2009年01月22日 (木) Ruby-1.9.1-RC2出ました。
♪ [tDiary] tDiary on Ruby-1.9.1-rc2 -> Encoding::CompatibilityError
#<Encoding::CompatibilityError: incompatible character encodings: UTF-8 and ASCII-8BIT> (plugin/00default.rb):571:in `comment_form_text' (plugin/00default.rb):616:in `comment_form' (TDiary::Plugin#eval_src):79:in `block in eval_src' Y:/server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:787:in `eval' Y:/server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:787:in `block in eval_src' Y:/server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:112:in `block in safe'
なにが ASCII-8BITだったかというと Cookie。
plugin/00default.rb:575: #{comment_name_label}:<input class="field" name="name" value="#{h( @conf.to_native(@cgi.cookies['tdiary'][0] || '' ))}">
ならばと UTF-8への変換を試みたならば
@cgi.cookies['tdiary'][1].encode("utf-8")
#=> #<Encoding::UndefinedConversionError: "\xE3" from ASCII-8BIT to UTF-8>
クッキーみたいに何が送られてくるかわからないものは、慎重に慎重にエラーに備えて取り扱わないといけない、ということですね。(面倒くさいなー)
CGIパラメータなんかも、取り扱い注意、だよね。cgi.rbの支援はないのかな?(他力本願)
補足。エラーの原因の心当たり。
「Testing tDiary on Ruby1.9.1」と題した日記にも関わらず、少しの間、うっかり 1.8.7で動かしていた。そのせいでキャッシュが原因のエラーが出たし、キャッシュを削除したら今度はクッキーが原因のエラーが出たという次第。
サーバーの Rubyを 1.8.7から 1.9.1にアップデートしたタイミングでそのサーバーの日記を閲覧できなくなる人(過去3か月間にコメントした人限定)が続出、とか。ないだろうか。
追記@2009-01-24: Ruby-1.9での cgi.rbとその代替(Rack)。
cgi.rbも変わっていたのでした。
どちらも日付が今日(2009-01-24)だ! Googleクローリング早い。
tDiaryの文脈で Rackの名前を見かけてたんだけど、名前から Rakeのようなものを想像していた。Web方面だったのね。
2009年01月19日 (月) Wassrという Webサービスがあって、そこに tDiaryというチャンネルがあって、Firefoxにはライブブックマークとかいうものがあって、と、いろいろなものを発見。(コミットログの確認が svk sync + viewvcより簡単だ。古い記事がちょこちょこ投稿されると思ったら delicious..から tDiaryタグの付いた URLを拾っているとか。ほへー)
♪ [Ruby][tDiary] requireと $SAFE=1と汚染された $LOAD_PATH
>irb
irb(main):001:0> RUBY_DESCRIPTION
=> "ruby 1.8.7 (2008-05-31 patchlevel 0) [i386-mswin32_90]"
irb(main):002:0> $SAFE=1
=> 1
irb(main):003:0> $:.unshift "hoge".taint
=> ["hoge", "C:/Program Files (x86)/ruby/lib/ruby/site_ruby/1.8",..., "."]
irb(main):004:0> require 'cgi'
SecurityError: Insecure operation - require
from (irb):4:in `require'
from (irb):4
from :0
irb(main):005:0>
1.8.7でもこうなのだから知らない俺が抜けているのだが、$SAFE=1のときに汚染された文字列を $LOAD_PATHに追加する(pushでも unshiftでも)と、一切の requireができなくなる。
期待したいのは、hoge/cgi.rbや hoge/cgi.soなどが存在するときには、このパスは汚染されているので SecurityError。存在しないときはファイルの探索を続けて C:/Program Files (x86)/ruby/lib/ruby/1.8/cgi.rb (このパスは汚染されていないはず)を読み込む、という動作なのだけど……。
実際はそうではないのだから tDiaryの
tdiary.rb:12: $:.insert( 1, File::dirname( __FILE__ ) + '/misc/lib' )
というのは __FILE__ が汚染されているときに、わりと危険な操作ということになる。問題が起きないのは SAKURAのレンタルサーバの Rubyが 1.8.6だからなのか、__FILE__、File.dirname(__FILE__) が汚染されていることが稀だからなのか。(汚染されていることが実際にあるのは、20090117p01で書いたように、untaintすることで状況が改善したことから推測できる)
問題が起きないのは SAKURAのレンタルサーバの Rubyが 1.8.6だからなのか、__FILE__、File.dirname(__FILE__) が汚染されていることが稀だからなのか。
両方でした。__FILE__が汚染されているのは Ruby-1.9.1RC1だから(多分)。
$SAFE=1のときに汚染された文字列を $LOAD_PATHに追加する(pushでも unshiftでも)と、一切の requireができなくなる。
書きながら誇張だとは気付いていたのだけど(一切の、の部分が)、そうでない例を自分で見つけたので追記(2009-02-02)。
Windowsで、フルパスで、あるいは拡張子(.rb)なしのフルパスでなら requireできる。
Y:\...\Desktop\a>irb
irb(main):001:0> RUBY_DESCRIPTION
=> "ruby 1.8.7 (2008-05-31 patchlevel 0) [i386-mswin32_90]"
irb(main):002:0> $SAFE=1
=> 1
irb(main):003:0> $:.push "".taint
=> ["C:/Program Files (x86)/ruby/lib/ruby/site_ruby/1.8", "C:/Program Files (x86)/ruby/lib/ruby/site_ruby/1.8/i386-msvcr90", "C:/Program Files (x86)/ruby/lib/ruby/site_ruby", "C:/Program Files (x86)/ruby/lib/ruby/vendor_ruby/1.8", "C:/Program Files (x86)/ruby/lib/ruby/vendor_ruby/1.8/i386-msvcr90", "C:/Program Files (x86)/ruby/lib/ruby/vendor_ruby", "C:/Program Files (x86)/ruby/lib/ruby/1.8", "C:/Program Files (x86)/ruby/lib/ruby/1.8/i386-mswin32_90", ".", ""]
irb(main):004:0> require "a"
SecurityError: Insecure operation - require
from (irb):4:in `require'
from (irb):4
from :0
irb(main):005:0> require "a.rb"
SecurityError: Insecure operation - require
from (irb):5:in `require'
from (irb):5
from :0
irb(main):006:0> require "./a.rb"
SecurityError: Insecure operation - require
from (irb):6:in `require'
from (irb):6
from :0
irb(main):007:0> require "Y:/.../Desktop/a/a"
=> true
irb(main):008:0> require "Y:/.../Desktop/a/a.rb"
=> false
irb(main):009:0> require "a"
SecurityError: Insecure operation - require
from (irb):9:in `require'
from (irb):9
from :0
irb(main):010:0>
2009年01月17日 (土)
♪ [Ruby][tDiary] 昨日(「引き続き rexml/source.rb:16の requireが SecurityErrorになる原因を探る」)の続き。
step1 load.c:147 (rb_feature_p) if (!load_path) load_path = rb_get_expanded_load_path(); step2 load.c:44 (rb_get_expanded_load_path) VALUE path = rb_file_expand_path(RARRAY_PTR(load_path)[i], Qnil); step3 Insecure Operation - require (SecurityError)
いました。Ruby1.9.1で SecurityErrorを量産する rb_get_expand_path()が。どうも、汚染された load_pathの一つを展開しようとして SecurityErrorになってる気がする。
$:($LOAD_PATH)の要素が汚染されてるのは、こちらの責任では?と思って確かめてみた。
SecurityErrorの直前で、$:の各要素が tainted?かどうかを TDiary::Config#debugを使って出力した結果。
D, [2009-01-17T23:36:46.289008 #1212] DEBUG -- : false Y:/server_root/www/ds14050/tdiary_on_ruby191 D, [2009-01-17T23:36:46.289008 #1212] DEBUG -- : true Y:/server_root/www/ds14050/tdiary_on_ruby191/misc/lib D, [2009-01-17T23:36:46.289008 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/site_ruby/1.9.1 D, [2009-01-17T23:36:46.289985 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/site_ruby/1.9.1/i386-msvcr90 D, [2009-01-17T23:36:46.289985 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/site_ruby D, [2009-01-17T23:36:46.289985 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/vendor_ruby/1.9.1 D, [2009-01-17T23:36:46.289985 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/vendor_ruby/1.9.1/i386-msvcr90 D, [2009-01-17T23:36:46.290961 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/vendor_ruby D, [2009-01-17T23:36:46.290961 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/1.9.1 D, [2009-01-17T23:36:46.290961 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/1.9.1/i386-mswin32_90 D, [2009-01-17T23:36:46.290961 #1212] DEBUG -- : false .
ひとつ、ありましたね。tDiaryが該当パスを $LOAD_PATHに挿入する部分で、下のように untaintをつけるだけで理不尽な SecurityErrorが解決しました。(ただし、ASRでは依然 SecurityErrorになる。解決したのは、20090116p01で書いたように、load.cの 501行目をコメントアウトした Ruby-1.9.1RC1での話)
{kind=link}
{kind=link}
-tdiary.rb:12: $:.insert( 1, File::dirname( __FILE__ ) + '/misc/lib' ) +tdiary.rb:12: $:.insert( 1, File::dirname( __FILE__ ).untaint + '/misc/lib' )
今回の一連の流れ(20090113p01、20090114p01、20090116p01)で、$SAFE=1が、SecurityErrorで使い物にならなくなる(>添付ライブラリの requireにも失敗する)、二つのルートが見つかった。それらは requireするライブラリの拡張子を明示したり、$LOAD_PATHの中身をすべて untaintすることで回避できたり、load.cの一行をコメントアウトしたりで回避できたが、スクリプトで対処すべきものではないと考える。file_expand_pathが $SAFE>0のとき、汚染された入力を一切受け付けないという前提のもと、(rb_)file_expand_pathを呼び出しているコードを見直すか、file_expand_pathが汚染された入力を受け入れて適切に処理するか、どちらかの変更が必要だと思う。「file_expand_path()の結果が汚染された入力や $LOAD_PATHの汚染された一要素に基づくとき、その展開されたパスも汚染されている。」「$SAFE=1のとき、最終的に requireするファイルのパスが、汚染された引数や、$LOAD_PATHの汚染された要素に基づくとき、SecurityError。」というのではいけないのだろうか。Ruby-1.8.7はそのへんうまくやっているのだが……。
改めてドキュメントを読んだら、汚染された文字列を引数にした Fileのクラスメソッド、インスタンスメソッドは禁止されていた。($SAFE=1のとき)
ドキュメントに従うなら rb_file_expand_pathが SecurityErrorを出すのは正しいのかも(Ruby-1.8.7がまちがっている)。それならば、$LOAD_PATHの汚染された要素を不用意に展開しようとして SecurityErrorを出したり(load.c:44:rb_get_expanded_load_path)、もともと汚染されていなかった文字列を複数回展開しようとして SecurityErrorを出したり(load.c:501:search_required)するほうを修正しなければ。
私見では、(最下層で実際の仕事を行う)file_expand_pathは汚染フラグを適切に伝播させるものの SecurityErrorは出さないでおき、(スクリプトから呼ばれる)File.expand_pathの実体である rb_file_s_expand_pathか、file_expand_pathに仕事を丸投げする rb_file_expand_pathでセーフレベルに基づくチェックを行うのが、呼び出し側にとって便利だと思う。
tDiaryのプラグインの recent_list.rbを書き換えたのは、今思えば不要だったみたいだ。(Rubyの方が変わるに違いないもの)
2009年01月16日 (金)
♪ [Ruby][tDiary] Ruby1.9.1RC1で「Insecure Operation - require (SecurityError)」が頻発する原因。
20090113p01や20090114p01で発生したエラーを起こす最小のスクリプトとそれを回避する方法。
>type a.rb
puts "a.rb required."
>ruby19 -v
ruby 1.9.1 (2008-12-30 patchlevel-0 revision 21203) [i386-mswin32_90]
>ruby19 -e "$SAFE=1; require 'a'"
-e:1:in `require': Insecure operation - require (SecurityError)
from -e:1:in `<main>'
>ruby19 -e "$SAFE=1; require 'a.rb'"
a.rb required.
二つの違いは requireするライブラリの拡張子(.rb)を明示しているかどうか。拡張子なしの場合に発生する SecurityErrorは間違いだと思う。そうでないと $SAFE = 1がまるで使い物にならない。添付ライブラリだってまともに動かなくなるんだから。
ところで、Ruby 1.9 - 1.9.1 RC2 issues - Ruby Issue Tracking Systemにはチケットを作成するためのフォームがない。ruby-dev MLはアーカイブをときどき閲覧しているが購読はしていない。是非ともこの SecurityErrorは消して欲しいのだが、報告を受け付ける間口が狭い。直通ルートがない。どうすべ。
どうすべ、と言ってる間に原因究明。
load.c:500: type = rb_find_file_ext(&tmp, loadable_ext); load.c:501: tmp = rb_file_expand_path(tmp, Qnil);
501行目が不要に思える。そしてこれが SecurityErrorの原因。rb_find_file_extは内部で rb_file_expand_pathや file_expand_pathを呼び、その結果を tmpにコピーしてくれている。二度目を呼ぶ必要はないのでは? rb_file_expand_pathは適宜汚染されたStringオブジェクトを返し、また $SAFE>0のとき、汚染された引数を SecurityErrorで拒絶するので、複数回の (rb_)file_expand_path呼び出しは容易に SecurityErrorを引き起こす。これは Ruby1.9.1の、Ruby1.8.7とは異なっている動作。
>irb
irb(main):001:0> File.expand_path("a")
=> "Y:/a"
irb(main):002:0> File.expand_path("a").tainted?
=> true
irb(main):003:0> File.expand_path(File.expand_path("a"))
=> "Y:/a"
irb(main):004:0> $SAFE=1
=> 1
irb(main):005:0> File.expand_path(File.expand_path("a"))
=> "Y:/a" # $SAFE>0で、taintedな文字列でも展開する。(Ruby1.8.7)
irb(main):006:0> exit
>irb19
irb(main):001:0> File.expand_path("a")
=> "Y:/a"
irb(main):002:0> File.expand_path("a").tainted?
=> true
irb(main):003:0> File.expand_path(File.expand_path("a"))
=> "Y:/a"
irb(main):004:0> $SAFE=1
=> 1
irb(main):005:0> File.expand_path(File.expand_path("a"))
# $SAFE>0で、taintedな文字列を引数にすると SecurityError (Ruby1.9.1RC1)
SecurityError: Insecure operation - expand_path
from (irb):5:in `expand_path'
from (irb):5
from C:/Program Files (x86)/ruby/bin/irb19.bat:20:in `<main>'
irb(main):006:0>
問題設定が間違っていたのか? load.cの一行をコメントアウトしたことで、たしかに一つの SecurityErrorは消えたが tDiaryは動かない。20090114p01のエラーがまだ出る。
ただ、20090114のタイトルにちらっと書いた、open-uriの SecurityErrorはでなくなってる。
>irb19 (野良パッチ済み) irb(main):001:0> $SAFE=1 => 1 irb(main):002:0> require 'open-uri' => true irb(main):003:0> open 'http://www.example.com' => #<StringIO:0x2b8e924> irb(main):004:0>
比較として ASRでエラーが出るのを確認する。ただ、ASRでも二回目以降の openはエラーにならない。謎の挙動。この SecurityErrorも本来発生すべきものではないのだろう。
>"C:\Program Files (x86)\ActiveScriptRuby-1.9.1\bin\irb.bat"
irb(main):001:0> $SAFE=1
=> 1
irb(main):002:0> require 'open-uri'
=> true
irb(main):003:0> open 'http://www.example.com'
SecurityError: Insecure operation - write
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:375:in `write'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:375:in `<<'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:375:in `<<'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:322:in `block (3 levels) in open_http'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/protocol.rb:373:in `call_block'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/protocol.rb:364:in `<<'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/protocol.rb:88:in `read'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:2333:in `read_body_0'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:2288:in `read_body'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:321:in `block (2 levels) in open_http'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:1120:in `block in transport_request'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:2251:in `reading_body'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:1119:in `transport_request'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:1103:in `request'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:312:in `block in open_http'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:564:in `start'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:306:in `open_http'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:767:in `buffer_open'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:203:in `block in open_loop'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:201:in `catch'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:201:in `open_loop'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:146:in `open_uri'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:669:in `open'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:33:in `open'
from (irb):3
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/bin/irb.bat:21:in `<main>'
irb(main):004:0> open 'http://www.example.com'
=> #<StringIO:0x2b611a4>
irb(main):005:0>
引き続き rexml/source.rb:16の requireが SecurityErrorになる原因を探る。(tDiaryを起動しないと再現させられないのが辛い)
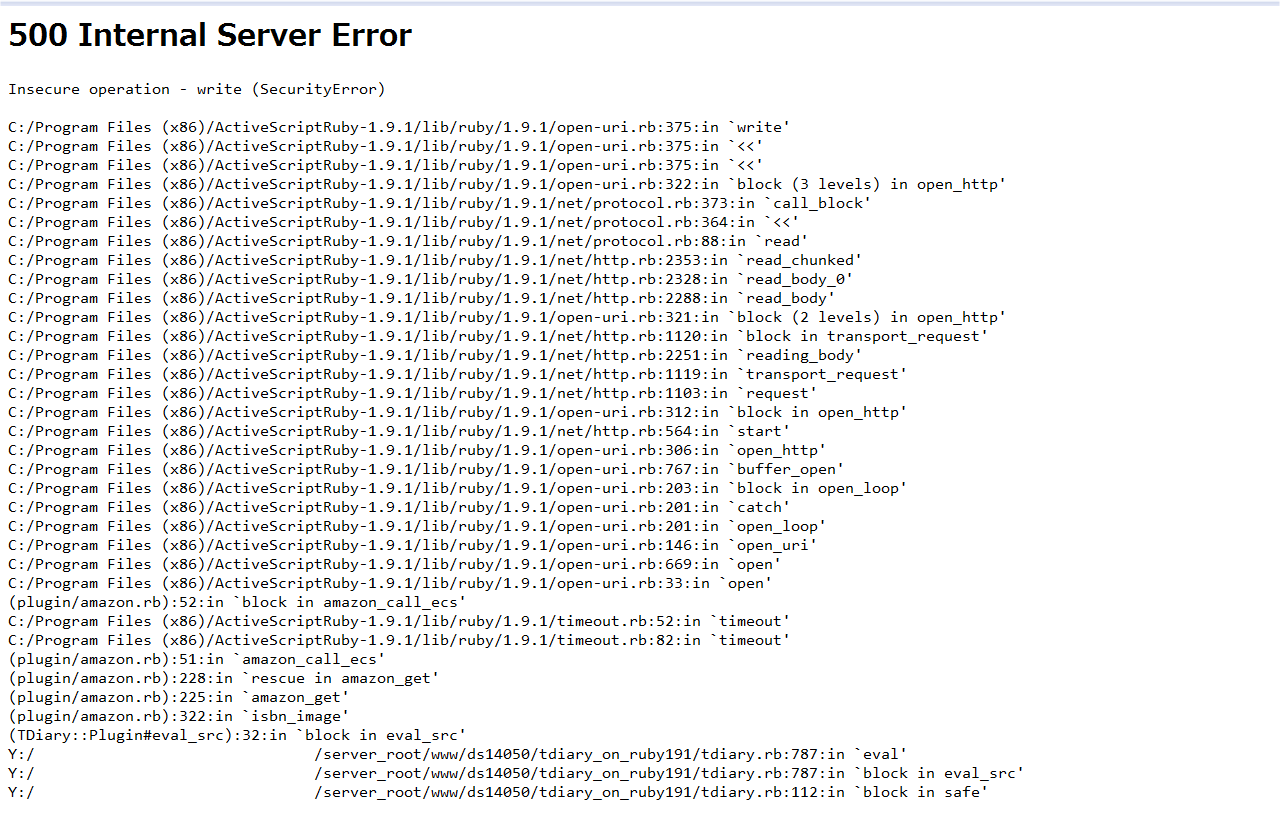
2009年01月14日 (水) $SAFE=1だと添付ライブラリ(open-uri)が SecurityErrorを出しまくるんだけど……。260行目の require 'net/http' で出る。375行目の StringIOに書き込むところでも出る。破綻してる気がする。
♪ [tDiary][Ruby] 昨日のつづき。recent_listを実際に修正。
方針は昨日書いたとおり、プラグインが自由に日記データを取得できる手段を提供した。
日記を一日書いたとたんにエラーということはなくなったみたい。

$SAFE=1で requireが失敗する(ファイル名の untaintもしているのに)のがそもそもおかしい。open-uriや rexmlで同様に requireで SecurityErrorエラーが生じていることからも、疑惑の目がウチの Rubyに向いてきた。「1.9.1RC1だから」ではなく「ウチでコンパイルしたから」、あるいは(開発者に)利用者が少なそうな 「Windows(それも Vista)だから」なのかもしれない。
ASRをインストールしてみたけどダメだった。同じ。tDiaryをセキュアモードで動かしているわけではないので Rubyのセーフレベルは最高でも 1。taintedな文字列を使った requireが失敗するならわかる。でも rexml/source.rbの 16行目は「require 'stringio'」だ。べったべたのリテラルだ。
500 Internal Server Error Insecure operation - require (SecurityError) C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/source.rb:16:in `require' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/source.rb:16:in `create_from' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/parsers/baseparser.rb:146:in `stream=' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/parsers/baseparser.rb:123:in `initialize' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/parsers/treeparser.rb:9:in `new' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/parsers/treeparser.rb:9:in `initialize' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/document.rb:228:in `new' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/document.rb:228:in `build' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/document.rb:43:in `initialize' (plugin/amazon.rb):231:in `new' (plugin/amazon.rb):231:in `amazon_get' (plugin/amazon.rb):322:in `isbn_image' (TDiary::Plugin#eval_src):32:in `block in eval_src' Y:/.../server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:787:in `eval' Y:/.../server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:787:in `block in eval_src' Y:/.../server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:112:in `block in safe'
2009年01月13日 (火)
[Vista] >clipboard 'clipboard' は、内部コマンドまたは外部コマンド、操作可能なプログラムまたはバッチ ファイルとして認識されていません。 >clip 情報: "CLIP /?" と入力すると使用法が表示されます。 >clip /? コマンド ライン ツールの出力を Windows クリップボードにリダイレクトします。(やっぱりあるよねー。手コピしなくてすんでよかった。なお XPには……)
最終更新: 2015-07-09T23:54+0900
♪ [tDiary][Ruby] Insecure operation - require (SecurityError)
tdiary/trunk (r3394) を ruby 1.9.1 (2008-12-30 patchlevel-0 revision 21203) [i386-mswin32_90] で動かしてみた。
dot.htaccessと tdiary.conf.beginnerを編集&リネームして、トップページの表示と一通りの設定変更を済ませて、記念すべき最初の書き込み。……トップページすら表示されなくなりました。
Insecure operation - require (SecurityError) Y:/.../tdiary_on_ruby191/tdiary.rb:434:in `require' Y:/.../tdiary_on_ruby191/tdiary.rb:434:in `block in load_styles' Y:/.../tdiary_on_ruby191/tdiary.rb:433:in `glob' Y:/.../tdiary_on_ruby191/tdiary.rb:433:in `load_styles' Y:/.../tdiary_on_ruby191/tdiary/defaultio.rb:142:in `initialize' Y:/.../tdiary_on_ruby191/tdiary.rb:1069:in `new' Y:/.../tdiary_on_ruby191/tdiary.rb:1069:in `initialize' Y:/.../tdiary_on_ruby191/tdiary.rb:1660:in `initialize' Y:/.../tdiary_on_ruby191/tdiary.rb:1858:in `initialize' (plugin/recent_list.rb):39:in `new' (plugin/recent_list.rb):39:in `block (3 levels) in recent_list' (plugin/recent_list.rb):37:in `reverse_each' (plugin/recent_list.rb):37:in `block (2 levels) in recent_list' (plugin/recent_list.rb):36:in `reverse_each' (plugin/recent_list.rb):36:in `block in recent_list' (plugin/recent_list.rb):35:in `catch' (plugin/recent_list.rb):35:in `recent_list' (TDiary::Plugin#eval_src):67:in `block in eval_src' Y:/.../tdiary_on_ruby191/tdiary.rb:787:in `eval' Y:/.../tdiary_on_ruby191/tdiary.rb:787:in `block in eval_src' Y:/.../tdiary_on_ruby191/tdiary.rb:112:in `block in safe'
プラグイン:recent_listが原因。(外したら解決した)
$SAFE==1の状況で TDiaryMonth.new()するのがダメっぽい。
recent_list()を呼ばれたときに、そのたびに、TDiaryMonth.new()するんでなくて、読み込まれたときに必要なデータを準備しておけばいいんじゃないか、とか思ったけど、evalで TDiaryMonthクラスにアクセサを追加したりしているあたり*、反則。泥縄の対応では気が済まない。プラグインが日記データを要求できるようなインターフェイスが求められている(現在は TDiaryXXXX#initializeで読み込まれたもののみ、Plugin@diariesからアクセスできる)。然るべき手段を用意したのち、recent_list.rbはそれを利用するべき。
* 歴史的経緯>http://kitaj.no-ip.com/tdiary/20021106.html#p03
2008年11月19日 (水)
♪ [買][tDiary] 洋書の書影を出すのは難しいな。
 映画でもハンバート ハンバートを演じたジェレミー アイアンズが朗読します。驚きの CD10枚組、その収録時間や 11時間半。コストパフォーマンス高すぎです。
映画でもハンバート ハンバートを演じたジェレミー アイアンズが朗読します。驚きの CD10枚組、その収録時間や 11時間半。コストパフォーマンス高すぎです。
 本当は子供向けの Audiobookを探していたのです。不思議の国のアリスとか赤毛のアンとか秘密の花園を狙っています。アリスは言い回しが難しそうなのでまずはこの Anne of Green Gables。3枚組 4時間。朗読ではなく、BGMあり、キャストありのドラマCD風。きかん気が強そうで、口の減らなそうなアンの声が素敵。
本当は子供向けの Audiobookを探していたのです。不思議の国のアリスとか赤毛のアンとか秘密の花園を狙っています。アリスは言い回しが難しそうなのでまずはこの Anne of Green Gables。3枚組 4時間。朗読ではなく、BGMあり、キャストありのドラマCD風。きかん気が強そうで、口の減らなそうなアンの声が素敵。
SearchIndexを Books決めうちではなく ForeignBooksとの二択にする必要があるのだけど、978-4-*********が Foreignか否かは、どの国の Amazonを利用するつもりかで変わってくる。とりあえず Amazon.co.jpの利用を前提とした変更を amazon.rbに施して、書影の表示にこぎ着けた。(さらに、ISBN-13の頭が 978だけしかない期間限定の対応だけど)
url << "&SearchIndex=#{'Foreign' if /\A(978)?4/ !~ asin}Books" if id_type == 'ISBN'
2008年07月18日 (金) 二重ブラケットの中でもマークアップが使える。ところで | を \ でエスケープできるんだけど \ が消費されない……。
♪ [tDiary][Hiki] 引用元の URLと説明を HikiDocで書けるように。
こう書くと
""[[http://vvvvvv.sakura.ne.jp]] ""どこからの引用だかわかるでしょうか? "" ""すくなくとも Firefox3、Safari3.1、Opera9.50ではわかるはずですが、IE7では無理です。
こうなる。
どこからの引用だかわかるでしょうか?
すくなくとも Firefox3、Safari3.1、Opera9.50ではわかるはずですが、IE7では無理です。
HTMLはこんな感じになっている。
<blockquote cite="http://vvvvvv.sakura.ne.jp">...</blockquote>
スタイルシートはこう。残念な子 IE7は contentをサポートしていないのが敗因。
.section blockquote[cite]:after,
.section blockquote[title]:after {
content: "引用元: "attr(title)" "attr(cite); /* ハイパーリンクにしたい。マークアップもしたい。 */
display: block;
text-align: right;
font-style: oblique;
background-color: #F3F9FF;
}
引用の最初の行が二重ブラケットリンクだけだった場合に限り、その中身を <blockquote>の cite/title属性として扱う。こういうパターンがあり得る。
URLANDTITLETITLEONLYhttp://URLONLY
2008年04月17日 (木) JavaScriptと HTMLを初めてさわったのは Win98の「フォルダのカスタマイズ」。WMPを埋め込んで試聴できるようにしたり。
♪ [tDiary][Ruby] CGI.escape と ERB::Util.u の違い
- 「 」が「%20」になる。(ERB::Util.u)
- 「 」が「+」になる。」(CGI.escape)
気付いたのは日記を書くときに、カテゴリ名入力支援機能(クリックすると本文にカテゴリが挿入される*)のカテゴリリストに目当てのカテゴリがなかったから。
脱線。何かのソースを見たときに思ったのだけど ERB::Util.u も CGI.escape もエンコードしすぎだと感じてる人がいるみたい。(一部の記号をわざわざ復号していた。たしかに %XX が URLに現れるのは美しくない⁑)
閑休。存在するはずのカテゴリファイルがなくてエラーを出していたのは、ここ(20071208p01)で自分が書いた tdiary/categorizedio.rb だったので誰にでも起こる不具合なのか確証がなかったり。
http://tdiary-users.sourceforge.jp/cgi-bin/wforum/wforum.cgi?mode=allread&no=5718&page=0
tDiary標準のカテゴリモードがどのようになるのかは未確認だったり。
複数のポストを日付で括ってしまう tDiary(<日記だから)はどうしても <title>タグの中身が味気なくなってしまって、ボットにも人間にもアピールが弱いな、とか全然関係ないけど、いま思った。(BlogKitでは解決してそう)
ぼそり。(category.rbは @conf.data_pathと 'category'を連結するときにパスセパレータを二重化してる。問題はレンタルサーバ(FreeBSD)でもローカル(Windows)でも起きていないが、そういうのが気持ちわるい&気にしたくないので自分は File.joinや Scripting.FileSystemObject.BuildPathを必ず使う)
2008年03月08日 (土)
♪ [tDiary] 続・tDiary UTF-8化 (>前回)
tDiary-devel MLより
「すでにUTF-8で運用している日記に対して、このパッチ込みのtDiaryを起動すると、さらに(EUC-JP→UTF-8決め打ちな)文字コード変換をかけようとして大変なことになります」のでご注意ください。
今から思えば、migrate.rbでの変換時や、Test_UTF8ブランチの時から、何らかのしるしをCGI生成のtdiary.confかどこかにうめこんでおくべきでした。
そんな気がしていました > UTF-8化済みのデータを EUC-JP->UTF-8変換。
だから一日待って勝手に変換してくれるのに任せようとしていた。
ダウンロードした tarballが期待したものより古かったと気付いたものの UTF-8化を最後まで行った後では、migrate.rbが印を埋め込んでいてくれることに期待していた。
漠然とした不安は肯定され、期待していた救いは否定された。
最新の tDiaryを調べて手動で印を埋め込むまでアップデートは危険。
このパッチは trunkに適用されたわけではなかった。早とちり。
というわけで必要がなくなってしまったけれど書いておくと、
tdiary_version = "2.3.0.20080302"
という行(インデントしてはいけない)を data_pathにある方の tdiary.confに付け加えておけば、再度 migrateが実行されることを回避できる。
追記@2008-06-10: trunkの tDiaryに自動 UTF-8変換機能
今度こそパッチではなくコミット済み。migrate.rbを実行済みの人は(パッチの時とは別の)回避措置がアップデートの前に必要。
2008年03月06日 (木) 一日遅れで HUNTER×HUNTERの発売に気付く。考えられないミス。
♪ [tDiary]バッドノウハウ: ヘッダ/フッタに #{} を含めたいときは
例えばこんな、<h1>の中身を<title>の中身と同じにし、かつ日記名部分をトップページへのリンクにする、ヘッダはエラーになる。
<h1>
<a href="<%=h @conf.index%>"><%=@conf.html_title%></a>
<%=title_tag[/\A<title>#{Regexp.quote h @conf.html_title}(.*?)<\/title>\z/oi, 1]%>
</h1>
原因は
#{Regexp.quote h @conf.html_title}
この部分が tdiary.conf読み込み時に展開されてしまうから。
- \を使ってエスケープしても \自体が tdiary.conf保存時にエスケープされてしまっているので、tdiary.conf読み込み時にはエスケープの意味が残っていない。
- 二度 eRubyスクリプトとして評価されるわけではないので <%%= %> も使えない。
結局
#{'#'}{Regexp.quote h @conf.html_title}
こうなった。
- 設定画面に表示されるヘッダの内容は、#{'#'} が # に展開された後のもの(つまり最初の例と全く同じもの)なので、
ヘッダを修正するときは毎回#{ を #{'#'}{ に書き換えた上で保存する必要がある。(面倒。絶対忘れる) - ヘッダの内容に問題があるときは、正常に送信できたように見えて tdiary.confには保存されていないから、(忘れた頃に)絶対ハマる。
追記
1と 2のコンボで、ヘッダ/フッダに限らず全ての設定が変更できなくなる。他の設定を保存するときでも、ヘッダの保存部分で失敗するから。(結局 tdiary.confの可読性を犠牲にして String#dumpを使用するしかないようだ)
追記の追記: #{} の使用は避けるに限る
嫌い*だが tDiary本体をいじくるぐらいならしかたがない。今回のケースは結局 #{} を使わない形に書き換えた。無理矢理使っても面倒なだけだったので……。敗北。
<h1>
<a href="<%=h @conf.index%>"><%=@conf.html_title%></a>
<%=title_tag[Regexp.new('\\A<title>'+Regexp.quote(h( @conf.html_title))+'(.*?)</title>\\z', Regexp::IGNORECASE), 1]%>
</h1>
* Regexp.new()のこと。eval()や new Function()と同じくらい嫌い。※new演算子があるのは Rubyではない。
2008年03月04日 (火) 現在 9F。火トカゲを倒す必要がないことにしばらく気付かなかったよ。
♪ [tDiary] fix_url() @ hikidoc.rb
ささいなことなのでここに書くわけだけど、HikiDocと tDiaryの許容する urlの違いから、tDiary同梱の hikidoc.rbの fix_url()が継ぎを当てられた結果、難解なことになっている。
if /:/ =~ uri and %r!\A(https?|ftp|file|mailto):! !~ uri
uri
elsif %r|://| !~ uri and /\Amailto:/ !~ uri
uri.sub(/\A\w+:/, "")
else
uri
end
uri.sub(/\A(?:https?|ftp|file):(?!\/\/)/, "")
上が 2008-03-04現在のコード。下は上と同じ意味になっていると思うが自信が持てない。それもひとえに前者が難解だから……。
追記@2008-06-06: 何か勘違いしてるな
下の方のコードはほとんど hikidoc.rb(revision 93, 2008-02-16)のものだ。これを目にしていなかったはずがない。
♪ [tDiary] tDiary UTF-8化
昨日(3日)の朝に、tDiary本体に migrate機能を付けたと読んだので、一日待って、今日アップデートしたのだけど、tarballは 2日のものだったみたい。(待った意味がない)
- いつも通りローカルの変更をマージ。
- 標準添付でない jdate.rbを UTF-8で保存し直し。
- tdiary.confを UTF-8で保存し直し。(しなくても動いているがコメントが悪さをしないとも限らない?)
- キャッシュ(yyyymm.rb, yyyymm.parser)を削除。(したけど migrate.rbが消してくれるみたい)
- misc/migrate.rbを index.rbフォルダに移動して実行。
どこかから拾ってきたプラグイン以外は、tDiaryを最新のものにして migrate.rbを実行するだけでいいみたい。
カテゴリキャッシュも、プラグインが(confに)保存したデータも、古いキャッシュも migrate.rbが面倒を見てくれる。
2008年01月12日 (土)
♪ [tDiary] tDiaryの hikidoc.rbを VERSION 0.0.2(r87)に
中身ががらっと変わっていてびっくり。浦島太郎になっていた。Rubyist Magazine 出張版で hikidoc.rbが添削されていて、そのコードをベースに書き直したらしい。
tDiary-2.2.0同梱の hikidoc.rbにあった、複数行PREや複数行プラグイン記法が干渉する問題がなくなっている、というのがアップデートの目的。
Wikiスタイルでこういう本文を書くと
!_
<<<
{{{}}}
>>>
{{'test'}}
このような HTMLになっていた ( {{'test'}}は testになっているべき )が、
<h3><a name="p01" href="./20080111.html#p01"><span
class="sanchor">_</span></a> _</h3>
<pre>
{{{}}}
</pre>
<p>{{'test'}}</p>
VERSION 0.0.2では直っている。
tdiary/wiki_style.rb の変更
HikiDocのアップデートに伴って、HikiDocを呼び出す部分を下のように変更する必要がある。
def to_html( string ) html = HikiDoc::to_html( string, :level => 3, :use_wiki_name => false, :allow_bracket_inline_image => false, :plugin_syntax => method(:valid_plugin_syntax?) ).strip
use_wiki_nameオプション(false)を追加。
本文中にべた書きしたWikiNameをリンクにしてほしくない。
allow_bracket_inline_imageオプション(false)を追加。
[[beautiful_stuff.png]]など角かっこに入れた画像っぽい URLを <img>に置換してほしくない。
empty_element_suffixオプションを削除。
空タグの終了の仕方は HikiDoc.to_htmlと HikiDoc.to_xhtmlを呼び分けることで変更する。
呼び出し方法を HikiDoc.new.to_htmlから HikiDoc.to_htmlに変更。
以前の形式のままでも大丈夫なように互換性が保たれているが、警告が出るので。
エスケープ方法が変わった(というかなくなった?)
以前は二重のbrace(=プラグイン記法)など HikiDocにとって意味のある記号をそのまま表示したいときに
\{{plain text}}
とエスケープすることができたがそれが不可能になっている。今は代わりに
{{'{{'}}plain text}}
と書いている。他の書き方もあるかもしれないがプラグイン記法は将来も変更されないだろうから冗長でもこれが確実*。さもないとエスケープ方法が変わったときに過去の日記を書き換えてまわる羽目になる。(今の自分のように)
行単位のPRE記法(空白インデントする方のPRE)で、強調、もっと強調、打ち消しするための変更。ついでにプラグイン記法も有効になる。
以前の hikidoc.rbに加えていた変更を新しい方にも。
「記法が有効になる ⇒ これらの文字をそのまま表示するためには一手間必要」
なんだけど、複数行PRE記法(<<<〜>>>)をそのままの状態(一切の修飾が無効)で残しているので必要なら(というか強調や打ち消しが不要なら)そちらを使える。
--- hikidoc.rb.r87 Mon Jan 14 09:43:25 2008
+++ hikidoc.rb Mon Jan 14 09:57:35 2008
@@ -328,11 +328,11 @@
INDENTED_PRE_RE = /\A[ \t]/
+ # ''em'', '''strong''', ==strike== and {{plugin}} are available.
def compile_indented_pre(f)
lines = f.span(INDENTED_PRE_RE)\
- .map {|line| rstrip(line.sub(INDENTED_PRE_RE, "")) }\
- .map {|line| @output.text(line) }
- @output.preformatted restore_plugin_block(lines.join("\n"))
+ .map {|line| rstrip(line.sub(INDENTED_PRE_RE, "")) }
+ @output.preformatted compile_modifier(lines.join("\n"))
end
BLOCK_PRE_OPEN_RE = /\A<<<\s*(\w+)?/
強調は有効にするけどプラグインは無効がいいなら、追加分の最終行を
+ @output.preformatted compile_modifier(restore_plugin_block(lines.join("\n")))
こうすればよいが、そうするとモディファイア(''em'', '''strong''', ==strike==)をモディファイアでない、そのままのテキストとして書く方法がなくなる気がする。
追記@2008-02-10: tDiary-2.2.0.20080119で hikidoc.rbが r87になった
追記@2008-02-10: tDiary-2.2.0.20080210で 警告がでない呼び出し方法になった
* プラグイン記法の中身は HikiDocを利用するアプリケーション(Hikiや tDiaryなど)によって許可される内容が変わってくる。プラグインを利用して書かれた HikiDoc形式の文章は HikiDocを利用するアプリ間でポータブルでないかもしれない。全然確実ではなかった。実際この書き方は Hikiに、有効なプラグインの呼び出しではないとエラーにされてしまう。だってただの文字列だから……。