextFile(Share.path, 1/*ForReading*/, true/*creat*/, 0/*Shift_JIS*/)
};
Share.temp.fou.Write(""); // write BOM
Share.temp.fin.ReadAll(); // drop BOM
var asSJIS = function(Mask) {
if (! this) {
return "";
}
if (Mask == null) { // 速度面で意味のあるショートカット。
Share.temp.fou.Write(this);
return Share.temp.fin.ReadAll();
} else {
var s = this;
s = String.fromCharCode(s.charCodeAt(0)&(Mask|0xFF00)) + s.slice(1); // s.length == 1 のときを忘れないように。
s = s.slice(0,-1) + String.fromCharCode(s.charCodeAt(s.length-1)&(Mask|0x00FF)); // s.length == 1 のときを忘れないように。
Share.temp.fou.Write(s);
s = Share.temp.fin.ReadAll();
return s.slice(!(Mask&0x00FF), s.length-!(Mask&0xFF00)); // 後ろから2バイト目が Shift_JISの先行バイトだった場合、捨てるべき1バイトと結びついて1文字になってるだろうから捨てすぎてしまうだろうね。
}
};
asSJIS.clean = function() {
Share.temp.fou.Close();
Share.temp.fin.Close();
FSO().DeleteFile(Share.path);
String.prototype.asSJIS = Share.old;
};
return (String.prototype.asSJIS = asSJIS).call(this, Mask);
// 循環参照とかありそうでやばくない? 長く実行するわけじゃないけども。
}
function String.prototype.asSJIS.clean()
{
/*
asSJISを呼び出したのと同じ回数だけ
ファイルを作成して、削除するのなら、cleanメソッドはいらない。
一時ファイルが蓄積するのを気にしないのなら、cleanメソッドはいらない。
どちらも気になるのでテキトーなタイミングで cleanメソッドを呼んで
一時ファイルを削除する。
その次の asSJIS呼び出しでまた一時ファイルが作成される。
この空のメソッドは上記のコメントのために存在しているのではなく、
一度も asSJISを呼び出さないうちに asSJIS.clean()を呼び出しても
エラーにならないように置かれている。
*/
}
function Date.prototype.format(Fmt)
{
var Map = {
"%": "%"
,Y : ""+this.getFullYear()
,m : ("0"+(this.getMonth()+1)).slice(-2)
,d : ("0"+this.getDate()).slice(-2)
,H : ("0"+this.getHours()).slice(-2)
,M : ("0"+this.getMinutes()).slice(-2)
,S : ("0"+this.getSeconds()).slice(-2)
};
return Fmt.replace(/%(.)/g, function($0, $1) {
return Map[$1] || $0;
});
}
function Date.prototype.isOlderThan(Other)
{
return this.valueOf() < Other.valueOf();
}
function FSO()
{
var FSO_ = new ActiveXObject("Scripting.FileSystemObject");
return (FSO = function() { return FSO_; })();
}
JScriptの function Declarationはたぶん事前実行される点が違うだけで function Expressionのシンタックスシュガーなんだよね。だからドットでつないだ関数名でプロパティ代入ができる。便利。関数の順番を気にしないで済む。
@2018-06-09 バグ修正
50行目、String.prototype.asPackedSigned
- }[decstr.charAt(width-1)] || 1; + }[decstr.charAt(offset+width-1)] || 1;
offset が4の倍数でない時に間違った場所を読んでいた。ときどき個数としてありえない負の数が現れて発覚した。2万数千件に対して10数件の割合だったので2か月以上気がつかなかった。無念。
最終更新: 2017-03-17T03:48+0900
♪ [javascript] ビット演算に伴う整数化。符号付き整数化。符号無し整数化。
今まで意識してなかったけど、ビット演算を使って数値を整数化するとき、その結果が符号付き整数か符号無し整数かは重要。ビット演算の前準備としての整数化では32ビット幅への切り詰めが行われるから、すごく大きな正数が切り詰められた結果の32ビット目がたまたま 1 だったときに負数が返ってきたりする。それに驚きたくないなら符号無しのビット演算を使う。
999999999999|0 //=> -727379969 999999999999>>>0 //=> 3567587327 999999999999>>>0|0 //=> -727379969
2016年10月20日 (木)
最終更新: 2016-11-21T21:59+0900
♪ [javascript] マピオンからグーグルマップへ(ブックマークレット)
try {
var {y:lat, x:lng} = Map.getCenterLatLng(),
mag = Map.getZoomLevel();
open(`https://www.google.co.jp/maps/@${lat},${lng},${mag}z`);
} catch(e) {}
javascript:try{var{y:lat,x:lng}=Map.getCenterLatLng(),mag=Map.getZoomLevel();open(`https://www.google.co.jp/maps/@${lat},${lng},${mag}z`);}catch(e){}
- 最近目にした新機能(分割代入とテンプレート文字列)を無駄に使ってみた(ただの便利機能は無駄です)。
以前に感じた通り、分割代入の構文は左辺の key と value が入れ違ってるとしか思えなくて(※)、案の定書き間違えたのだった。
※ keyは識別子(または文字列)で valueは expressionなのだから、keyで新しい名前を導入し、valueを特別な文脈で評価することで右辺のプロパティが参照できると考える(でも間違い)。これは JavaScriptの「平板」化ですよ>20091206p02.04。言語設計者は神だけど、現実世界の神がアドホックな物理法則を定めていたら、こちらは気が狂います。
- マピオンは履歴エントリの随時書き換えをしないので location.href から表示してる最新の座標を取得できない。便利ツール>地図URL のコードを参考にした。
いきさつ
マピオンはリンクをたどって特定の番地を表示できるのでメインで使用してる。検索ベースだと存在しない番地に対してテキトーな場所を表示されてもわからない一方、リンクをたどる方式ではそれを承知したうえで近くの番地から推測することができる。
とはいえ航空写真やストリートビューで実地の景色も確認したいので、マピオンからグーグルマップへ飛ぶ。
2015年05月29日 (金)
最終更新: 2015-05-31T16:39+0900
♪ [javascript] 1時間以内に解けなければプログラマ失格となってしまう5つの問題の5番目
ファイル作成日時をみると1時間半前だった。不合格。
繰り返しのしかたを決めるまでに時間がかかりすぎた。再帰、ツリー、順列。再帰関数は共有して進めたり戻したりする変数とローカルな変数を整理しきれなくてあきらめた。深さ優先探索が書けないとかやばいね。三進数を使った順列(※下の解法)はちょっとだけ違う似たような計算を何度も繰り返すのがもったいない。カウンタの上限がすぐ来てスケールもしないし。
-1+2-3+4+5+6+78+9 は答えに数えないみたいだけどそのまま。
var CScript = WScript; // cscript.exeでの実行をおすすめします。
var Op = [
function op_shift(o, x) {
o.buf = o.buf*10 + o.buf/Math.abs(o.buf)*x;
o.expr += x;
},
function op_plus(o, x) {
o.sum += o.buf;
o.buf = x;
o.expr += "+" + x;
},
function op_minus(o, x) {
o.sum += o.buf;
o.buf = -x;
o.expr += "-" + x;
}
];
for (var op9seq = Math.pow(3,9)-1; 0 <= op9seq; --op9seq) {
var o = {sum:0, buf:0, expr:""}, q = op9seq, r;
for (var x = 1; x <= 9; ++x) {
r = q % 3;
q = (q-r) / 3;
Op[r](o, x);
}
o.sum += o.buf;
if (o.sum == 100) {
CScript.Echo(o.expr);
}
}
ところでこちらの、「Kazuho's Weblog: C言語で「1時間以内に解けなければプログラマ失格となってしまう5つの問題が話題に」の5問目を解いてみた」、変数 n の使い方がわかりません(わからないから自分は sumの他にもうひとつ bufという変数が必要になった)。ブコメに小町算とあるのだけど、これがヒント?
2013年11月01日 (金) 「Kindleストアから大手アダルトコミックが大量削除 - 電パブログ」■ちんちんかもかもって辞書に載ってる単語だったりする。知らねー。■紙の本でも独善によって一部をなき物にするアマゾンだけど Kindleではそれよりさらに厳しい基準でのぞんでいると。TSUTAYAと一緒。消えろ(※強勢はなし。付けると願い事みたいになってしまう。平板に、興味のないゴミカスに退場を許可するみたいに発音する)。■ところで、Reader Storeでも Kinoppyでも最初から取り扱いがなかったりするわけですね。終わってるやん。(直販してる)フランス書院が正解。ISBNのついた本を100%カバーすることを目標に掲げた電書書店はないのか?■こんなんのまま紙が廃れたら悲劇だなあ。分を弁えへん私企業に所有させていいもんやないで。こんなところに利益をくれてやるのは同時に人質を差し出すようなもの。あとで後悔することになる。■■■@2013-11-18「あとで後悔」が二重表現の例として挙げられていて、そうかと思って書き直そうとしたがどうもしっくりしない。これは、未来のある時点において後悔することを動詞(の付属部)だけでなく副詞も使って示しているのであって、つまり、後悔の対象が必ずその時点における過去の事象であることと、後悔するのがいつであるかは別物なので二重表現にはならないのではないだろうか。■「今後悔してる」に対する「あとで後悔する(ことになる)」は不自然じゃないと思う。
最終更新: 2016-11-18T12:59+0900
♪ [tDiary][Firefox][正規表現][javascript] Firefoxが句点を行頭に送ってしまうのがあまりに目障りでもう耐えられないので~正規表現(Rubyに劣るECMAScript仕様)~禁則処理(IE完璧。Firefox/Safariに指導)~両端揃え(IE完璧。Firefox満足*。Safariを補完)~画像とCSSのDPI~字詰め
tDiaryのプラグインとして今回追加したのは auto_nobrの部分だけ。
add_title_proc {|date, title|
auto_nobr = lambda{|src|
return src.gsub(/[^{}\[\]()*#"!'`=:|][、。」』!?!?)]+|[「『(]+[^{}\[\]()*#"!'`=:|]/u){ %{{{'<nobr>'}}#{$&}{{'</nobr>'}}} }
}
inline_or_nil = lambda{|src|
lines = src.split(/\r?\n/)
return nil if 1 < lines.length
html = WikiSection.new(auto_nobr.call lines.first).body_to_html
return html.gsub!(/\A\s*<p>/, '') && html.gsub!(/<\/p>\s*\z/, '')
}
if title.index('<')
title.sub(/<span class="title">([^<>]+)<\/span>/){|_0|
html = inline_or_nil.call(CGI.unescapeHTML $1)
html ? %/<span class="title">#{html}<\/span>/ : _0
}
else
inline_or_nil.call(CGI.unescapeHTML title) or title
end rescue title
}
一応。Firefoxの挙動は word-break: break-allが指定された結果である。であるが、だからといって行頭の句点、句点だけの行(ぽつーん)はありえないだろうと思うのです。
やっつけ仕様
1.標準に存在しない<nobr>タグの使用
かといって空白が関係するわけではないから white-space:nowrap とか使えないし、使えたとして FONTタグを <span style="font:~"></span>に置き換えるようなことに意味を見いだせたのはそれが 2000年頃のことだったからだし、段落全体を一行で表示したいわけでもないので Pタグに対してルールを追加することもできず、代替案が見つからない。
2.テキトーなテキスト置換
HikiDocで意味を持ってそうな記号を避けつつ句点+1文字を<nobr>で囲ってる。整形式でないというエラーが出るパターンがまだ残ってるかもしれない。footnoteプラグインとかわりと文章を渡すから危険だ。
3.対象がタイトル欄だけ
全体を対象にするなら JavaScriptでやる。でもテキストを対象にしつつタグをインジェクトする方法がわからなかった。
マッチしたテキストノードをドキュメントフラグメント(テキスト+NOBRエレメント+テキスト)と置き換えればよかったのか?具体的方法が見えたところだが、レイアウトが変わってしまう変更を読み込み完了間際にスクリプトで行うというのはやっぱりよくないかも。フラグメント付きの URLでアクセスしたときターゲットが画面外に逃げてしまいかねない。
4.表示を確認したのは Firefox(23.0.1)と IE9だけ
Operaは独自のレンダリングエンジンを放棄したし、Windows版Safariはアップデートが止まったし、Google Chromeはインストール場所がキモいから(今でもそうかは知らない。当然やめるだろうと予想するほどに、そして一瞬でアンインストールしてしまうほどにキモかったということだ)。
「CSS 3におけるテキストの自動改行と禁則処理の定義 - builder by ZDNet Japan」
break-all
任意の位置で自動改行を行うが、日本語のテキストでは「line-break:normal」と指定したときと同じようにゆるい禁則処理を行う。
これを期待して待ってたんだけど。
「アポラボログ: Firefox 15 の禁則処理を修正」
この「word-break」というスタイルシートは文の改行の仕方を指定するもので、もともと Internet Explorer 独自の物だったようなのですが、最近になって Firefox もこれを採用したらしいのです。そのため、以前の Firefox では無効化されることを想定してこのスタイルシートが指定されていたと考えられます。
サイト制作者の想定としては IE のみにこのスタイルシートを指定したつもりが、意図せず Firefox でも有効化されてしまい、禁則処理のされない読みづらい記事が発生してしまったということだと思います。おそらく、IE の場合はこのスタイルシートが指定されていても禁則処理には影響がなかったのではないでしょうか。
先行する IEはまとも。後追いの Firefoxはバカ。日本人の貢献が足りないのか?
「Gecko と Webkit の word-break:break-all; ってこれでいいの? « やおよろグッ!」
良くないと思います。
「word-break: break-all; がW3CでOKになってるし|ぼくんちのバックステージ」
余談:Googleの検索仕様変更について
1ヶ月ほど前から、Google検索の左メニューが無くなっちゃいましたねえ。
スクリプトを無効にしてると今でも出てくるんですよ。畳まれたメニューをクリックしなくても大体の選択肢が羅列されてるんですよ。フォールバックが機能してるのをほめる前に、スクリプトを使って使いにくくしてることにあきれる。
@2013-11-02 正規表現パターンについて
auto_nobr処理の中の
/[^{}\[\]()*#"!'`=:|][、。」』!?!?)]+|[「『(]+[^{}\[\]()*#"!'`=:|]/u
というパターンは要するに
HikiDocで特別な意味を持たない1文字+行頭禁則文字、または、行末禁則文字+HikiDocで特別な意味を持たない1文字
という意味なんだけど、HikiDocで~という部分が
文字列を組み合わせて RegExpのコンストラクタに渡すのは、文字列を Functionコンストラクタに渡すこと(evalと同じ)や、文字列から SQLを組み立てるのに似て好きではない。一面でわかりにくくなるのを承知で書き直すとこうなる。
/(?=([「『(]+)?([^{}\[\]()*#"!'`=:|])([、。」』!?!?)]+)?)(?:\1\2|\2\3)/u
前半の先読み部分は次のような意味の1~3個のキャプチャを含む。
(行末禁則文字)?(HikiDocで~)(行頭禁則文字)?
後半の、対象文字列と実際にマッチする部分はキャプチャを参照するだけの単純な二択。
(?:\1\2|\2\3)
かっこによるグループ化がないと先読みが最初の選択肢にしかかからないことに注意。| の結合は一番弱い。
キャプチャや分岐が増えてるがパターンの繰り返しはないし、トリッキーに見えてもひとたび構造がわかると簡単だと思うがどうだろう。
最終的にこの日記で使用するパターンは \3? を付け加えてこうなった。
/(?=([「『(]+)?([^{}\[\]()*#"!'`=:|])([、。」』!?!?)]+)?)(?:\1\2\3?|\2\3)/u
これで、かっこで1文字だけを囲った 『目』みたいなテキストがひとかたまりとして扱われて折り返されることがなくなる。
ひとつ心配なのは、?によって存在しないことにされたキャプチャを参照することが必ずマッチの失敗を意味するのかどうか。参照が空の文字列に展開されるなら必ず成功すると判断されてもしかたがない。たとえそれが NULLと空文字列の混同だとしてもありそうな話ではある。
「禁則処理がおかしい - Ronten」
ここまで書いてから見つけたのがこれ。
word-break: break-all;から、
word-break: normal; word-wrap: break-word;に変更。元々、英数だけの文字がdivをはみ出す現象の防止の為にword-break: break-all; を指定していたが、それだと日本語の句読点が行頭に来てしまうっぽい。
word-break: normal;だけだと、英数だけの文字がはみ出すが、上のように二つ指定すると、日本語も英語も両方うまくいった。
ええええええ。くやしいから本文の方だけ CSSで対応する。
/* chiffon_leafgreen.css 183行目 */
div.day {
word-break: break-all;
word-wrap : break-word;
}
/* に追加して */
div.section {
word-break: normal;
}
での英字折り返しの違い。normalだとスペースでの折り返しが優先される結果、word-break:break-allしたかった目的
#箱の端から端まで文字を満たしたい。
#句読点など1文字程度の段差なら許容できる。
#やりすぎた字間調整(text-justify)は見苦しいからやらない。
が実現できないのだった。はみだすのも嫌だが右端がガタガタでカタマリ感がないのも嫌なのだった。これは word-wrap:break-wordでは補えない。
a ab abc abcd abcde abcdef abcdefg abcdefgh abcdefghi abcdefghij abcdefghijk abcdefghijkl abcdefghijklm abcdefghijklmn abcdefghijklmno abcdefghijklmnop abcdefghijklmnopq abcdefghijklmnopqr abcdefghijklmnopqrs abcdefghijklmnopqrst abcdefghijklmnopqrstu abcdefghijklmnopqrstuv abcdefghijklmnopqrstuvw abcdefghijklmnopqrstuvwx abcdefghijklmnopqrstuvwxy abcdefghijklmnopqrstuvwxyz")
方針は変更せず、タイトルではきっちり右端での折り返しを優先し、本文では禁則処理を優先しよう。そもそもは word-break:break-allで禁則処理が行われるのが本当で、それこそが望みの結果なのに。
@2013-11-04 朝令暮改
「2.テキトーなテキスト置換」が予想以上にプロブレマティックだった。二重ブラケットで囲った URLの中の ? を NOBRタグで囲おうとして URLを破壊し XHTMLを破壊していた。既に書いたように footnoteプラグインに引数として渡す文章に NOBRタグを挿入する問題もある。タイトル欄で footnoteプラグインは使わない(セクション末尾に脚注を挿入しようとしても無理だから)が、同じような問題が続出するということだ。
というわけで、目途をつけておいた JavaScriptでの実装に切り替えた。
// Firefox(ver.15-23現在まで)が word-break:break-allで禁則処理を
// してくれないので NOBRタグで強制的に特定の折り返しを禁止する。
function auto_nobr(textNode)
{
var create_nobr = function(text){
var d = textNode.ownerDocument;
var nobr = d.createElement("nobr");
if (text) {
nobr.appendChild(d.createTextNode(text));
}
return nobr;
};
var m, re = /[「『((]+.[))』」、。!!??]*|.[))』」、。!!??]+/;
while (m = re.exec(textNode.nodeValue)) {
/* assert 0 < match.length in case of infinite loop. */
nobrText = textNode.splitText(m.index);
textNode = nobrText.splitText(m[0].length);
nobrText.parentNode.replaceChild(create_nobr(m[0]), nobrText);
}
return textNode; // the last Node of splitted textNodes.
}
function apply_auto_nobr_recursively(node)
{
var except_tags = {
"textarea":"タグの包含が許可されていないのか<nobr>で囲ったテキストが消えてしまう。",
"nobr" :"二重適用防止"
};
for (var child = node.firstChild; child; child = child.nextSibling){
if ((child.tagName||"").toLowerCase() in except_tags) {
// skip blacklist-ed elements.
} else if (child.nodeType == Node.TEXT_NODE) {
child = auto_nobr(child);
} else if (child.firstChild) {
apply_auto_nobr_recursively(child);
}
}
}
var h2 = document.getElementsByTagName("h2");
for (var i = 0; i < h2.length; ++i) {
var root = h2[i].parentElement;
if (! root || root.tagName.toLowerCase() != "div" || -1 == (" "+root.className+" ").indexOf(" day ")) {
continue;
}
// now root is a div.day.
apply_auto_nobr_recursively(root);
}
それから、
ひとつ心配なのは、?によって存在しないことにされたキャプチャを参照することが必ずマッチの失敗を意味するのかどうか。参照が空の文字列に展開されるなら必ず成功すると判断されてもしかたがない。たとえそれが NULLと空文字列の混同だとしてもありそうな話ではある。
と書いておいた懸念は現実のものだった。Firefox(23.0.1)でも IE9でも次のスクリプトは true(マッチした)を表示する。(ちなみに ruby1.8は nil(マッチ無し)を返す)
alert(/(?=(A)?)\1/.test("B"));
これと区別できた方が応用が広がるのに。
alert(/(?=(A?))\1/.test("B"));
@2013-11-05 Safari(5.1.7)の微妙に異なる振る舞いとやり残し。
Safariでは <nobr>で囲った直前の文字までがひとかたまりになるのか、句点+2文字が次行に送られている。読みやすくはあるがなんでこうなる? Safariのユーザー・エージェント・スタイルシートに nobr{white-space:nowrap}がある。これを normalで上書きすると NOBRタグによる禁則が無効になる。空白による分かち書きを行わない日本語文章において white-space指定は空白だけを対象にしたものではなかったか。そういえば全角文字だけの文章と全半角混在の文章で Safariの処理が異なるという報告もあった。ま、<NOBR>でも white-space:nowrapでも、Safariが対象要素の外側にある1文字を余分に巻き込む理由にはならないとおもうけど。パターンから行頭禁則文字手前の1文字にマッチするドットを取り除くと Safariの挙動に対応した禁則処理が行えるが、そうすると Firefoxで行頭禁則が効かなくなる。おかしな Safariに合わせたりはしない。
既にタグで囲まれているテキストと交差するように <nobr>で囲うことはできない。ということは、「<a>テキスト</a>」とか <a>テキスト</a>。みたいなよくあるマークアップ済みテキストに禁則処理を適用できないということだ(むしろこれに対処したくて Safariは直前の文字(要素)を巻き込んでるのか?という疑いもわいてきたが、直前の文字ならぬ直前の要素にくっついたりはしなかった。残念Safari残念)。これは後付けスクリプトでなんとかできるとは思えない。Firefoxの word-break:break-all完全対応待ち。
@2013-11-06 両端揃え
1.箱の端から端まで文字を満たしたい。
を徹底するためにスタイル指定を足して完成。
.day .section, .day .title > * {
text-align: justify; /* 両端揃え */
text-justify: inter-ideograph; /* 日本語両端揃え(IE向けに字間の調整方法を指定する。CSS3?) */
}
Firefox(23.0.1)と IE9は期待通り。Safari(5.1.7)は英字手前のスペースだけを使って両端揃えをしようとして英字混じり文が不自然に分断される。これは
3.やりすぎた字間調整(text-justify)は見苦しいからやらない。
に反するけど、Safariだけの問題なので知らない。時間が解決するでしょう。
<追記@2013-11-11>WebKit向けに面白いことをしてる人がいますね。「【目指せePub出版】Webkitでtext-align:justifyに挑戦する | 高橋文樹.com」俺だったら表示されない空白SPAN要素を挿入するんでなく Unicodeの幅0スペースのどれかを挿入するかな。結果が期待通りになるかは確かめる必要があるし、いずれにしろコピペがひどいことになりそうでコンテンツを改変しない方策が望まれるが。</追記>
<追記@2013-11-12>こういう指摘「iOS5のMobile Safariでは、日本語でも両端揃えができるようになりました | BALLOG」もあるが、提示された例から判断する限り、iOS4で行われていた「ィ」「ー」の禁則処理が iOS5で行われなくなった結果行末が揃っただけに見える。字間調整が行われた結果ではなく、むしろ退化してないか?それから、全角文字だけで文章を書くならスペースに頼らない字間調整が行われるとの報告もある>「webkit系ブラウザ(Chrome/Safari)で両端揃えはできないの?jQueryで検証 | 株式会社LIG」。</追記>
@2013-11-07「CSS Text Module Level 3 (www.w3.org)」
text-justify
W3C Last Call Working Draft 10 October 2013
The following features are at risk and may be cut from the spec during its CR period if there are no (correct) implementations:
- the ‘text-justify’ property
Value: auto | none | inter-word | distribute
先月出た文書。text-justify(とその他いくつか)が名指しで消滅の危機。後がない。inter-ideographに代えて distributeを指定しといた方が先々有効かも(属性自体が消えてなければ)。
word-break, line-break
word-breakに line-breakを統合するのはなくなったんだろうか。line-breakの項目がある。うまくないとは思ってたので歓迎。でも句読点の禁則が line-breakの3つのレベル:strict-normal-looseのどこかわからない。
句点は U+3002;CL # IDEOGRAPHIC FULL STOP。かぎかっこ(開)は U+300C;OP # LEFT CORNER BRACKET。UAX #14 (www.unicode.org)では CLも OPも言及されてるけど、CSSの 5.1. Line Breaking Detailsではそれらを含まないクラスに限定して UAX #14を参照してるから CLも OPも位置づけが明確にならない。要は、line-break属性で具体的に挙げられてるのは最低限の要件であって、その他の線引きは User-Agentまかせということだった。書いてありました。
CSS distinguishes between three levels of strictness in the rules for text wrapping. The precise set of rules in effect for each level is up to the UA and should follow language conventions. However, this specification does require that:
将来組み版向けに細かい制御が必要だろうとも(別の場所で)言ってるが、当面満足できないということは、line-breakを緩くしておいて必要な部分に<nobr>というアプローチもなくはないのか、な?
KADOKAWAが EPUBの取り扱いに関する文書を公開していたな、とダウンロードしてみた。→「KADOKAWA-EPUB PORTAL」
■3点リーダや2倍ダーシがつづく際の禁則の抑制について
3点リーダや2倍ダーシ、ナカグロなどは、前後の文字と分離禁止禁則が行われるため、あまり長いと直前の文字から改行されて、意図せぬ表示になることがある。そのようなときは、4文字以上連続する場合を目安に、以下のように「word-break-break-all」を該当箇所にのみ指定すること。未対応の RS もあるが、指定があって表示が崩れることはないので挿入しておく。
【参考】分離禁止される可能性の高い文字について
CSS3 の「line-break」の項には、行頭・行末で前後の文字との分離が禁止になる文字についての記載がある。詳細は「http://www.w3.org/TR/2012/WD-css3-text-20121113/」の「line-break」の項を参照。
実際には、まだ禁則処理については RS 次第であり、line-break の指定が反映されることも期待できないので、これらに依存するような記述は避ける。
基本は word-break:normalで、必要に応じて一部を word-break:break-allで
この PDFでも見たし、数日前に「自炊ePubのためのあれこれ覚え書き - 道具眼日誌:古田-私的記録」でも見たのだけど、tcyというクラス名を。やっぱりアレをタテチュウヨコと読むんだってことだよね。検索したら例によって Wikipediaが一番。「読みは「たてちゅうよこ」であり、「たてなかよこ」ではない(JIS X 4051で規定)」。腹腔といい縦中横といい、ローカルルールでもこうと決めたからには正解!みたいなのってどうなん?
@2013-11-09 ECMAScript(3rd&5th ed.)の、Rubyとは異なる、残念正規表現仕様
20131101p01.08の最後の方に書いてたこと。Firefoxでも IEでも Safariでも同じ挙動――?をキャプチャの中に付けても外に付けても trueを返すこと――を示すので ECMAScriptとして規定されてるんだろうと探してみた。以下該当部引用。太字強調は失われたり付け足したりしてます。
The form (?! Disjunction ) specifies a zero-width negative lookahead. In order for it to succeed, the pattern inside Disjunction must fail to match at the current position. The current position is not advanced before matching the sequel. Disjunction can contain capturing parentheses, but backreferences to them only make sense from within Disjunction itself. Backreferences to these capturing parentheses from elsewhere in the pattern always return undefined because the negative lookahead must fail for the pattern to succeed. For example,
/(.*?)a(?!(a+)b\2c)\2(.*)/.exec("baaabaac")looks for an a not immediately followed by some positive number n of a's, a b, another n a's (specified by the first \2) and a c. The second \2 is outside the negative lookahead, so it matches against undefined and therefore always succeeds. The whole expression returns the array:
["baaabaac", "ba", undefined, "abaac"]
こちらでも "always succeeds"と書いてある。
Informative comments: An escape sequence of the form \ followed by a nonzero decimal number n matches the result of the nth set of capturing parentheses (see 15.10.2.11). It is an error if the regularexpression has fewer than n capturing parentheses. If the regular expression has n or more capturing parentheses but the nth one is undefined because it hasn't captured anything, then the backreference always succeeds.
残念だ。thereforeとかあっさり書いちまいやがって。それはまったく自明ではないぞ。
空パターン(※JavaScriptは Perlと違ってダブルスラッシュがコメントになってしまうので作るのに小細工が必要)が必ず成功するのはわかる。でもそれに対応するのはキャプチャが空文字列を保存していてそれを後から(その文字列そのものにマッチする)パターンとして参照した場合であって、参照すべきキャプチャ・参照すべきパターンが存在しない(=undefinedである。空文字列ではない)ときは必ず失敗して欲しかった。理由はすでに書いたように、この二つを区別できなくなるのが困るからだ。
/(?=(A)?)\1/.test("B"))
/(?=(A?))\1/.test("B"))
もっと実際的な不利益は 20131101p01.06に書いた書き換えが通用しないことだ。これって C++11にも影響する(してる)んでしょ? *SIGH*
@2013-11-12 Safari(Win版5.1.7)で満遍なく字間調整
Safariでは全半角混在文章に対しては自動的に text-justify:inter-wordに相当する字間調整が選択されるらしく、日本語文章にわずかに含まれる空白が過剰に引き延ばされた見苦しい表示になってしまうことをもう書いた>20131101p01.10。
実は word-break:break-allを指定しているとほとんど任意の場所で折り返しができるので(Safariの場合禁則処理も行わないので)わずかなスペースに調整のしわ寄せがいっても問題にならない(といっても切り落としたような右端のラインは得られないが)。でも禁則処理を施した場合 Safariはなぜか3文字を次行に送ってしまうので(20131101p01.09)、全角1文字分以上の空白が文章を分断してしまうのが問題になる。
どうするか。これに対処して「<span style="width:0; font-size:0; overflow:hidden"> </span>」を挿入した人が唯一見つけられる。visibility:hiddenを指定した空白なら挿入してもコピペに影響しないのを Safariと IEと Firefoxで確認した(※)ので自分はこうした。※.textContentには影響するかも。.innerTextには影響しないかも。
// Windows版Safari(5.1.7)の字間調整は全半角混在文章でスペースに対してしか働かず文が不自然に分断されてしまう。
// 不可視の空白を挿入することでさらなる字間調整ポイントを Safariに対して教える。
// 相当うざい結果になる(なにせほぼ任意の2文字の間に SPAN要素が挿入される)ので、Safariでだけ実行するように。
function textfunc2_safari_whitespace_distribution_inter_ideograph(textNode)
{
var _xp, new_xp = function() { // XP = expansion point
if (! _xp) {
var d = textNode.ownerDocument;
_xp = d.createElement("span");
_xp.style.fontSize =
_xp.style.letterSpacing = "0px";
_xp.style.visibility = "hidden";
_xp.appendChild(d.createTextNode(" "));
}
return _xp.cloneNode(true);
};
var p = textNode.parentNode;
var m, re = /\S(?=\S)/;
while (m = re.exec(textNode.nodeValue)) {
/* assert 0 < match.length in case of infinite loop. */
textNode = textNode.splitText(m.index + m[0].length);
p.insertBefore(new_xp(), textNode);
}
// ついでに、Safariが <nobr>の直前直後の2文字を接着して字間調整も折り返しも行わないのを矯正する。
try { if (textNode.nextSibling.tagName.toLowerCase() == "nobr") {
p.insertBefore(new_xp(), textNode.nextSibling);
} } catch(e) {}
return textNode; // the last Node of splitted textNodes.
}
スクリプトの全体はページのソースを参照のこと。結構重い処理なのでページの表示後しばらくして文字が移動するのが見えてしまうかも。でも Safariだけの問題なので(略)。
Safariで表示したこのページでテキストを選択してみると、文字と文字の間に白い縦線が入ってるのが見えるんじゃないだろうか。それが visibility:hiddenなスペースだと思われる。行末から行頭に向かって1文字1文字の間に1ピクセルの字間を配ってるかんじ。行頭に着いても分配する字間が余ってる場合は2ピクセル目をまた行末から配る、と。たまに2文字くっついたままになってるのは禁則処理のために挿入した NOBR(開き)タグの直前と直後の文字。Safariはなんでこの2文字を接着してしまって字間調整も折り返しも行わないんだろう。<NOBR>の直前に字間調整用の SPANを挿入するとめでたく接着が解けたが、SPAN挿入の二重適用を避けつつ NOBRに限ったアドホックな処理を追加せずに済む方法は……。<追記@2013-11-14>上のスクリプトは Safariを特定したものなのだし、NOBR要素狙い打ちで字間調整用の SPANを注入することにした。 </追記>
<追記@2013-11-21>見えない、クリップボードにコピーされないとはいえ、スペースを挿入してるのは間違いないので、スタイルシートを切ると空白入りのテキストが表示されるし、ページ内検索も空白を入れないとヒットしない。タグの意味的にもこれらの副作用を避ける目的でも WBRタグを使いたいんだけど、字間を挿入する効果がないんよね。</追記>
<追記@2013-11-25>分離禁止と分割禁止の2つの概念。分離禁止は分割禁止を含む、より強い拘束。―と―の間に改行(折り返し)はもちろん空白も挿入してはいけないというのが分離禁止の例。WBRは分割(改行(折り返し)の挿入)を許可する要素だから自動的に字間の挿入も許可しているはず。期待して待っていていいかな?</追記>
「W3C日本語組版ノートとCSS3 - JAGAT」
WebKit以外は禁則に対応している。CSSには禁則ルールを「通常」から「厳しくする」と3段階の設定がある。両端揃えについては実装依存、「どういう実装をしてもいい。ただ日本語ではJLREQを参照するといい」としている。EPUB仕様も同様である。
Firefoxで word-break:break-allを指定すると禁則処理が行われなくなるのが問題。(対応してるが適用外)
Safariが全半角混在文章に対して日本語向けの両端揃えを選ばないのが問題。(xml:lang="ja-JP"なのに JLREQを参照すべき場面だと思われていない)
「public-html-ig-jp@w3.org Mail Archives」
@2013-11-14 PS3・泥ケー・Opera
PS3のインターネットブラウザも今では WebKitベースだとか(実際そう名乗っていた。診断くん)。なかなかきれいなフォントレンダリングで(でもズームするともやっとする)、禁則処理、字間調整の方法まで含めて Safariによく似た結果。スクリプトを有効にすることでこのページも期待通りの表示になった。
もうひとつブラウザ。ドロケー(URBANO L01)で表示すると中心線近くでせせこましく折り返したり折り返さなかったりする現象(※)が見られたんだけど、google/京セラのせいにして放置していいのか、DPIの高さにこのページが対応できていなかったりするのか。
※スクリプト実行中は画面に見えてる3日分のタイトルがせせこましく折り返してた。実行後は先頭の1日だけがせせこましく折り返したままだった。
また、ナビゲーションリンクをクリックすると再現性なく HTTPステータスコード 505 HTTP Version not supportedが返ってくることがわずかな時間に何度もあった。やっぱりブラウザ(GCかどうか知らないが)が信用ならんのかな。LTE経由やったから auがいらん茶々入れてたんかな。
Opera17も試してみたんだけど、フォントの設定がないのんな。開発者プレビューにはあったみたいだけどその場所にもなかった。閲覧者が読みやすいと感じるフォントは閲覧者が知っている(そして設定している)だろうと思って HTML/CSSではフォントファミリを指定してないんだけど、その結果がMS Pゴシックのビットマップフォント。3段階ほど文字を大きくするとベクタデータに切り替わるのか見られる表示になるけど、MS Pゴシックをあえて指定してすら文字が美しい Safariとは雲泥の差。見るに堪えない。
@2013-11-15 テーマ画像。DPI
URBANOのブラウザは Google Chromeではなかった。バージョンが4.XXXだということがかろうじてわかったがまったく素性が知れない。これは不自由ゆえか不慣れゆえか。
スマホの Google Chromeで表示してみると PCで見るより一行の文字数が少ない。固定サイズの背景画像を基準にして横幅をピクセルで指定しているために、ひと文字ひと文字をより多くのピクセルを使って精細に描画する(高DPIってこと)スマホでは文字数が減るんだろう。こういうのってベクタ画像をスケーリングしたり、左上角+辺の繰り返し+右上角の画像3枚構成で横幅を可変にしたりするのだろうか。そういうことができるのかどうかも知らないけど。それかこういうときにこそ画像の DPI値(JPEGにそういう値がなかった?)が役目を果たしてブラウザが勝手にリサイズしてくれたりするんじゃないんだろうか。DPIとピクセル数で現実世界の長さがわかるわけで、それを共通の尺度にしてブラウザが再度スマホにおいて画像を表示するのに使うべきピクセル数を求められるはずでは?でも現実世界の長さを共通の尺度にするとスマホの画面サイズは PCのモニタと比べて小さすぎるのか。でもそれはスマホが DPI設定をそれなりの高さに抑えておいてズームを駆使すればいいだけのことじゃないか。Windowsの DPI設定がモニタのピクセル密度を全然反映していないのだから何を考えても机上の空論か。そもそも、日記のテーマ(chiffon_leafgreen)で使われてる画像が DPI値をセットできない
PCでなんちゃってRetina。Firefoxと Safariにつく差。(@2013-11-22)
Windowsの DPI設定を2倍(192dpi)にするとなんちゃってRetina(300overにはまだまだ届かない)を体験できる。贅沢なピクセルの使い方の代償は画面の仮想的な広がりが面積比4分の1に狭くなること。24.1インチ・WUXGA(1920×1200)モニタは今となってはでかいばっかりで粗いもんだ。4Kなんかより QUXGA Wide(3840×2400)が 27インチまでで出ないかなー。
Firefoxは高DPI設定に応じて滑らかな、質感すら感じさせる文字を表示する。Safariは、自分の管理外なのであろうウィンドウのタイトルバーの文字だけがきれいで、メニューから文字から他の全てが滲んでぼやけている(もちろんズームはしていない)。Safariの普段の美しさは最適化(切り捨て)の結果なのだった。<< .exeのプロパティで「高 DPI設定では画面のスケーリングを無効にする」にチェックを入れるとまた結果が違うかも。(@2015-11-24)
仮想的に DPIを上げたからといってスマホの Google Chromeで見たようにこの日記の1行が16文字になったりはしないんだよね。ズームでなく文字サイズだけを拡大すると行あたりの文字数が減っていくから、これかな? 対策は、画面が小さくて文字が読めないときは文字サイズそのままでズームしろ、と。<<改めてスマホのGCで確認した。既に述べた状態は文字サイズ100%でのもの。60%で PCより少し1行の文字が多いくらいになる。それでタップしてズームすると左右の余白がほぼゼロになって精細で美しい文字の文章が難なく読める。物理的には PCモニタより小さいんだろうけど、カンマとピリオドを見分けるのにも苦労しない。文字サイズ100%で PCと同じレイアウトになって欲しいんだけど……。
追記@2014-02-16 ドロケーのブラウザで「60%で PCより少し1行の文字が多いくらいになる」ことに関係するかもしれない話。
Androidの密度非依存ピクセル「dp」
Density-independent Pixel / dipともいう
このdpという単位は、Androidアプリを作る際に使われる単位で、Androidの開発者向けウェブサイトではDevice-independent Pixel(密度非依存ピクセル)という単位を定義しています。これは160dpiのピクセル密度を持つディスプレイで表示される1pxを1dpとしたもので、たとえば、320dpiの場合1dp = 2pxに、480dpiの場合1dp = 3pxになります。
Androidでは Windowsや CSS3に準拠した 96dpiではなく、160dpiに固定して論理ピクセル「dp」を定義したと。160:96 = 1:0.6だから、文字の描画に使用する画素数を 60%(縦)×60%(横)に減らしたときに PCとレイアウトが同じになることに納得できる。
訂正@2014-03-17 CSS3の 1pxが1対1対応するのは CSS3の 1inであった。
そして、1inが現実の 1インチに対応するパターンの他に、1pxが "reference pixel"に結びつけられるパターンが認められている。Androidの Google Chromeでは reference pixelを媒介にして CSS3 px と dpが一致してるってことなのかも。
@2013-11-19「HTMLで文字詰めするタイポグラフィー用JS | fladdict」
これは字詰め。禁則とも字間調整(広げる方)ともかち合うので、これを適用しようとするとタグの交差に対処する方法を真剣に考えないといけない。でもやりたいなあ。読点とかぎ括弧、中黒は全角だと間延びしすぎだし、だからって半角文字を使うのも違う気がするし。ああでも、フォントを知らないと
<link href='https://fonts.googleapis.com/css?family=Noto+Sans:400,700,400italic,700italic&subset=latin,cyrillic,greek,vietnamese' rel='stylesheet' type='text/css'>
@2013-11-20 字詰め。
やった。ほとんど昨日貼ったリンク先のスクリプト(FLAutoKerning.js)の移植。行頭の約物の処理だけ省いた。折り返しでの天付きをせずにそれだけするのもどうかと思って。いい加減長いので詳細はソースの textfunc4_jizumeへ。
問題点
- さらに重くなった。重たい字間処理と重なる WebKit系が悲惨。
- MS Pゴシックだと詰まりすぎる。つまり、ユーザーがフォントを指定できない Opera17で詰まりすぎる。今日のこの日記を長々と書き継いでいるうちにリリースされた Opera18ではフォントの指定ができました。めでたいOperaすばらしい。(もちろん皮肉)
- Safariでは一部の記号の一部(※)が元々詰まっていて、そこに字詰め処理が入ると詰まりすぎる。※CODEタグによってプロポーショナルと等幅が切り替わる所だった。これは特殊だし難しいケースだ。(ある程度はタグを乗り越えて)隣の文字を見て詰める量を決めるけど、隣の文字からフォントが変わってるとは思わないもんなあ。タグを乗り越える理由は禁則のための NOBRタグを無視したいからなので、要素の終端で打ち切る選択肢はない。
- 適用先の要素に 0以外の letter-spacingが指定されていた場合は、それに加算した letter-spacingを設定すべきではないか?
まとめると、フォントにメイリオを指定した Firefox(25.0)、Internet Explorer(9)以外お断り仕様になってしまいました。
Firefox25での表示(ベンチマーク)> 20131101p01.pdf(610KiB)
スクリーンショット追加@2013-12-05
- Firefox19 on Mountain Lionのスクリーンショット(5.2MiB)>macml_firefox_19.0.png
Fx23 on Vistaとの違い。
- text-align:justifyにも関わらず右端が揃っていない(その割に文字間が調整されたような疎密の波がある)。
- PRE内の文字が font-size:100%指定にも関わらず 90%ほどになってる(IEとか他のブラウザでなら見たことあるけど)。
- iPhone5でのスクリーンショット(5.0MiB)>ios_iPhone-5_6.0_landscape.jpg
Fx23 on Vistaとの違い。
- PRE内の文字が font-size:100%指定にも関わらず 90%ほどになってる。
- 他は完璧、というか、感覚的な読みやすさで凌駕してるのでは?
{kind=link}
{kind=link}
プロポーショナルフォントにはもともと余分な空白はないし(※)、等幅フォントが指定してあるなら等幅であることを尊重すべきだし、実質、ほとんど等幅のプロポーショナルフォントであるメイリオでしか見るべき効果がない。
※参考にすること(メトリクスカーニングとオプティカルカーニング)@2013-12-05「デザイナーは文字詰めに命をかけよう ~和文と欧文のフォーマットの違いから考える~ | 企業ソーシャルメディア運用・ソーシャルデータ分析・YouTubeチャンネル運用の株式会社アクトゼロ」
SVGの方に measureTextとか text-renderingがあるらしい(DOMインスペクタを覗いていたら見つかった)。CSS Fonts Module Level 3にも font-kerningとか font-variant-east-asian:proportional-width(胡散臭い……)とかあった。追い追いどうにかなるでしょう。
といいつつ、せっかく書いたコードを捨てきれないのだなあ。簡易に等幅とプロポーショナルフォントを見分けて、プロポーショナルの場合は字詰めの対象を絞ることにした。メイリオ、MS Pゴシック、SH G30-M、SH G30-Pでまあまあ破綻せずに表示できてると思う。テストするときは、フォントを切り替えた後にリロードしないとフォントにあった処理が行われないことに注意。
長いけど貼りますよ。バージョン管理されてませんからログを残さないとね。
// 全角の約物・句読点などの連続すると過剰になる余白を詰める。プロポーショナルフォントはもともと
// 余白が調整されているから、主にメイリオと等幅フォントが対象になる。
// textfunc2/textfunc3で字間調整のための見えないスペースを挿入した後だと全く
// 効果がないのでその前に実行すること。
//
// アイディアと実装とカーニングペアの定義の下敷きはこちら。
// http://fladdict.net/blog/2011/02/auto-kerning.html
function textfunc4_jizume(textNode)
{
var is_proportional = function() {// ¿等幅フォントもしくはほぼ等幅のメイリオではない? フォントごとにカーニングペアのひとつひとつについてテストするのもいいかもね。
try {
var canvas = textNode.ownerDocument.createElement("canvas");
textNode.parentNode.appendChild(canvas);
var ctx = canvas.getContext("2d");
ctx.font = "100% "+getComputedStyle(textNode.parentElement||textNode.parentNode).getPropertyValue("font-family"); // If returned value is the used value, appendChild may be removed.
//console.log(""+ctx.measureText("」「").width+" "+ctx.measureText("@@").width);
return ctx.measureText("」「").width < ctx.measureText("@@").width;
} catch(e) {
return true; /* 字詰めをやりすぎないように無難な方を返す。*/
} finally {
if (canvas) {
textNode.parentNode.removeChild(canvas);
}
}
};
var ki = is_proportional() ? textfunc4_jizume.kerning_info_for_all : textfunc4_jizume.kerning_info_for_monospace;
var enclose_in_letterspacing_span = function(textNode, em) {
var span = textNode.ownerDocument.createElement("span");
span.style.letterSpacing = ""+em+"em";
span.appendChild(textNode.parentNode.replaceChild(span, textNode));
};
var next_element_char_or_empty = function(textNode) {
var skip_blankTextNode = function(node) {
for (;node && node.nodeType == Node.TEXT_NODE && /^\s*$/.test(node.nodeValue); node = node.nextSibling) {
// empty loop-body;
}
return node;
};
var nextNode = skip_blankTextNode(textNode.nextSibling) || skip_blankTextNode(textNode.parentNode.nextSibling);
for (; nextNode && nextNode.nodeType != Node.TEXT_NODE; nextNode = skip_blankTextNode(nextNode.firstChild)) {
// empty loop-body.
}
return (nextNode && nextNode.nodeType == Node.TEXT_NODE) ? nextNode.nodeValue.charAt(0) : "";
// あんまり先の方の文字を読んで letter-spacingを設定しても意味ないかもね。
// 何もしないか、むしろ先の文字に負の marginなりを設定したほうが意味があるかも。
};
for (var i = 0; i < textNode.nodeValue.length;) {
var char = textNode.nodeValue.charAt(i);
var nextChar = textNode.nodeValue.charAt(i+1) || next_element_char_or_empty(textNode) || "*";
var space = (ki[char+nextChar] || (ki[char+"*"]||0)+(ki["*"+nextChar]||0));
if (space) {
var charNode = textNode.splitText(i);
textNode = charNode.splitText(1);
enclose_in_letterspacing_span(charNode, space);
i = 0;
} else {
i += 1;
}
}
return textNode; // the last Node of splitted textNodes.
}
/*
カーニングペアの定義
単位はem。 -0.5(em) でボックス0.5個分詰まる。
"*く" と定義した場合、"あく"、"いく"、"うく"、というように、全ての"○く"の組み合わせにカーニングが設定される。
"あく" と定義をした場合、 "あく"という文字のペアのみにカーニングが設定される。
ワイルドカードペアと直接指定のペアが衝突する場合、直接指定のペアが優先される。
*/
textfunc4_jizume.kerning_info_for_all = { // プロポーショナルフォントでも削られていない(であろう)余白に関して設定する。
// 直接指定のカーニングペア
"か。":-0.05,
"が。":-0.10,
"け。":-0.10,
"げ。":-0.15,
"す。":-0.15,
"ず。":-0.15,
"み。":-0.05,
"。」":-0.25
};
textfunc4_jizume.kerning_info_for_monospace = { // プロポーショナルフォントでは削られている(ことが多い)余白に関して設定する。
// 前後の文字をワイルドカード指定した汎用のカーニングペア
"*ト":-0.10,
"*ド":-0.10,
"*「":-0.25,
"」*":-0.25,
"*(":-0.25,
")*":-0.25,
"、*":-0.25,
"。*":-0.25,
"・*":-0.25,
"*・":-0.25,
"*:":-0.25,
":*":-0.25,
// 直接指定のカーニングペア
"」「":-0.75,
"」。":-0.50,
"」、":-0.25,
"、「":-0.75,
"。「":-0.75,
"、『":-0.75,
"。『":-0.75,
"、(":-0.75,
"。(":-0.75
};
for (var k in textfunc4_jizume.kerning_info_for_all) {
textfunc4_jizume.kerning_info_for_monospace[k] = textfunc4_jizume.kerning_info_for_all[k];
}
getComputedStyle(textNode.parentElement||textNode.parentNode)に関して。
IE9がテキストノードに parentElementを定義していないらしい。まさにこれですよ。
一部のブラウザーでは、parentElement プロパティは Element ノードでのみ定義されており、特にテキストノードに対して定義されていない場合がある点に注意して下さい。
で、parentNodeでなく parentElementを呼んでるのは getComputedStyleの第一引数が Elementでないといけないと書いてあるからで
The first argument must be an Element, not a Node (as in a #text Node).
IEの場合だけ parentNodeで誤魔化します。parentである Nodeはいつでも Elementであるという仮定は、確かめてないけど、ほぼ正しいでしょう。
@2013-11-25「Mozilla, Opera でも日本語を均等割付(deztec.jp)」
知ってるドメインだけど 11年前の記事とあって読んだことはなかった。2番目に見つかった、空白挿入で均等割り付けをやった人。ただし対象は WebKitでなく Operaと Mozilla。今の Firefox(1.5から?)は日本語文字間に調整用の字間を挿入してくれる。英字間にまったく配分しないのが行内の疎密の偏りとなって時々目立つというのが現在の問題。
スピードアップ
is_proportionalが全体の50数%の時間を使っていたので結果をメモすることにした。読み込み完了直前に一回だけ実行する処理だから、スタイルやフォントの変更について行けなくても構わないよね。関数の消費時間の40%が削減できたので全体では2割の削減。
@2013-11-27 defer, async. ねえ waitは?
スピードアップの一環。SCRIPTタグに deferやら asyncを付けようと思うたびに未定義の関数を呼び出すエラーに悩まされて結局諦める。こういう非同期・遅延属性を付けたいのは完全自動の後付けスクリプトか共有ライブラリのどちらかだ。完全自動タイプは問題ない。deferと asnycを両方付けて非同期・最速で実行してもらえればいい。完全自動だけどイベントドリブンではないなら、対象要素の登場後に配置するなり deferだけを付けるなりすればいい(※あれもこれも deferにすると一部の非常に遅い外部スクリプトが以降の deferスクリプトの実行をブロックしかねない?)。ライブラリの場合は、ライブラリ関数を呼び出すコードがどこかにある。それが独立した .jsファイルであればライブラリ共々 defer属性だけを付けると順番に実行されることが期待される(HTML5に限って?)。でもページやその内容に依存して呼び出しコードが変化する場合は?ページの一部として HTML内に埋め込まれている場合は? src属性がない SCRIPTタグには deferも asyncも付けてはいけないという。
ライブラリは非同期・最速で読み込んでほしい。それを待って実行したい HTML埋め込みスクリプトはどうやって待つ?
DOMContentLoadedイベントの発火は Blink Opera(18)で非同期スクリプトの読み込み・実行より早いことがある。仕様がどうあれ、画像やスタイルシートの読み込みがまだかもしれないのと同様、スクリプトの読み込みが完了しているとは期待できないのが現状。
答えは jQueryのソースとかこのへんに(丸投げた!)>「<script>タグのasync属性を使わずに非同期でJavaScriptを読み込む方法 | さくらたんどっとびーず」「script.onloadを使ってJavaScriptがロードされた時の処理を記述する | さくらたんどっとびーず」。
やってらんない。非常に保守的で asyncや deferを付けすぎても全然問題を起こさない(でも読み込みは並列でやってる) Firefoxに限って script.onloadだとか document.currentScript、document.onafterscriptexecuteといったお役立ち手段が充実しているという。やってらんない。
<追記@2013-12-02>Promiseという名前/概念を仕入れた。asyncな SCRIPT要素が Promiseを返してくれれば、Promise.every(これと、これと、このスクリプト).then(function(scripts){ 指定したスクリプトに依存した処理 })とか書けそう。scriptsが何の配列なのかという疑問は残るが。</追記>
一番遅いのはスクリプトによるブロック(HTML解釈DOM構築中断。スタイルシート読み込み完了待ち(ただし Operaはインチキしてたらしい))ではなく、tDiaryのレスポンスなんだけどね。静的ファイル書き出しには抗いがたい魅力がある。.htaccessにはこういう記述があるんだけど
# Rewrite rule1
# shows static html, if exists.
RewriteCond /home/vvvvvv/www/cgi_file/ds14050/diary/snap/$1.html -f
#RewriteCond %{REQUEST_METHOD} =GET [OR]
RewriteCond %{REQUEST_METHOD} =HEAD
RewriteCond %{HTTP:Cache-Control} !=no-cache [nocase]
RewriteRule ^([0-9]{8})\.html$ /cgi_file/ds14050/diary/snap/$1.html [L]
なんでやめた(GETの場合を除外した)んだっけか。<テーマがまだら模様になるからだ。コメントやらなにやらで更新のあった日は、隣の書きっぱなしの日とは異なる更新日時点のテーマをまとって新たに書き出される。常に現在のテーマで表示されるも良し、12月に書いた日記がいつまでも12月のテーマで表示されるも良し。でもモザイクはいただけない。SSIででも対処したらいいんだけど1行コメントアウトする方が簡単だったとか、単体で完結しない .htmlファイルを書き出すことへの抵抗だとか(※SSIがサーバーを選ぶことは気にしない)。
Latestモードや Monthモードでレスポンスを一日一日順番に出力していくとかでもブラウザの助けになるんではないかと思うけど、どうだろうか。思い立ったが吉日でちょっとやってみよう。<<ETagとか Content-Lengthヘッダをどうするんだって。
ETagは必ずしもレスポンスボディから生成する必要はなかった>「ETagをどう生成するか - 岩本隆史の日記帳」
Content-Lengthはどうか。
- 転送コーディングが施されている場合、Content-Length ヘッダは送られてはならないし、仮に送られてもこれを無視しなければならない
- 転送コーディングが施されていない場合、Content-Length ヘッダは送られなければならないが、これはメッセージボディ中のオクテット数と正確に一致しなければならない
- Content-Length ヘッダが送られない場合は、接続の終了を持ってエンティティボディの終末を判断する事ができるが、リクエストボディにおいてこの手法は推奨されないし、サーバは 411 レスポンスを持って明示的に拒否する事ができる
レスポンスの場合は接続を閉じることで内容・転送の終了を告げることができるので必ずしも Content-Lengthが必要ではない、のかな?
body = tdiary.eval_rhtml
を
tdiary.write_to($stdout)
みたいな形にする方向でやってみる。
いろいろのバッファの他に HTTPDが間に入って、実際のところどうなってるんでしょ。
@2013-12-06 字間調整・改。そして、独立分離している文字列処理を実行時に効率的に融合する方法。
WBRタグでは効果を得られない。不可視の空白を挿入する方法ではスタイルシートを切ったときに空白が見える。またページ内検索でも、単語の文字と文字の間に空白を挿入しないと見つけられなくなる。第3の方法は CSS content属性を使うこと。スタイルシートを切ると空白ごと消えるし、ページ内検索でも挿入された空白は無視される。また、どのブラウザでも字間挿入効果があることは確認済み。
実装の問題は、要素の挿入ではなく要素で文字を包むことになるのを、他の文字列処理(禁則, 字詰め)が知って対処する必要があること。実際のところそれはもう済んでいて、さらに以前は禁則と字詰めと字間調整がバッティングする場面(「A」「B」など)で字詰めが効いていなかったのだが、これも解決した。解決していないのは、各々の文字列処理がテキストをぶった切るのだが、2番目3番目の処理は細切れのテキストノードを相手にしなければならないがために、メソッドの呼び出しとメソッドの固定された初期処理とタグを乗り越えて文字を先読みすることの回数が増え、効率が著しく低下すること。2段3段の文字列処理を加えるなら切断は一度で済ませたい。
対象が共通。操作も若干のバリエーションはあるものの大枠は同じ。対象と操作を選び組み合わせるところが固有。固有部分を分けながら実行時に効率的に融合させる方法。マニピュレータ付きのコンテクストを引き回す。操作を一旦ため込んで、マージしてから実行に移す。
- style_to_range(begin, end, style) // letter-spacingなど
- unbreakable_style_to_range(begin, end, style) // white-space:nowrapなど
- unbreakable_tag_to_range(begin, end, tag) //NOBRで囲むのを white-space:nowrapに替えるなら今のところ不要。
- 要素挿入メソッド。幅のないrangeに対する unbreakable_xxxとして扱えるはず。でも字間調整のためにはもう不要。
あとで。
@2013-12-08 アップロードした>textfunc.ver2.js@2015-03-04
いいかげん HTMLに埋め込むには長々しいので独立した .jsファイルに。textfuncX_*はより簡素になったが、それを走らせる基礎を新しく書いた。過去の記録>textfunc.ver1.js。オーバーヘッドは ver2の方が大きい。が、多段のテキスト処理を前提にするなら組み合わせによる所要時間の増大は ver2の方が抑えられている、と思う。誤算がひとつ。IE9は visibility:hiddenな content属性値をクリップボードにコピーしてしまう。それでも、スタイルシートOFFで挿入した空白が見えてしまうことやページ内検索がほとんど不可能になってしまうことに比べればずっとマシではある。
TODO: 高速なフォント判別。ブラウザ判別によらないテキストレイアウトの妥当性検証。混植?
フォント判別(is_proportional)が一番コスト高なのは変わらず。テキストレイアウト(禁則・字間・字詰め)が満足できるものかどうかをブラウザ判別に頼らず機能検出によって判断する(※jQuery.browserがなくなり代わりに現れた jQuery.supportの使用が推奨されるらしいが「jQuery.supportでのブラウザ判別」という面白記事の登場は避けられない世の流れ(惰性)か。ブラウザを判別したいその理由、ブラウザ間の差異を検出するロジックを jQuery.supportに追加するのが本道だろうに)方法は、(より軽量な)フォント判別にもつながっているように思う。.offsetWidthとかね。結局のところ初めて見つけた .measureTextを使ってみたかったというのが is_proportionalを構成する理由の8割だから、中身を置き換えると存在理由までが消えてしまいかねないのだが。
<追記@2013-12-22>is_proportionalが遅いのは先送りされていたブラウザの処理が getComputedStyleをきっかけにして実行に移されるから。is_proportionalから getComputedStyleを取り除くと処理時間のほぼすべてが is_inline_element(これも getComputedStyleを呼んでいる)へと移る。DOM操作のコストが getComputedStyleをきっかけにして噴出してるとみるのが正しい。例えば関連するスタイル(wbrクラス)の定義をスクリプト実行の後ろに移すことでわずかに改善する。</追記>
混植だって。「「Webデザイナーのためのタイポグラフィと文字組版(Reloaded)」鷹野 雅弘(スイッチ)」やろうと思えば正規表現で文字を拾い出して最小限の SPAN要素でフォント指定ができますよ。他の処理を有効にしたままで。……と思ったらここに衝突の種が。
フォントを変更する処理とフォントに依存する字詰めを並行して行うことはできない。一段目としてフォントを変更する処理を単独で(テキストノードの分割を最小限に抑えながら)行い、二段目にその他の処理をまとめて行うワークアラウンドが必要になるだろう。
上の方でリンクした MLで名前を見た人達がいたので。おもしろい。
@2013-12-11 .offsetWidthによるボトルネック(is_proportional)の解消&テキストレイアウトの検証……のはずだったけど
.offsetWidthを使った is_proportionalは Firefox23で .measureTextの倍の 1.4秒かかった。Operaでも .measureTextの消費時間が2桁ミリ秒のところ .offsetWidthは4桁ミリ秒を消費する。意外にも canvasを作って .measureTextする方が早かった。
is_proportionalのテスト過程で気が付いたんだけど、Opera18と Safari5.1.7で等幅フォントとして欧文フォント Consolasを指定すると、日本語用のフォールバックが、FontLinkではメイリオを指定してるにも関わらず MS Pゴシックになる。font-family:monospaceを指定してるのに台無しだよ!
.offsetWidth/.offsetHeightを使ったテキストレイアウトの検証は function TextLayoutInfo() として textfunc.ver2.js@2015-03-04に追加した。
結果が出てから調べる奴。
- Firefox23での実行結果
- Measure text in span is 78% slower than Canvas measureText().
- Internet Explorer9での実行結果
- Measure text in span is 95% slower than Canvas measureText().
- Opera18での実行結果
- Measure text in span is 93% slower than Canvas measureText().
- Safari5.1.7での実行結果
- Measure text in span is 91% slower than Canvas measureText().
圧倒的じゃあないか。
まだ高速化をあきらめない。is_proportionalの結果を要素にメモするのでなく font-familyの値をキーにしたメモをどこかに作ればいい気がした。でもそれには computed valueの定義の新旧を乗り越えないといけない(関連:used value)。
Fx23で1割しか改善しない。getComputedStyleで時間を食ってるのかも(Operaだと組み込み関数のプロファイルもとれるんだけど、Fxでは?)。
これね(またしても後手)。
前に読んでたけど「offsetWidth のようなプロパティを使ったり getComputedStyle のようなメソッドを呼ぶと」なんてそのものズバリの具体例が頭に残ってなかった。
そろそろおしまい
経緯をふり返ってみる。
- URLが折り返されなくてはみ出したり、長い単語がごっそり次の行へ送られて右端が余ったりするのが嫌で word-break:break-allを指定する(横幅に制限のあるテーマだったから word-wrap:break-wordとともに最初から指定してあった)。
- Firefox(と Safari)で禁則処理が行われないのがありえない。(word-break:break-allが原因)
- NOBRタグを使って全てとはいわないが大部分の禁則処理を補完する。
- 右端が揃ってないのが気になってきた。(禁則処理が悪化させた)
- text-align:justify, text-justify:distribute(inter-ideograph)で行末を揃える。
- Firefoxと Safariで生じる字間の偏りが気になる。(IEと違い text-justifyで行末揃えの具体的方法を指定できないのが原因)
- 不可視の空白を分離許可・分割許可の目印として挿入することで是正する。
- 字詰め(カーニング)も同じ仕組みで実現できそうなのでやってみた。
- あれ?分離許可・分割許可の空白を挿入してるなら word-break:break-allする必要なくね?
- word-break:normalにしてブラウザの禁則処理を利用すると、タグをまたいだ禁則も有効になって嬉しい。<<imkk
- (これから) IE以外で英単語がぶった切られる結果になるのは問題があると思ってる。word-break:break-allや word-wrap:break-wordや無差別な分離許可・分割許可の挿入にかえて、text-justify:distribute, line-break:loose, hyphens:autoが使える日を待ってる。日本語か英語しか書けないのだしハイフンを挿入できる位置を自分で調べるという手もあるにはあるが……(機械的にできるのか利用可能な辞書があるのかまったく不明)。
word-break:break-allから始まる一連のもぐらたたきの結末は、word-break:break-allをやめて自分で分離分割許可ポイントをブラウザに提示することだった。
一般的に参考になるのはこちらの記事でしょうね。自分の場合は優先順位が異なるので紆余曲折を経る必要があったわけだけど。
検索したら TeXとクヌース先生に行き着くのですね。ハイフネーションは第一義にはデータ圧縮問題だそうです。packed trieとかなんとか出てきた(そこに至るまでに linked trie, indexed trie, compressed trieなど。勉強になるなあ。WEB+DB PRESS vol.42で読んだ『高速文字列解析の世界』の人の記事はそれ自体が圧縮されていて何度読み返しても難しかった)。いつもの、書いたからやる羽目に陥ってるような気がしないでもない。­によるソフトハイフンは一番遅かった Firefoxでもとっくにサポートされてるらしい。URLみたいなのには、コピーには影響しないとしても、折り返し点でハイフンが表示されてほしくないな。うまく無視して word-wrap:break-wordに任せるか、代わりに WBRタグを挿入するか。字間調整のために挿入するスペース(.wbr:before{content:" "})の代わりに ­(.wbr:before{content:"\0000AD"})を挿入してみたけど Firefoxでは期待通りのソフトハイフン。Safari5.1.7/Opera18では異常な空間が生じる。IE9は単語間調整を優先して折り返してくれない。ジャスティファイのやり過ぎが嫌でいろいろやってるのに、調整幅の最大値を制限できないせいで。ぐぬぬ。
@2013-12-27 text-justify: distribute
まだやっていました。textfunc5_nobr_over_asciiwordを追加。これは textfunc2, textfunc3から英単語を分割する効果のみを取り除くもの。分離効果が残ってるのがミソで、英字間に両端揃えのためのスペースを分配はするが、英単語の途中で折り返しはしなくなる。これは要するに word-break: normal; text-align: justify; text-justify: distribute を指定して得られるはずの結果と同じ。
- 日本語文では、ほぼすべての文字間隔が調整対象で、禁則を例外としてどこでも折り返せるので、違和感なく両端揃えが行われる。
- 英文では、単語間隔と文字間隔をバランス良く調整対象にすることで、単語や文字が散漫に散らばる印象を抑えることができる。
- ハイフネーションによっても同じ効果が得られるがこれはまた別の話。
- TODO: WebKit系の字間分配アルゴリズムが「右端から順番に」なので行末がルーズになりがち。
- 日本語英語混じり文では、日本語文に対しては英単語内で折り返せないことで、英文に対しては英単語間のスペースの数が限られていることで、字間調整量が過大になりがちで、ところどころ散漫な行が目につく。混合文に限って
word-break: break-allでぶった切るのが無難だと思うが、lang属性を積極的に活用する運用になってないので見分けられない。これの満足のいく表示が一番難しい。
見苦しい部分が少ないながら残るものの総合的にみて満足してる。Firefoxでスクリプトを切ってこの日記を表示すると、より多くの散漫な行が目に入る。Opera18でスクリプトを切って見ると、行末が揃わない、ぽっかり数文字分の空白がそこここに現れる。IE9でスクリプトを切って見ると、何も変わらない……。IE9は英語でも日本語でもありえない表示は行わないし、text-justifyによって選択肢を提供してくれるけど、スクリプトによってそれを逸脱するような操作を行う余地がない(何をしても効果が見られない)。ま、いじれなくてももともと見られない表示ではないので構いません。字詰めに関してはどのブラウザでも同じように効果を発揮してる。かぎ括弧の余白が削れて満足。
@2014-01-05 JSLint
jslint.comで textfunc.ver2.jsのクリーンさをチェック。タブインデントをオプションで許してもらうと、残ったエラーは4つ。
Missing 'use strict' statement. line 19 character 55
var sorted_unbreakables = [];Unexpected '--'. line 25 character 60
for (begin_first = this.length; 0 <= begin_first-1; --begin_first) {Unexpected '++'. line 30 character 8
for (begin_last = begin_first; begin_last < this.length; ++begin_last) {Move 'var' declarations to the top of the function.
for (var pos = begin_first; pos <= begin_last; ++pos) {
for文に関するものはスタイルの問題なので変えない(そういえば前に別のスクリプトで jslint.jsを試したときも forまわりが多かった>20080212p01.02.01)。間違ってるのは JavaScriptの仕様です(letがデメリット無しで使えるなら varから乗り換えるけども)。"use strict"; は早速ファイルの先頭に置いてみたけど何も変わらなかった。varを1か所取り除いて暗黙のグローバル変数を作ってみたらエラーが出たので無視はされてないみたい。未来への保険⁑/保障⁂/保証*4としてそのまま置いておく。
@2014-03-07 FLAutoKerning.jsの亜種。
jquery.kerning.js|http://karappoinc.github.io/jquery.kerning.js/
Notice
使用するには、フォントに合わせたカーニングデータの作成が必要です。 現時点では、ソースコードに付属しているテンプレートを参考に、使用するフォントに合わせたカーニングデータを別途作成する必要があります。
※ フォントデータから自動的にjsonデータを生成するツールを試作中です。
こういうのはカーニングデータの重要度が9割以上だと思う。そしてカーニングデータはフォントに固有。そして使用されているフォントをほぼ確実に知るためには Webフォントが必要。字詰めの実装方法が letter-spacingであるとか、display:inline-block と margin-left、margin-rightの組み合わせであるとかは些細な違い(といいながら興味津々でソースをのぞいてるわけだ。俺の関心はそっち)。
@2015-01-19「音声出力環境における擬似要素(::before, ::after)の内容(content)の読み上げについて|Web制作 W3G」
content属性値は読まれてしまうそうです。空白文字に関しては、単語としての認識を阻害し、息継ぎが発生するらしい。
@2015-02-17「Webフォントサービス「FONTPLUS」に文字詰め機能を実装|ソフトバンク・テクノロジー株式会社のプレスリリース」
提供するフォントから余白に関するデータを一括で削除し、そこに CSSで余白を付けるという手順。フォント間の差異を一度リセットすることで共通のカーニングデータを利用できるようにする試みなんだろうか。
- 同じ字でもあまり形が違うとフォント間でカーニングデータを流用できない
- どうせ Webフォントを使うなら最終的にはフォント固有のカーニングに行き着く
だろうとはいえ悪くはない。手抜きでも完璧でもないほどほどを狙ったサービスじゃないかと。
一だったり十だったりする人の日記でも字詰め(@2015-04-25)
中里一日記: Mobile SafariのJavascriptで約物のアキ調整 Posted by hajime at 2011年09月29日 15:21
イカしたスクリプト>tsume.js
文字列って元をたどれば文字配列であって、れっきとしたデータ構造であり、しかもただの配列より便利なメソッドがいっぱい生えてるんだってことを思い出させてくれる。
日本語識別子って読む分にはいいけど、IMEを切り替えて入力するのはすんごく面倒なんだぜ。
@2015-03-22 Opera28がやった!
百聞は一見に如かず>20131101.html rendered by Opera28.pdf(1.5MiB)<スクリプトなしで右端が揃っている
いくつか前のバージョンでは日本語英語交じり文の字間を暗黙の text-justify:inter-word で調整した結果(※IEと違い text-justifyで他の調整方法を指定させてくれなかった)、わずかな空白文字が何文字分にも引き延ばされたりまったく調整できていなかったりした。Opera28では、選択肢がないのは同じだが、英字部分が text-justify:inter-word で、日本語部分が text-justify:distribute(inter-ideograph) 相当で調整されているらしく、これ以上を求めるなら個別に手作業するしかないんじゃないだろうかというまともな表示になっている。
英字部分が inter-word相当(distributeではない)ということで、英単語の中のアルファベット間には調整字間が分配されない。なので、行の大部分を英単語が占める場合に日本語部分が散らかってしまうことがある。俺は日本語をメインに考えてるので、textfunc.jk.jsでは英字部分にもスペースを散らして所々英単語を間延びさせていた(とはいえ、調整箇所が増えると目に見える影響は減ることが期待される。あくまでも期待>20140607)。優劣ではなく優先度の問題。これ以上の完璧を求めるなら手作業が必要だということの理由。
他の Blink搭載ブラウザはどうなんだろ(インストールしてないから確認できない)。
@2015-04-15 Google Chromeだけでなく WebKitの Safariでも改善していたみたい。やったね。
TextLayoutInfo, ブラウザ検出と機能検出
textfunc.jk.jsが読み込まれてるページ(たとえばここ)でコンソールを開いて
new TextLayoutInfo
と打ってみると、複数のプロパティを持つオブジェクトが返ってくる。その名前と値の表がこう
| TextLayoutInfo\browser | Firefox 22 | Opera 28 |
|---|---|---|
| fontsize_zero_is_available | true | true |
| no_kinsoku_under_wordbreak_breakall | true | false |
| no_whitespace_distribution_inter_asciicharacter | true | true |
| no_whitespace_distribution_inter_ideograph | false | false |
trueになっている項目(※fontsize_zero...以外)が textfunc.jk.jsによる修正対象。以前の Operaは no_whitespace_distribution_inter_ideographが trueになっていたはずだが、いつの間にか falseになっている。その結果 Firefoxの場合と同等の、処理の対象を英字のみに絞った低負荷バージョンが選択される、自動的に。これがブラウザ検出ではなく機能検出を使う理由。>>「HTML5 - ブラウザーと機能検出(msdn.microsoft.com)」
TextLayoutInfoによれば(※自作なのでいまいち信用できない)句読点の禁則にも改善があったみたい。word-break:break-allでの、禁則を無視したありえない表示がなくなったのではないだろうか。これに関しては一貫して IEがすぐれていたし、Firefoxが word-break:break-allに対応した15以来ダメな点だ(この日記のタイトルを見よ)。
textfunc.ver2.js (12.1KiB, 2015-05-14) + textfunc.jk.js (19.8KiB, 2015-03-22)
何であるか
word-break:break-allと text-align:justifyで各ブラウザに起こる諸問題を解決し、未だサポートされない text-justify:distributeを実現するためのスクリプト。
具体的に
- word-break:break-allでも(タグ境界を除いて)禁則。(Fx, Safari, Blink Opera)
- WebKit系でも justify. (Safari, Blink Opera)
- word-break:normal下(=折り返しが制限されて justifyの調整量が過大になりがち)でもなるべく調整の余白が目立たないように。(Fx, Safari, Blink Opera)
- (同じ仕組みを利用したおまけ) メイリオの約物の等幅チックな余白を詰める。(IE, Fx, Safari, Blink Opera)
備考
- 各ブラウザのバージョンは IE9, Firefox23, Safari5.1.7, Opera18.
- Presto Operaでは最小フォントサイズ設定が災いして文字が散らばってしまうので、TextLayoutInfo.fontsize_zero_is_availableでこれを検知して処理を諦める(諦めちゃいます。先のない Presto限定なので)。
- Opera 28で禁則とジャスティファイに改善がありました。20131101p01.34
- Opera 31(現在の最新版)で textfunk.jk.jsの is_proportional関数が満足に機能していない。たぶんこれの影響で判定と表示でフォントのフォールバックが一致してないとかじゃない?「Chrome 42でフォントがMS Pゴシックからメイリオに変更&元に戻す方法 | What I Know ~ワッタイナ」
- CSSの unicode-rangeデスクリプタで特定の文字範囲にだけ有効なフォント指定がしてある場合に、要素を対象にする is_proportional関数は対応できない。
変更履歴
- 2015-05-14
- コメント追加。
- 2015-04-10
- バグ修正。文字列をSPAN要素で囲ってスタイルをセットする時に、無関係な属性に
undefinedをセットしていた(単に無視されて無害だがコンソールがうるさい)。副作用で1割くらい速くなった。 - 2015-03-17
- Firefoxで実行時間の短縮。このページでいうと2000msから1200msへ。詳細
- 2015-03-11
- unbreakable_element_to_rangeと unbreakable_class_to_rangeを廃止し、unbreakable_style_to_rangeに統合。
- 2015-03-10
- unbreakable_element_to_range追加。(textfunc.ver2.js)
- textfunc6_non_strict_kinsoku追加。(textfunc.jk.js)
- 2015-03-04
- 構成変更。「本来別ファイルに分離すべきもの」とコメントしてた部分を textfunc.ver2.js から textfunc.jk.js として分離した。
- 2015-02-19
- action_to_range追加 (js/textfunc.kururi.jsで利用するため)
- textfuncに渡されるテキストが前から順番になるように深さ優先で。
* 全角文字の字間は拡大するが英字はそのままなので、一部は間延びして一部は詰まって見える。全体に散らした方が目立たないのに。@2013-11-19 Safariと同じ方法をより限定された対象に適用するだけで矯正できるのでやってしまった。対象を限定しなくても副作用はないけど処理負荷を考えて限定した。コピペコード率高し(だが構わない。分岐直後なので当然のこと。ツールファンクションは共有してもいいけど)。@2013-12-16 ■の連続も分割されないな。どういう Unicodeプロパティを参照してるんだろ。
? @2013-11-09 勘違いしてたけどこの部分は Rubyなのでパターンの中にパターンを埋め込む方法で繰り返しをなくせる。それに後に明らかになったように、この後の書き換えは各種ブラウザの JavaScriptで無効な、Rubyでしか使えない方法だった。ECMAScriptとしてあまりありがたくない動作が規定されてるのかも。
! 雰囲気で動詞化してみました。
@2015-03-04,(2) textfunc.ver2.js の一部を textfunc.jk.js に分離した。
⁑ 今は無駄だけど将来のうっかりな変更にそなえて。
⁂ うっかりな変更を許さない。
*4 うっかりしたコードが存在しないこと。
詳細 getComputedStyleを textfunc内から取り除くことは機能低下を招いてできないので、中間データをすべてため込んで DOM操作を最後にまとめて行うことにした。それだけ。副作用で GCできない使用中のメモリが一時的に増える。ちなみに Blink(Opera28)では悪化も改善もしない。Firefox(23)には最適化の余地があるってことだ。
2011年11月09日 (水)
もうずっと(※最初に認識したのは『ピエタ』だから今年の二月)アマゾンは発売直後の新刊を結構な頻度で「出品者から……」という状態におくようになってるし、このまえは Wishlistの 1ページ(※前から 2,3ページ目)のうち、納期が表示されてるのが 1冊だけであとは全部が「出品者から……」だった。その前後のページもほぼ同じ。サイトの使い勝手はいまも一番だけど、在庫が薄すぎる。アマゾンはもう自ら本を売るのはやめたもんだと見切りをつけたよ。電子書籍を Sony Reader向けにも配信するなら状況は一変するが、いまはまだこれ(の openを location.href=に変えたもの)を使ってる>アマゾンの URLに含まれる ISBNっぽい数字をジュンク堂で検索するブックマークレット。(20101125p01)■■■これまでであれば「2~4週間で……」と表示していたところが、「在庫あり」と「出品者から……」の二択になってしまうような環境の変化でもあったんだろうか。いずれにしろアマゾンで時価の本を個人売買せずともよそのオンライン書店には在庫があるわけだが。■■■@2017-05-08 難しくて全体は理解できないけど。「新刊については改善しつつある 問題がここ1年で飛躍的に改善したのが新刊である。新刊については、情報が出てから発売までに時間があるので、アマゾンの遅い発注判断でも、じゅうぶんな量の入手が可能になる。そのうえ、アマゾンも「新刊の追っかけ発注は入手しにくい」ということを学習したのか、発注量も多くなった。 新刊委託配本をしない出版社でも、取次とコミュニケーションを密にとれば発売即品切れを回避しやすくなった。 とはいえ、発注タイミングはやはり遅い。「発売前重版」になるような本がアマゾンで入手できず、一般書店には平積みになるようなことは多い。それは、書店としてのアマゾンの能力が低いということの証左だ。発売4週間前に発注しても入手できない個人書店の事情とは問題のレベルが違う。
」(アマゾンの「バックオーダー発注」廃止は、正味戦争の宣戦布告である)■ブコメの反応はわりと辛辣だけど、俺はそれに与しない。消費者全体にくらべて本の読者は圧倒的に少ないし、目立つ声が目指すところは俺のとはたぶん違う。
最終更新: 2017-05-08T10:18+0900
♪ [本][javascript] アマゾンの URLに含まれる ISBNっぽい数字を紀伊國屋書店BookWebで電子書籍検索するブックマークレット。
void function() {
var isbn = (location.href.match(/\b[0-9]{9}[0-9X]\b/)||[])[0];
if (isbn) {
var url = "http://bookweb.kinokuniya.co.jp/guest/cgi-bin/ebooksea.cgi?W-ISBN="+ isbn;
location.href = url;
}
}();
javascript:void%20function%28%29%7Bvar%20isbn%3D%28location.href.match%28%2F%5Cb%5B0-9%5D%7B9%7D%5B0-9X%5D%5Cb%2F%29%7C%7C%5B%5D%29%5B0%5D%3Bif%28isbn%29%7Bvar%20url%3D%22http%3A%2F%2Fbookweb.kinokuniya.co.jp%2Fguest%2Fcgi-bin%2Febooksea.cgi%3FW-ISBN%3D%22%2Bisbn%3Blocation.href%3Durl%3B%7D%7D%28%29%3B
「該当するデータがありません。」率が高すぎるだろうなあ。ブックマークツールバーのボタンをクリックするのがだんだん億劫になるだろうレベルで。
自動で背後で検索を実行してアマゾンの購入ボタンの下に BookWebへのリンクを挿入することも Firefoxの仕組みでできるんだろうけど、けど、リンクのプリフェッチと同じくなんとなく嫌だな。
2011年09月16日 (金) 電影少女を読んだ。D・N・A2との共通点は多いが「神尾まい」は比べる対象がない。あの前髪とまゆ毛とその隔たりはまったくすばらしい。中身が(外面からの)期待を裏切らない悪魔だというのと、結局はやられ役の残念なキャラだというのもポイント高し。
最終更新: 2011-09-17T05:22+0900
♪ [javascript] trailing commas ,
いくつかの点(文字列の行継続とか)で実装の追認をしてる 5th ed.ならいざしらず 3rd ed.では配列の末尾のカンマは無視できないだろう(IE8が正しい?)と思って昨日日記に書いたのだけど、よくよく読むとやっぱり IEが間違ってるっぽかったので消したのだった。
11.1.4 Array Initialiser
Syntax ArrayLiteral: [ Elision_opt ] [ ElementList ] [ ElementList , Elision_opt ] ElementList: Elision_opt AssignmentExpression ElementList , Elision_opt AssignmentExpression Elision: , Elision ,
The production ArrayLiteral : [ ElementList , Elision_opt ] is evaluated as follows: 1. Evaluate ElementList. 2. Evaluate Elision; if not present, use the numeric value zero. 3. Call the [[Get]] method of Result(1) with argument "length". 4. Call the [[Put]] method of Result(1) with arguments "length" and (Result(2)+Result(3)). 5. Return Result(1).
The production Elision : , is evaluated as follows: 1. Return the numeric value 1. The production Elision : Elision , is evaluated as follows: 1. Evaluate Elision. 2. Return (Result(1)+1).
1. Elision_opt(=カンマの 0以上の並び)は、カンマひとつにつき配列の長さをひとつ伸ばす。
2. ElementList: Elision_opt AssignmentExpressionや、ElementList: ElementList , Elision_opt AssignmentExpressionのように、Elision_optの右に AssignmentExpressionが隣接してるときはその数え方で自然。
3. ArrayLiteral: [ Elision_opt ] や、ArrayLiteral: [ ElementList , Elision_opt ] の場合は、Elision_optのカンマはその個数プラス1の要素を作り出すように見えるので、末尾のカンマがひとつ無視されたように感じる。
こんな結果になるなんて、余計なお世話もいいところだと思うんだけどな……
>>> [1,2,3,,,].length 5 >>> [1,2,3,,].length 4 >>> [1,2,3,].length 3 >>> [1,2,3].length 3
サイズ1の undefined配列を作れたりはするけど……(べつに嬉しくない)
>>> [].length 0 >>> [,].length 1
ちなみに JSONでは、思想から予想される通りに、末尾の余分なカンマは不許可。要素の省略(undefinedになる)もできない。ちなみに配列と違ってオブジェクトの初期化では、末尾の余分なカンマは不許可(3rd ed.しか確かめてないが)。
Syntax
ObjectLiteral :
{ }
{ PropertyNameAndValueList }
PropertyNameAndValueList :
PropertyName : AssignmentExpression
PropertyNameAndValueList , PropertyName : AssignmentExpression
例えばこれが JavaScriptのオブジェクト {prop:value,...}や Rubyの連想配列 {key=>value,...}や Cの enum {LABEL=1,...}の話であれば、末尾のカンマをあえて無視するのもいいだろう。要素の追加や並べ替えに便利なんだから。でも、JavaScriptの配列はダメだ。そこでは初期化の際に要素の省略ができる。空白に意味があるのだ。カンマの前後の空白の要素に関して、末尾だけ特別扱い(してるように見える)なんてのは不細工きわまりない。
2010年11月25日 (木) 佐川メール便。ネットで散々言われてる佐川だけど今日までは何とも思ってなかった。でもね、ポストに入らない大きさのアマゾンのメール便の角をポストに突き立てて、全体の80%を表の道路に露出させておくのってどう? 今日なんて CDサイズのメール便が表の道路に落ちてたけど!!!配達する品に責任が持てないなら運送業やめちまえ。よっぽど「届いてない。どうするんだ(拾って再配達するか、見つけられないなら賠償しろ)」って電話しようかと思った。一応書いておくと毎回こうなのではなくて、袋に入れて玄関のドアノブにかけてあったり、ドアにたてかけてあったりすることの方が多い。でも今日は腹立った。発売を待ちかねてた商品だからなおさら。ジュンク堂はヤマトかゆうパックで配送なんだね。ゆうパック(元ペリカン)のおっちゃんが一番感じがいいのだ。近畿2府4県を対象にしたジュンクお急ぎ便も嬉しい。しばらくはアマゾンで探してジュンク堂で買ってみよう。お急ぎ便やプライムが始まってから発送まで一日余計にかかるようにもなってたしね(ジュンク堂がそれより遅いか早いかはわからんけど)。
最終更新: 2014-06-24T05:36+0900
♪ [javascript] アマゾンの URLに含まれる ISBNっぽい数字をジュンク堂で検索するブックマークレット。
@2010-12-24 ISBN-10はチェックディジットが Xになることがあるんだった。修正。
スクリプト
void function() {
var isbn = (location.href.match(/\b[0-9]{9}[0-9X]\b/)||[])[0];
if (isbn) {
var url = "http://www.junkudo.co.jp/find.jsp?isbn="+ isbn;
open(url);
}
}();
URLエンコードしたもの
javascript:void%20function()%20{%20var%20isbn%20=%20(location.href.match(/\b[0-9]{9}[0-9X]\b/)||[])[0];%20if%20(isbn)%20{%20%20var%20url%20=%20"http://www.junkudo.co.jp/find.jsp?isbn="+%20isbn;%20%20open(url);%20}%20}();
@2013-04-29
24日に行われたらしいリニューアルの影響だろう。ISBN検索の URLが変わっててブックマークレットを実行してもトップページへ飛ぶ。
- トップページにある検索ボックス。ページを行って戻るたびに中身をクリアするな。
- トップページにある検索ボタンの隣の詳細検索ボタン。ボタンではなくリンクでないといけない。
- 詳細検索でISBNを検索したときに POSTしてるパラメータをフォームの ACTION(/mj/products/list.php, 検索結果ページ)に付加して GETしてもダメみたいなので、ブックマークレットはおしまい。なんで POSTでなければいけないと思ったんだろう。なんで GETであるべきだと考えなかったんだろう。
ユーザビリティとアクセシビリティの下がるリニューアルでしたね。買いたい本にね、たどり着けないんですよ。いちいちいちいち検索してカートに入れて検索してカートに入れて、やらないよ? あ、間違えた、と戻ったらまたイチから入力せんならんのですよ。
@2013-04-30 しょうもない。実にしょうもない。
void function() {
var h = function(text) {
var map = {"&":"&", "<":"<", ">":">", "\"":"""};
return text.replace(/[&<>"]/g, function(m0){ return map[m0]; })
};
var post = function(url) {
var _ = url.split(/[?;&]/);
var form = document.createElement("form");
form.method = "post";
form.acceptCharset = "utf-8";
form.action = _.shift();
for (var i = 0; i < _.length; ++i) {
var nv = _[i].split("=", 2);
_[i] = '<input type="hidden" name="'+h(nv[0])+'" value="'+h(nv[1])+'" />';
}
form.innerHTML = _.join("");
document.body.appendChild(form).submit();
};
var url_frag = "http://www.junkudo.co.jp/mj/products/list.php?zssearch_isbn=";
var isbn = (location.href.match(/\b[0-9]{9}[0-9X]\b/)||[])[0];
if (isbn) {
post(url_frag + isbn);
}
}();
動作することを Firefox 20.0でだけ確認。
javascript:void%20function(){var%20h=function(text){var%20map={"&":"&",%20"<":"<",%20">":">",%20"\"":"""};return%20text.replace(/[&<>"]/g,function(m0){return%20map[m0];})};var%20post=function(url){var%20_=url.split(/[?;&]/);var%20form=document.createElement("form");form.method="post";form.acceptCharset="utf-8";form.action=_.shift();for(var%20i=0;i<_.length;++i){var%20nv=_[i].split("=",2);_[i]='<input%20type="hidden"%20name="'+h(nv[0])+'"%20value="'+h(nv[1])+'"%20/>';}form.innerHTML=_.join("");document.body.appendChild(form).submit();};var%20url_frag="http://www.junkudo.co.jp/mj/products/list.php?zssearch_isbn=";var%20isbn=(location.href.match(/\b[0-9]{9}[0-9X]\b/)||[])[0];if(isbn){post(url_frag+isbn);}}();
詳細検索の ISBNの欄にはハイフン抜きの10桁または13桁っていう但し書きがあるけど、チェックディジットが Xの ISBN-10に対して詳細検索が本を見つけられない(普通の検索なら問題ない)。試したのは「477415654X」と「404886775X」と「404854473X」。どこまでも買わせないつもりなんだな(二度目の
@2013-09-25 やっと買える。
チェックディジットが Xの ISBN-10を詳細検索して本が見つけられるようになってた。5か月かかったね。
2010年01月31日 (日) PS3 + リーンベル + torne = 買うしか
最終更新: 2010-04-17T12:23+0900
♪ [javascript] JSLint
コマンドプロンプトで利用できる WSH版がある。
「JavaScriptの構文チェッカーJSLintをEmacsから使う - 檜山正幸のキマイラ飼育記」にならって、サクラエディタで、編集中の .jsファイルをチェックできるようにしよう。
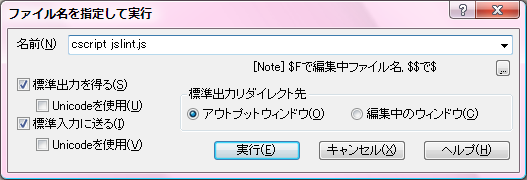
といっても、ダウンロードしてきた jslint.jsをパスの通った場所(ちょっと試してみるだけならエディタで開いているファイルと同じディレクトリ)に置いて、「ツール」>「外部コマンド実行」で「cscript jslint.js」と入力するだけだった。
jslint.js自身を開いた状態で実行した結果はこう。
#============================================================
#DateTime : 2010-02-01 06:44:29
#CmdLine : cscript jslint.js
#============================================================
Microsoft (R) Windows Script Host Version 5.7
Copyright (C) Microsoft Corporation 1996-2001. All rights reserved.
Lint at line 312 character 9: All 'debugger' statements should be removed.
debugger;if(!/^[A-Za-z][A-Za-z0-9._:\-]*$/.test(v)){warning("Bad id: '{a}'.",nexttoken,v);}else if(option.adsafe){if(adsafe_id){if(v.slice(0,adsafe_id.length)!==adsafe_id){warning("ADsafe violation: An id must have a '{a}' prefix",nexttoken,adsafe_id);}else if(!/^[A-Z]+_[A-Z]+$/.test(v)){warning("ADSAFE violation: bad id.");}}else{adsafe_id=v;if(!/^[A-Z]+_$/.test(v)){warning("ADSAFE violation: bad id.");}}}
終了コード: 1

- debuggerの使い道って何だろう。
- jslint.jsの copyrightは 2002年だけど、コメントを除いた一番最初に "use strict" なんて書いてある。それは「Final final final final draft Standard ECMA-262 5th edition」というタイトルの PDFファイルで少し前に見たものだ。実装が先にあったのか知らないけど、対応が早い!
- jslint.jsの出力は StdErrなんだけどサクラエディタはお構いなしに標準出力と合わせて取得している。面倒なことを考えずに済んで助かった。
2009年10月16日 (金) [SakuraEditor]「折り返ししている物理行末を、キーボードで左から右へ矩形選択しようとすると、次の物理行にカーソルが移動して意図した通りに選択できません」折り返されている行末へカーソルがたどり着いた瞬間、次の行の頭に移動していて右端の一列が選択できない。たしかに問題。折り返し込みの矩形選択とか、コピペしたときにどうなるのが正しいのか想像できないんだけど……。矩形選択は図形的な操作だから、折り返しがあろうが改行があろうが、右へ範囲を広げている最中にキャレットが左へ戻ってしまうというのが意外な感じはする。
最終更新: 2009-10-17T03:43+0900
♪ [javascript] 空文字列にマッチした後の lastIndexの値は IEの挙動が妥当。
var re = /\b/g; var match = re.exec( "012" ); alert( match.index ); //=> 0 alert( re.lastIndex ); //=> 0(ECMAScript仕様), 1(IE)
仕様では 何度 re.execを実行しても re.lastIndexが 0から増加しないから、re.execをループで実行するときにはマッチ結果が幅0のときに限り特別に lastIndexをインクリメントする処理が必要になる。
lastIndexが 1ではいけないの?
マッチの範囲は "0"の直前から "0"の直前までで、lastIndexは範囲の末尾の次の位置を指すもの。マッチの幅は0。
index = 0; lastIndex = 1; であればマッチ範囲は "0"(幅1)ということになってしまい正しくない。
index = 0; lastIndex = 0; であればマッチの幅が 0だということも、その位置が "0"の手前だということも表現できていて正しい気がする。
でも、lastIndexってパターンオブジェクトのプロパティ……
indexはマッチ結果のプロパティだけど、lastIndexはパターンオブジェクトのプロパティなのだ。match.index...re.lastIndexの範囲が正しいとか正しくないとかは考慮に値しないのではないか。
検索結果に影響があるかといえば、スクリプトエンジンが行ってくれないことを、スクリプトを書く人間が手作業で行っているだけなのだから影響はないだろう。
IEは至極まっとうな実装をしたと思う。
2008年12月23日 (火) 新☆はてブ < スクロールが重いからピンを抜いたのにカテゴリを選び直すだけで元に戻る鳥頭。そこは Cookieを使うべきところです。(潔癖症の人はどうせ拒否設定してるでしょう)
♪ [SHJS][javascript] SHJS-0.6がリリースされていた。(2008年12月15日)
アナウンスされている変更点は…… (注: 日本語部分は俺の勝手な訳のような注釈のようなもの)
December 15, 2008 - SHJS 0.6
SHJS 0.6 is available for download.
SHJS 0.6 includes several new features, improvements and bug fixes:
SHJS is now distributed under version 3 of the GNU General Public License. (Older releases of SHJS were distributed under version 2 of the GNU GPL.)
ライセンスが GPLv2から GPLv3へ変更。
Markup inside pre elements is now preserved.
PREタグの中の HTMLマークアップが保存される。(以前は Node.dataを再帰的に取り出したもの。乱暴にいうと PRE.{innerText|textContent}に相当するものが利用されていた。ver.0.5ではマークアップとして <br>のみが考慮されていた。)
Several new languages (from the latest release of GNU Source-highlight) are included: S-Lang, Scala, Java properties files, Desktop files, LSM (Linux Software Map) files, Xorg configuration files, RPM spec files, Haxe, LDAP files, GLSL, Objective Caml, Standard ML, JavaScript with DOM, and C (separate from the C++ language file).
最新の GNU Source-highlightから新しい言語ファイルを追加。JavaScriptには DOMキーワードを含んだ lang/sh_javascript_dom.jsが追加された。(sh_javascript_dom = sh_javascript + applicationCache|closed|Components|content|controllers|crypto|defaultStatus|dialogArguments|directories|document|frameElement|frames|fullScreen|globalStorage|history|innerHeight|innerWidth|length|location|locationbar|menubar|name|navigator|opener|outerHeight|outerWidth|pageXOffset|pageYOffset|parent|personalbar|pkcs11|returnValue|screen|availTop|availLeft|availHeight|availWidth|colorDepth|height|left|pixelDepth|top|width|screenX|screenY|scrollbars|scrollMaxX|scrollMaxY|scrollX|scrollY|self|sessionStorage|sidebar|status|statusbar|toolbar|top|window + alert|addEventListener|atob|back|blur|btoa|captureEvents|clearInterval|clearTimeout|close|confirm|dump|escape|find|focus|forward|getAttention|getComputedStyle|getSelection|home|moveBy|moveTo|open|openDialog|postMessage|print|prompt|releaseEvents|removeEventListener|resizeBy|resizeTo|scroll|scrollBy|scrollByLines|scrollByPages|scrollTo|setInterval|setTimeout|showModalDialog|sizeToContent|stop|unescape|updateCommands|onabort|onbeforeunload|onblur|onchange|onclick|onclose|oncontextmenu|ondragdrop|onerror|onfocus|onkeydown|onkeypress|onkeyup|onload|onmousedown|onmousemove|onmouseout|onmouseover|onmouseup|onpaint|onreset|onresize|onscroll|onselect|onsubmit|onunload)
Many other languages have minor improvements.
言語ファイルのアップデート。
Compressed .min.css stylesheets are now included in the distribution.
最小化した CSSファイルを同梱。(.jsも .cssも YUI Compressorを使用。ver.0.5までは .jsのみが JSMinで処理されていた)
Please note that the format of language-specific JavaScript files has changed in SHJS 0.6. JavaScript language files from version 0.6 will not work with sh_main.js from previous releases, and vice versa. Make sure you upgrade both the sh_main.js file and language-specific files.
古い言語ファイル(lang/*.js)と新しいメインスクリプト(sh_main.js)は互換性がない(逆も同じ)。両方入れ替えるべし。
大きな変更は <pre></pre>内の HTMLマークアップがシンタックスハイライト後も保存されること。(タグがたすき掛けになるときはどうするんだろ?)
言語ファイルの変更は小さくて、"next"、"regex"、"style"、"exit"というプロパティを持ったパターンオブジェクトが、3要素の配列になっている。
異種document対応が必要では? (sh_main.js)
function sh_highlightElement(element, language) {
sh_addClass(element, 'sh_sourceCode');
var originalTags = [];
var inputString = sh_extractTags(element, originalTags);
var highlightTags = sh_highlightString(inputString, language);
var tags = sh_mergeTags(originalTags, highlightTags);
// この documentFragmentはグローバル変数の document由来。
var documentFragment = sh_insertTags(tags, inputString);
while (element.hasChildNodes()) {
element.removeChild(element.firstChild);
}
// element.ownerDocument != documentFragment.ownerDocumentのとき失敗しませんか?
element.appendChild(documentFragment);
}
コメントを参照のこと。IEのバージョンが 5.5くらいだった時に失敗したような記憶が根拠で、確証はないし、レアケースだとは思うけど。(フレームをまたいで sh_highlightElement(element, language)を呼び出したとき(=スクリプトとエレメントが異なるドキュメントに属するとき)に起こるかなぁ?)
タグのたすき掛けの結果
before
<pre class="sh_ruby"> require 'sqlite3' <strong>require</strong> 'sqlite3' <strong>req</strong>uire 'sqlite3' </pre> <pre class="sh_javascript"> /* http://example.com http://example<em>.</em>com */ </pre>
after
<pre class="sh_ruby sh_sourceCode"> <span class="sh_preproc">require</span> <span class="sh_string">'sqlite3'</span> <strong><span class="sh_preproc">require</span></strong> <span class="sh_string">'sqlite3'</span> <strong><span class="sh_preproc">req</span></strong><span class="sh_preproc">uire</span> <span class="sh_string">'sqlite3'</span> </pre> <pre class="sh_javascript sh_sourceCode"> <span class="sh_comment">/*</span> <a href="http://example.com" class="sh_url">http://example.com</a> <a href="http://example.com" class="sh_url">http://example</a><em><a href="http://example.com" class="sh_url">.</a></em><a href="http://example.com" class="sh_url">com</a> <span class="sh_comment">*/</span> </pre>
SHJSの挿入するタグは必要に応じてぶつ切りにされるみたい。
追記@2009-02-25: 手製の言語ファイル( rubyと javascript)を 0.6フォーマットに変換した。(最小化方法は依然として JSMin)
- /shjs/0.6/lang/sh_javascript.js
- /shjs/0.6/lang/sh_javascript.min.js
- /shjs/0.6/lang/sh_ruby.js
- /shjs/0.6/lang/sh_ruby.min.js
移行スクリプトはこれ( migrate_05_06.js )。shjs-0.5までの lang/sh_*.jsファイルをドロップすると lang/sh_*.06.jsというファイルができてくるという寸法。ちなみに JScript製。
テストもかねてバージョン 0.6を走らせてみたけど、軽くなってる道理がない*ので、この日記では shjs-0.4.2に手を入れたものを使い続けている。
追記@2009-04-06: 0.6いいね。
言語ファイルのフォーマット変更は速度的に有利。
パターンマッチの結果を Stateをまたいで保存するようになっているので、この日記の sh_ruby.jsのようにあっちこっち跳びまわる言語ファイルに有利に働く。いちばん時間を消費しているのが RegExp.exec()と DOMツリーへの HTML断片の追加なのでパターンマッチ結果のキャッシュは大事。(もっとも 0.4.2のときからキャッシュの拡大は個人的にやっていた)
* <pre>内のマークアップを保存するためにハイライト前と後の、二つの HTML文字列をマージしている。でもその機能、俺個人はいらないのよね。
2008年10月24日 (金) [HTML] Logicoolのサイトはキーボードでもタブの切り替えができて偉い。(スクリプトをOFFにするとマウスを使ってさえ表示を切り替えられなくなったが……)
♪ [HTML][javascript] 補助に徹する賢い JavaScriptの使い方
基本はこう。
- HTMLのみで情報を配置する。
- CSSで見栄えを整える。
- スクリプトで効果やアクションを付け加える。
Logicoolのサイトのタブコントロールはキーボードインターフェイスを具えていて偉い、と書いたばかりだが、スクリプトがオフだと、タブの切り替えができないばかりか、タブの中身、肝心の情報が表示されないのはイクナイ。
スクリプトで各タブの表示・非表示を切り替えているのだろうが
- タブの状態のデフォルトは非表示
- スクリプトで一つだけを表示に切り替え
ではなく
- タブの中身はデフォルトで表示
- スクリプトで一つ以外を非表示に切り替え
が、より良いやり方ではないか。(一瞬全ての情報が表示されてすぐに消える、というのは気にすることではないと思っている)
ロジのサイトのこのスクリプトは見栄えをいじるだけなので、HTMLとスクリプトを切り離して、最初に HTMLのみでページを作り、スクリプトは後からアタッチするものだと考えて欲しかった。
スクリプトに依存する要素があって切り離せない場合は、Amazon.co.jpがやっているように
- <noscript>の中に、スクリプトを使わない代替 HTMLを用意する (できなければないで仕方がない)
- <script>の中で、スクリプトを必要とする要素を、スクリプトを使って配置する
方法が賢いと思っている。
ちょっとだけ関連
2008年05月27日 (火) [Firefox] 領域を選択してのソース表示は、スクリプトに書き換えられた最新の HTMLを反映しているのが便利。
♪ [Firefox][javascript][SHJS] <pre>が真っ白になり、黒色の領域が出現する。
例えばこのページ http://vvvvvv.sakura.ne.jp/ds14050/diary/20080112-7.html 。Endキーで末尾に移動して PageUpで戻っていくと空白の PREが目に入ると思う。その少し上にはページの内容を覆い隠す黒い領域があるはず。(そうでなければ修正されたのだろう。Firefox2で最初に確認し、Firefox3.0RC1でも直っていなかったが)
大量の PREが存在したり、一つだけでも巨大な PREが存在する場合に起こる様子。innerHTMLで PREの内容を置き換えているのも原因になっているかもしれない。
画面の末端にスクロールした状態でページをリロード(F5 or Ctrl+R)すると下方の PREが正常に表示される反面、上端付近の PREに同じ問題が生じる。遠方の PREの書き換えに問題があるのでは?
真っ白の PREの中で、右クリックしたりテキストを選択したりといったアクションを起こせば正常に表示されることが多い。
あと、PREの中から開始した選択は PREの外に出られなかったり。(これは TEXTAREAと違い PREでは Ctrl+Aで全文選択ができないために用意された代替手段だという気もする)
2008年05月14日 (水) DFAエンジンのマッチの仕組みは謎のまま残された。正規表現を利用する側からはコントロールできる部分が皆無で、常に同じ結果が返ってくるおもしろみのないものらしいけど、その魔法の実現方法は大いに知りたい。
♪ [正規表現][javascript][大型本] Jeffrey E.F. Friedl【詳説 正規表現 第3版】 オライリージャパン
読んだ。この日記で以前書いたようなこと(20080116p01, 20080111p01)は全て書いてあった。もちろんそれ以上に知らないこと(NFAのマッチングのしかた、NFA型正規表現エンジンに適用できる正規表現のチューニングの具体例、Unicodeサポート、Perl, .NET, Java, PHPの正規表現、\Gの使い方などなど)が書かれていた。
非常に読みやすい文章で書かれているし、必要なところでは必ず前後のページへの参照先が書かれている。章の始めには Overviewがあり、その章から読み始めた読者への配慮も忘れない。当たり前のことだけど、徹底されている。「まずこの本を読め。正規表現について話すのはそれからだ。」と言い切れる良い本。正規表現を初めて学ぶ人にも、効率について考える余地ができてくるほど既に正規表現を使っている人にも役に立つ。
すごく実用的なテクニックで、でも全く想像が及ばなかったものがある。168ページの「4.5.8.1 肯定の先読みを使ったアトミックグループの模倣」がそれ。
肯定の先読みを使ったアトミックグループの模倣
/(?>pattern)/ // アトミックグループを使ったパターン /(?=(pattern))\1/ // 先読みでアトミックグループを模倣したパターン
高機能化する他の実装にくらべて、昔のままの JavaScriptの正規表現はバックトラックを抑制する構文を持っていない。JavaScriptでは非常に有用。
20080116p01でも書いたが、次の終わらない正規表現
/"(?:[^\\"]+|\\.)*"/ // マッチに失敗するとき死ぬほど遅い
はアトミックグループや絶対最大量指定子が使えるなら次のように書けるが JavaScriptは両方ともサポートしていない。
/"(?:[^\\"]+|\\.)*+"/ // JavaScriptでは使えない /"(?>(?:[^\\"]+|\\.)*)"/g // JavaScriptでは使えない /"(?:[^\\"]++|\\.)*"/ // JavaScriptでは使えない。※上2つとは少し意味が違う
次のように先読みでアトミックグループを模倣すると組み合わせの爆発を避けることができる。
/"(?=((?:[^\\"]+|\\.)*))\1"/ /"\1"/ // 上のパターンから先読み部分を取り除いたもの。
先読みを取り除いたパターンを見ると一目瞭然だが、引用符がペアになっていなくて \1 の後ろの " のマッチに失敗したとしても戻る場所がない。あるのは " と \1 にマッチしたという結果で、どちらもオプションではないので取り消すことはできず、繰り返しでもないのでマッチした部分を少しずつ手放させることもできない。なので、ちょっとずつ後じさりしながら延々とあらゆる組み合わせのマッチを試行することなしに、マッチが失敗に終わったことが即座に判断できるようになるというわけ。本物のアトミックグループよりは劣るが効率も悪くない。同じ働きをする次の二つのパターンとかかる時間を比較してみた。
/"[^\\"]*(?:\\.[^\\"]*)*"/ /"(?:[^\\"]|\\.)*"/
手順
バックトラックによる組み合わせの爆発が起きない 3つのパターンでかかる時間を比較。3回実行した。(3回繰り返しても一回一回の中の試行順が固定されていたら傾向は同じになるわな。無意味。あてみやむいみ)
var re = [
/"(?:[^\\"]|\\.)*"/,
/"(?=((?:[^\\"]+|\\.)*))\1"/,
/"[^\\"]*(?:\\.[^\\"]*)*"/
];
var s = [
'"'+ new Array(5000+1).join('\\"'), // 1/100
'"'+ new Array(500000+1).join('\\"') +'"',
'"'+ new Array(500000+1).join("\\'"),
'"'+ new Array(500000+1).join("\\'") +'"',
'"'+ new Array(500000+1).join('a'),
'"'+ new Array(500000+1).join('a') +'"'
];
var results = [];
for(var j = 0; j !== s.length; ++j) {
var result = [];
for(var i = 0; i !== re.length; ++i) {
var t0 = new Date();
var m = re[i].exec(s[j]);
result[i] = new Date() - t0;
}
results[j] = result;
}
WScript.Echo(results.join("\n"));
結果
数の単位は msec。
| パターン1 | パターン2 | パターン3 | |||
| 工夫なし | アトミックグループの模倣 | ループ展開 | |||
| /"(?:[^\\"]|\\.)*"/ | /"(?=((?:[^\\"]+|\\.)*))\1"/ | /"[^\\"]*(?:\\.[^\\"]*)*"/ | |||
|---|---|---|---|---|---|
| 文字列1 | マッチしない(F) | "\"\"......\"\" | 2910×100, 2928×100, 2914×100 | 2551×100, 2581×100, 2595×100 | 2372×100, 2387×100, 2377×100 |
| マッチする(T) | "\"\"......\"\"" | 124, 124, 124 | 138, 137, 134 | 108, 107, 108 | |
| 文字列2 | マッチしない(F) | "\'\'......\'\' | 138, 140, 151 | 125, 127, 125 | 122, 118, 118 |
| マッチする(T) | "\'\'......\'\'" | 138, 126, 126 | 140, 128, 133 | 135, 105, 106 | |
| 文字列3 | マッチしない(F) | "aa..........aa | 174, 172, 166 | 14, 11, 13 | 96, 90, 92 |
| マッチする(T) | "aa..........aa" | 155, 119, 126 | 32, 15, 14 | 15, 12, 11 | |
みどころ
- マッチに失敗するときの、成功するときに比べた遅さ。
- パターン2は例外
- パターン2(アトミックグループの模倣)ではしばしばマッチに失敗する方が速い。
- \1のマッチが成功だと判断するにはキャプチャした長い長い文字列を最後までたどって比較する必要があるため、\1のマッチに失敗するほうが速くなる?
- 文字列1Fの特筆すべき遅さ。
- 遅いとはいえ「終わらない」と形容するほど遅くはない。(これでも!)
- 文字列長に比例したバックトラックが行われているせい?
- 文字列2Fの結果と比較するに、\" という形で " が文字列の途中に含まれていることが最適化を阻んでいる?
- パターン3(ループ展開)は特定の場合を除いてパターン2(アトミックグループの模倣)より若干速い。
- ループ展開は『詳説 正規表現』に載っていた言葉。
- 特定の場合とは文字列3Fのことで、不用意なパターンを用いると処理が終わらなくなる場合のこと。
- パターン2(アトミックグループの模倣)は、(今回の眼目である)組み合わせの爆発が起こるような場合に、顕著な速さを見せる。
- 他の文字列ではパターン3(ループ展開)に半歩譲るが。
ところで、文字列1Fがどのパターンでも一様に遅いのは文字列長に比例したバックトラックが行われているからなんだろうが、パターン2(先読みによるアトミックグループの模倣)でもそれを抑制できていないのは、なんとかできないものか。それでこそ若干のオーバーヘッドをのんででもアトミックグループの模倣を採用する理由になるのだが。