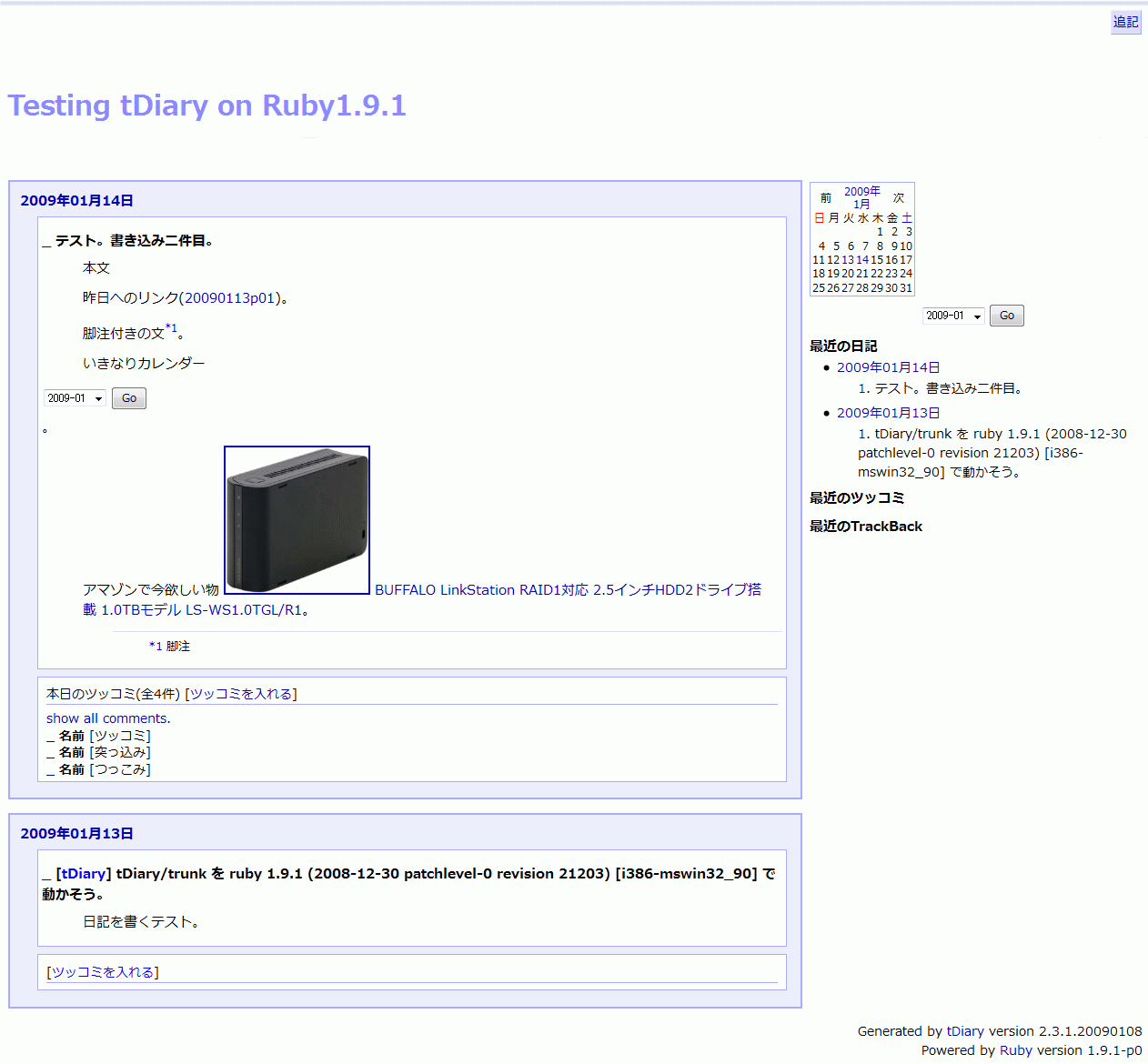
2009年07月05日 (日) FEDERERでした。それまでブレイクしてたのは RODDICKだったのにファイナルセットでできなかった。
♪ [tDiary] makerss.rb: 更新したつもりのないエントリまでが上がってくる理由。
ある日のエントリの一つを更新すると、同じ日の他のエントリまでが更新されたとして上がってくる理由。たぶんそれまでに他のエントリで「ちょっとした修正」を行っていたのだろう。makerss.rbを見てみたら
add_update_proc do makerss_update unless @cgi.params['makerss_update'][0] == 'false' end
ちょっとした修正では日記の更新時に何も行っていない。これを、index.rdfの更新はしないけど cache/makerss.cacheの更新はする、というふうに変えられないだろうか。
目的は、以前に加えたちょっとした修正と、今回の普通の更新で加えた変更とを区別するため。
編集対象のセクションを特定できるなら、cache/makerss.cacheを常に更新することで、以前のちょっとした修正を検出しなくなるようにする必要はないし、むしろ LDRのようにフィードの内容の一字一字を比較するリーダー?(フィードアグリゲータ?)まで騙すことを考えると、cache/makerss.cacheの内容はちょっとした修正以前の古いままにしておく方がいいみたい。
じゃあ、なぜ既にセクション単位で編集を行ってるこの日記で、直前の編集に関係していないセクションまでが上がってくるのか? makerss.rbの変更まで手を回す前にやる気が尽きたから。
update_procに引数の追加が必要なんだけど、改めて具体的に考えてみると単純にセクションナンバー1つを渡せばよいというものでもなさそうだ。セクション2を編集した結果、セクション2がなくなってセクション3が 2に繰り上がってる可能性がある。セクション2が分裂してセクション2と 3になってる可能性がある。
LDRといい update_procの引数といい、万全を期すと二進も三進もいかんなあ。(LDRは使ってないから外せない問題ではないし、update_procは {before=>2, after=>2..3} を渡すだけで済んでしまう気もするけど)
ああ、afterの範囲を確定するのが難しいんだ。変更前に、編集対象のセクションの前にいくつ、後にいくつのセクションがあるかを数えておく手があるけど、場合によったら直前のセクションと結合してしまうことがあるからなあ(セクション2を編集していたはずが、セクション2を削除してセクション1に追記したことになってる可能性がある)。この場合セクション1に変更があったことは無視してセクション2が削除されたことだけを考えていいなら、やっぱり前後のセクション数を数えておく方法でよさそうだ。
makerss.cacheは二つの目的を持ってるんじゃないか。変更のあったセクションを検出する目的と *.rdfのソースにする目的。
そもそも、*.rdfのソースは *.rdf自身で十分じゃないか?(深くわかってるわけじゃないけど) これに変更のあったセクションを特定できる引数が update_procに加わったら makerss.cacheを用済みにできないか。
できない。一日単位の編集機能をなくせるわけじゃないから今と同等の変更検出機能は必要。そうすると *.rdfのソースを makerss.cacheから *.rdfにスイッチする必要もなさそうに思えるけど、……ないかも。(うっかりフィードに紛れ込んだテストコメントは index.rdfからアイテムを削除するのでなく、コメントを非表示にすれば、あとあと甦ってくることもなかったんだ)
整理。
makerss.cacheは二つの役割を持っている。
- 変更のあったセクションを検出する。
- .rdfのソースにする。
変更のあったセクションの検出能力に難があったので改善を試みる。一日単位の編集機能が存在し続け、rdfのエントリの単位がセクションである限り、変更のあったセクションの検出能力の向上は無駄にならない。
makerss.cacheの日記内容をちょっとした修正でも更新する。
これでちょっとした修正のあったセクションの誤検出はなくなる。だがこの makerss.cacheをもとに *.rdfを作成するとエントリの内容がちょっとした修正後のものになり、LDRなど RSSリーダーによる過剰検知の原因となる。
*.rdfのソースを *.rdfにする。
右から左に流すだけでは過剰検知の起こりようがない。フィードを更新するときにどんな問題が発生するだろう……。手順を考える。
- makerss.cacheとの比較を基に、追加、変更のあったセクションを特定する。
- .rdf内のエントリから削除された(現在のセクション数から考えられるより大きいセクションナンバーを持つ)セクションを取り除く。
- 追加、変更されたセクションを .rdfのエントリに変換する。
- .rdf内に対応するエントリがあれば上書き、なければ追加し、.rdfの先頭に移動する。
- エントリ数の上限まで書き込み。
問題は、フィードに含まれる日記やコメントを隠したりセクションを削除したりするとエントリ数が上限より少なくなる、だけだろうか。最初は無理そうに思えたけど、なんだったんだろう。
makerss.cacheから読み込んだものと *.rdfから読み込んだものとは Rubyオブジェクトか文字列かという違いがあるんだなあ。でもそれが意味を持つのは MakeRssNoComments#itemで呼ばれる rdfsec.section.respond_to?( :body_to_html )だけみたいだから、ここを rdfsec.id.index("p") に置き換えれば *.rdfから読み込んだ xml文字列だけで makerss.cacheの代わりができそう。
整理(Plan B)
セクション単位の編集機能があり、makerss.rbが update_procの引数から変更のあったセクションを知ることができれば、今以上の、変更のあったセクション検出能力は特段必要ではない。
makerss.cacheはこれまで通りちょっとした修正では更新されず、LDRをちょっとした修正以前の古い内容でだまし続けることが可能。
日記の書き手はフィードの更新を伴うデリケートな編集作業ではセクション単位の編集を行うことで、余計なセクションが上ってくることを避けられる。
こっちが断然楽そうだ。でも自分の環境で閉じてしまうから代替案なんだよね。
タイトル(脳log)にふさわしい垂れ流しっぷりじゃあないですか?
をを、バグってる
はるか上の方でこう書いた。
場合によったら直前のセクションと結合してしまうことがあるからなあ(セクション2を編集していたはずが、セクション2を削除してセクション1に追記したことになってる可能性がある)。
何を見て書いていたかというと……
unless body1.empty?
current_section = @sections.pop
if current_section then
body1 = "#{current_section.body.sub( /\n+\Z/, '' )}\n\n#{body1}"
end
@sections << WikiSection::new( body1, author )
end
解説解説
appendされた Wikiソースがサブタイトルを持っていないもの( body1 )だったら、 最後のセクションを取り除き 最後のセクションの本文( current_section.body, サブタイトルを含まない )と body1を連結し、 新しいセクション( サブタイトルなし )として追加する。
WikiSection#bodyの代わりに WikiSection#to_srcを使わないとサブタイトルが消えてしまう。
body1 = "#{current_section.to_src.sub( /\n+\Z/, '' )}\n\n#{body1}"
サブタイトルのあるセクションに、サブタイトルのない本文を追加したときに、サブタイトルのないセクションができあがるのを防ぎます > fix_and_test_append_without_subtitle.diff
Plan B 仮実行中
セクション単位の編集機能が追加されていることが前提。そのせいでこの日記でしか使えないから気乗りしなかったんだけど、第一案が手詰まりなのと一つの実験場として可能性を示すために。
update_procに updated_sectionというパラメータを追加し、makerss.rbが過去のちょっとした修正を誤検出するのを防ぎます > add_param_updated_section_to_update_proc.diff
2009年03月06日 (金)
♪ [Ruby][tDiary] > tDiary: ニコ動プラグインが動いてない? - ただのにっき(2009-03-05)
試してみた。SecurityErrorが出た。リンク先の ruby-1.9.1とは違い、こちらは ruby-1.8.7-p72でのエラー内容。
>irb
irb(main):001:0> require 'open-uri'
=> true
irb(main):002:0> $SAFE=1
=> 1
irb(main):003:0> open 'http://vvvvvv.sn25p.dip.jp/301.rb'
SecurityError: Insecure operation - []
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:577:in `[]'
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:577:in `find_proxy'
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:147:in `open_loop'
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:164:in `call'
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:164:in `open_loop'
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:162:in `catch'
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:162:in `open_loop'
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:132:in `open_uri'
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:518:in `open'
from C:/Program Files (x86)/ruby/lib/ruby/1.8/open-uri.rb:30:in `open'
from (irb):3
irb(main):004:0>
301.rbはこう。
#!ruby
require 'cgi'
cgi = CGI.new;
print cgi.header({
'Status' => '301 Moved Permanently',
'Location' => 'http://vvvvvv.sn25p.dip.jp/index.html'
});
ホストネームを指定しない場合は大丈夫だった。例えばこんな。
#!ruby
require 'cgi'
cgi = CGI.new;
print cgi.header({
'Status' => '301 Moved Permanently',
'Location' => '/index.html'
});
どこまで by designなんだろう。
2009年02月26日 (木)
♪ [tDiary] なにかおかしい。サーバーのRuby? 俺の書いたスクリプト? 改行コード?
過去にこんなことを書いた。
過去の日記を「編集」するとその日の全てのセクションが rdfに上ってくるのね。tDiary-2.3系の目玉はセクション単位での編集機能だなあ。
セクション単位の編集機能を実装しおえて、makerss.rbの対応もやっとくか、とソースを読んでみたらきっちり内容比較をしていた。だから当然、変更されたセクションのみが RSSで上に上がってくる。一文字も変更せずに日記を送信した場合、RSSも更新されない。ローカルの tDiaryで確認した。でもサーバー( http://vvvvvv.sakura.ne.jp/ds14050/diary/ )ではそうなっていない。過去に書いたとおり、どんな場合でもその日のすべてのセクションが上がってくる。
そういえばこんなこともあった。
日記を更新すると、TDiary::Config#data_path/category/ 以下の、カテゴリごとに作られるキャッシュファイルがずいぶんたくさん更新される。全部ではないが半分近い 21のファイルが更新されていた。日記の内容はというと一つのカテゴリしか使っていない。
根が同じかどうかはわからないが、なにかがおかしい。
そういえば、makerss.rbの作成するキャッシュファイルもカテゴリインデックスと同じ PStore形式だった。におう、におうぞ。
必ずしも上がってくるというものでもないみたい。サーバーの makerss.rbも概ね期待通りの動作をしている。うにゅう。
あまりに古い日記を編集していて、makerss.cacheから記事が掃き出されているために変更の有無を確認できない、というのとも違うんだけど。……と思うんだけど。(もういいや)
とりあえず内容を比較する前に stripしてみた。これで様子見。(複数のエントリが同じ時刻に更新されたかのように記録されることがなくなければ O.K.)
if cache[id].section.body_to_html.strip != section.body_to_html.strip or cache[id].section.subtitle_to_html.strip != section.subtitle_to_html.strip then cache[id] = RDFSection::new( id, Time::now, section ) end
最終更新: 2009-12-10T00:55+0900
♪ [tDiary] この日記では一日一エントリールールを採用していません。
ルールを守るために未来日記を書く人もいるようですが、これはあくまで普通の日記だし、書いた日付と内容は切り離せないので、一日に複数のエントリを書いたりもします。だから、セクション単位での編集機能を、もちろんブラウザで。
edit_section.diff
| 編集画面 | プレビュー画面 | プレビュー画面(競合あり) | 登録画面(競合あり) |
|---|---|---|---|
.png") | .png") | .png") | .png")
|
変更内容はこのような感じ。
section=n (n=1,2,...)パラメータ追加。
例えば、2009年2月26日の第1セクションの編集フォームへのリンクはこうなる。
update.rb?edit=1;year=2009;month=2;day=26;section=1
編集対象セクションの変更を検知。
現在編集中のセクションが他の人によって書き換えられていたり、セクションの挿入や削除によってセクションナンバーが変わっていたときは、エラーメッセージを表示して(プレビュー画面でも確認可能)、変更をコミットしない。(「戻る」の後でも直前の編集内容が残っているかどうかは使用しているブラウザ次第)
著者情報を保存。
従来の一日単位での編集では失われていた*著者情報が、セクション単位の編集では保存される。(編集対象のセクションは一番最後の変更者名になる)
ついでに、ある日の編集フォームを利用して、別の日に追記したとき――編集画面で日付を書きかえた後、この日付の日記を編集ボタンを押さずに、登録ボタンを押すことで可能――、記録されていなかった*著者名も記録する。
Big5わかりません。
というわけで、skel/update.rhtml.zhと skel/preview.rhtml.zhは手つかずなので、従来の編集画面と機能になる。
skel/update.rhtml.enと skel/preview.rhtml.enは書きかえたけど動作未確認。
wikiスタイルでしか試していません。
とはいえ、スタイル関連で利用するメソッドは each_section、append、replaceだけなので動くはず(期待)。
ただ、Diary#to_srcが Section#to_srcを単純に連結したものである、という仮定をおいてしまっているのだが、新旧wiki_style、rd_style、emptdiary_style、hatena_style、markdown_styleは大丈夫なものの、etdiary_styleは少しだけ違っているのが若干気になる。(といっても末尾の改行を一つにまとめてるだけなんだけど)
[このセクションだけを編集]ボタンは、[この日付の日記を編集]ボタンと同じもの。
type="submit" name="edit"
上記が共通部分。(ボタンのラベルも送信されるけど、使われないので違ってて構わない)
セクションの著者情報ってどこに保存されてるの?
新旧Wikiスタイルの場合、*.td2にはないよね。
tdiary_styleの場合、書き出される(TdiarySection#to_srcに含まれる)けど、読み込んだらカテゴリの一つになってしまいそう。
etdiary_styleも書き出すけど、読み込みは考えてなさそう。EtdiarySection#initializeに明示的に authorを渡しても使われない。
不毛だ。
プラグインの表示したフォームを送信すると、次の画面が普通の一日分の編集画面になる。<input type="hidden" name="date" value="yyyymmdd"> というようなフォームを埋め込む責任が個々のプラグインに委ねられているのでどうしようもない。
TODO: 元の画面に戻ることを保証することと、プレビュー画面に form_procを表示すること。
プレビュー画面への form_proc表示はもうやってるし、form_procを利用したファイルのアップロードを別タブの編集画面でやれば、変更内容が失われる心配もない。知ってるから困らないけど、わかりにくいのは確か。
plugin/edit_section_link.rb
一日表示のとき、セクションごとに編集リンクを付ける。
add_subtitle_proc {|date, section, subtitle|
subtitle += %Q(<span class="adminmenu edit_section"><a href="#{h @conf.update}?edit=1;year=#{@date.year};month=#{@date.month};day=#{@date.day};section=#{section}" rel="nofollow">[edit]</a></span>);
} if @mode == 'day';
サブタイトル(<h3>の中)に関係のないテキストを加えるより、サブタイトルの直前に挿入されるこっちの方がいいかも。
add_section_enter_proc {|date, section|
%Q(<span class="adminmenu edit_section"><a href="#{h @conf.update}?edit=1;year=#{@date.year};month=#{@date.month};day=#{@date.day};section=#{section}" title="edit (author only)" rel="nofollow">✍</a></span>);
} if @mode == 'day';
2009年02月23日 (月)
♪ [Ruby][tDiary] 続報・ruby-1.9.1で、不思議で困ったことが起こった。
問題のコード(再掲)はこれ。あるハッシュのキーについて繰り返しているのに、ハッシュにそのキーが存在しない。(すべてのキーが見つからないわけではないが、見つからないキーはいつでも見つからない)
categorized.keys.each do |c|
PStore.new(cache_file(c)).transaction do |db|
categorized.fetch(c) #=> key not found (KeyError)
db['category'] = {} unless db.root?('category')
db['category'].update(categorized[c])
end
end
fetchをブロックの最初に持って行くと、そこではエラーにならない。
categorized.keys.each do |c|
categorized.fetch(c) #=> O.K.
PStore.new(cache_file(c)).transaction do |db|
db['category'] = {} unless db.root?('category')
db['category'].update(categorized[c])
end
end
cache_file(c)の呼び出しが原因。その中でも includeしてある ERB::Utilの u()メソッドが核心。
categorized.keys.each do |c|
::ERB::Util.u(c)
categorized.fetch(c) #=> key not found (KeyError)
PStore.new(cache_file(c)).transaction do |db|
db['category'] = {} unless db.root?('category')
db['category'].update(categorized[c])
end
end
引数にした文字列のエンコーディングが変わってしまっている。
categorized.keys.each do |c|
enc1 = c.encoding;
::ERB::Util.u(c)
enc2 = c.encoding
categorized.fetch(c) { raise "#{enc1} #{enc2} #{::ERB.version}" } #=> UTF-8 ASCII-8BIT erb.rb [2.1.0 2009-01-11] (RuntimeError)
PStore.new(cache_file(c)).transaction do |db|
db['category'] = {} unless db.root?('category')
db['category'].update(categorized[c])
end
end
ERB::Util.url_encodeの定義を見ると、引数の文字列を dupした後にエンコーディングを変更しているにも関わらず、呼び出し元に影響を与えてしまっている。
def url_encode(s)
s.to_s.dup.force_encoding("ASCII-8BIT").gsub(/[^a-zA-Z0-9_\-.]/n) {
sprintf("%%%02X", $&.unpack("C")[0])
}
end
alias u url_encode
そんなわけだから呼び出し側(category.rb)で
u( c.dup )
なんてやっても効果はなく、
u( ""+c )
あるいは
u( "#{c}" )
とやって初めて、今回の現象を回避することができた。
これは、文字列の複製を遅らせた結果、期せずしておこった現象にみえる。
バグのはずなんだけど、irbで再現しようと思ってもできないんだこれが。
追記@2009-08-13: 見る人が見れば修正はあっという間でした。
http://redmine.ruby-lang.org/issues/show/1929
(ここに、見るべき場所を見つけることもできなかった人間がひとり)
* 正しくは ruby-1.9.2dev(2009-02-03)
2009年02月15日 (日) 本文中の URL自動リンクがセミコロンで切れていたので、/shjs/lang/sh_ruby.jsと /shjs/lang/sh_javascript.jsを修正した。そこで使っていた正規表現は『詳説 正規表現 第3版』で、大抵の場合うまくいくと紹介されていたものでした。(CGIパラメータを ; で区切るのはいまだに異端でしたか)
♪ [Ruby][tDiary] ruby-1.9.1*で、不思議で困ったことが起こった。
この断片で理解してもらえるだろうか。
categorized.keys.each do |c|
PStore.new(cache_file(c)).transaction do |db|
categorized.fetch(c) #=> key not found (KeyError)
db['category'] = {} unless db.root?('category')
db['category'].update(categorized[c])
end
end
あるハッシュのキーについて繰り返しているのに、ハッシュにはそのキーが存在しないという、この不思議。
このとき、c は、
"\xE6\x9C\xAC\xE6\x97\xA5\xE3\x81\xAE\xE8\xB3\xBC\xE5\x85\xA5" ASCII-8BIT
ハッシュのキーリストとそのエンコーディングは、
"\xE6\x9C\xAC\xE6\x97\xA5\xE3\x81\xAE\xE8\xB3\xBC\xE5\x85\xA5" ASCII-8BIT "本" UTF-8 "マンガ" UTF-8 "雑誌" UTF-8
存在しているだろうに……。
追記@2009-02-20: 同じ目に遭っている人がいた。
さくらインターネット上で tDiary を ruby1.9.1-p0 で動かす - まちゅダイアリー(2009-02-19)(14:57現在、日別表示が不可能な状態。最新表示は可能)
* 正しくは ruby-1.9.2dev(2009-02-03)
2009年02月12日 (木) ruby-1.8.7も最近 p0から p72にしました。それ以上のはコンパイルできませんでした。おとなしくリリースを待ちます。
♪ [tDiary] tDiaryを 2.3.0.20080302から 2.3.1.20090129へアップデート。
手動で migrate.rbを実行して UTF-8化してあったのに、再度 90migrate.rbが走ってしまって、データが壊れた。慌てず ZIPファイルを解凍して元通り。
grepと同じ程度に簡単に、データファイルや tdiary.confのバージョンナンバーをすべて書き換える方法(sed?)が思いつかなかったので、tdiary/lang/ja.rbの migrate_to_utf8を無効化して済ませた。
def migrate_to_utf8( str ) return str to_native( str, 'EUC-JP' ) end
素通しとはいえ migrationは実行されるので、数十から百ちかい数のファイルを開いて書き込んで閉じてといった負荷をレンタルサーバーにかけた。ローカルでは一分以上かかった。
2.3.1になってカテゴリが大文字小文字の区別なくソートされる*
のが嬉しい。気になっていて、よっぽど自分でやってやろうかと思っていたので。
古い tdiary.confを引き継ぐと
@accesskey_enabledの設定が存在しない(=>nil => falseと判断される)ために、アクセスキーがなくなってしまって戸惑った。ここはデフォルトを過去と互換にして欲しかった(設定名を @disable_accesskeyにするとか)。いまさらだけど。
category.rbが nilにアクセスして NoMethodErrorを出すと思ったら
NaviUserCGIが木偶だからだった。原因は category.rbにはなく、できの悪い CGIのモックを渡した navi_user.rbにある。
エラーを出した category.rbのコード
class Info
include ERB::Util
def initialize(cgi, years, conf, args = {})
@cgi = cgi
@years = years
@conf = conf
@category = args[:category] || @cgi.params['category']
@year = args[:year] || @cgi.params['year'][0] #=> NoMethodError: undefined method `[]' for nil:NilClass
NaviUserCGIの定義
class NaviUserCGI
attr_reader :params, :referer, :user_agent
def initialize(datestr)
@params = {'date' => [datestr]} # <<<注目!
@referer = nil
@user_agent = nil
end
def request_method
'GET'
end
end
オリジナルの CGI#paramsは単一のデフォルト値( [].freeze )を持った Hashなんだよね……。
navi_user.rbも recent_list.rbと同じように書き換えてやろうか。
* 一か所、大文字も小文字も存在しない配列のソートを普通のソートに戻しました。
2009年02月09日 (月) すでに世の中、一般人も RSSです……よ?
♪ [tDiary] テーマ自作 > badboy2007.css
")
自分好みの見た目に拘るようになるにつれ、既存のテーマから得られる部分が減り、打ち消す手間が目立ってきた。そろそろ一から積み上げる方が楽だと感じたので。
公開されるテーマは汎用性を求められるぶん、個人的には冗長だったり、かゆいところに手が届かなくて CSSを追加したりする必要があったりするが、公開を前提としない自作なら、十分かつ必要最小限なものになる。(この現状を十分とは口が裂けても言えないけれど)
以下、備忘録としてスタイルを決めた際のポイントを。(すごく雑多)
- タイヤの下には地面。
- 「ツッコミを入れる」リンクの目的は移動ではなくアクションなのでボタンっぽく。
- 「ツッコミを入れる」前後の [角かっこ]は skel/diary.rhtmlから削除。(ナビゲーションリンクの «, »も削除しています。なんでラベルに含めないんだろ。今なら CSSの contentも広く使えるのに、文字のハードコーディングは不便)
- IE8RC1のデフォルトスタイルシートは<pre>の文字を小さくするので抵抗した。
- 引用文は自分の書いた文章ではないので異物感。
- 引用の中のPREはそれとわからないように。(実験的)
- 色の決定には色名に対する好みが多分に入っている。(好き > navy, crimson)
ヘッダとフッタに関してもポイントを。(未来の自分が思い出せるように)
- 日記著者向けのリンク(追記など)は、目立たないように、閲覧者向けのナビゲーションリンクと混ぜないように。(ページ最下部でも良い)
- 目次はスクロールの必要なく、一画面に収まるように。(マージンとヘッダの内容と表示日数を削った)
- ページトップに前後方向のナビゲーションはいらない。(目次の下とページ最下部に置いてみました)
- フラットなカレンダーを先頭に置くと Tabキーによるフォーカス移動が大変。(カレンダーはページ最下部にとりあえず放り込みました)
古い日記はレイアウトが崩れてるかも。過去の日記の凍結(ヘッダ、フッタ、プラグインの出力を日記執筆時点のものに固定)という名の HTML書き出し機能が欲しい。
実は squeeze.rbを少し変更してヘッダ、フッタを含む HTMLを書き出し、mod_rewriteを使ってその HTMLファイルが存在するときはそちらを参照するように .htaccessで設定したりしていた。
RewriteEngine on
RewriteBase /ds14050/diary
# Rewrite rule1
# shows static html, if exists.
RewriteCond /home/vvvvvv/www/cgi_file/ds14050/diary/snap/$1.html -f
RewriteCond %{REQUEST_METHOD} =GET [OR]
RewriteCond %{REQUEST_METHOD} =HEAD
RewriteCond %{HTTP:Cache-Control} !=no-cache [nocase]
RewriteRule ^([0-9]{8})\.html$ /cgi_file/ds14050/diary/snap/$1.html [L]
でも静的 HTMLをブラウザが直接参照するので tDiaryが起動せず、リファラの記録が行われなくなるし、多分ツッコミ(&トラックバック)が入るだけで HTMLが新しく生成されてしまう。翌日の日記へのナビゲーションリンクも基本的に出ない。ツッコミの読み込みとリファラの記録を静的 HTMLに埋め込んだ JavaScriptで行うことで、内容を最新に保ちつつ HTMLの生成を抑制できるが、実際にやってみるほどのメリットを見いだせず。スクリプトを実行しないブラウザ対応もパッと思いつかない(使える道具って<script>と<noscript>だけなのだろうか。コメント部を別 HTMLファイルとして保存して SSIで埋め込むとか……。うーむ)。
2009年02月02日 (月) [Vista] リソース モニタのキーボードインターフェイス: P(CPU項目を展開)、D(ディスク項目を展開)、N(ネットワーク項目を展開)、M(メモリ項目を展開)、L(全て展開)、Shift+P,D,N,M,L(それぞれの項目を展開、折り畳み切り替え)
♪ [Ruby][tDiary] tDiaryは、1.9系の Rubyでは 1.9.2から動くようになるのか。

requireの処理の中で、セーフレベルを一時的に 0 に下げる部分があって、この範囲を広げることで、SecurityErrorが出ないようになっていた。(3日前)
画像は、tDiaryの amazon.rbが、リポジトリから持ってきただけの素の Ruby-1.9.2dev(2009-02-03)上で動いているところ。
既に正式版がリリースされて*しまって*いる Ruby-1.9.1との違いを、先月の日記に書いた例で見ていくと、
$SAFE=1で、カレントディレクトリのスクリプトを requireしたとき
irb192> RUBY_DESCRIPTION
=> "ruby 1.9.2dev (2009-02-03) [i386-mswin32_90]"
irb192> $SAFE=1
=> 1
irb192> require "a"
SecurityError: cannot load from insecure path - Y:/.../Desktop/a.rb
from (irb):3:in `require'
from (irb):3
from C:/Program Files (x86)/ruby/bin/irb192.bat:20:in `<main>'
irb192> require "a.rb"
SecurityError: cannot load from insecure path - Y:/.../Desktop/a.rb
from (irb):4:in `require'
from (irb):4
from C:/Program Files (x86)/ruby/bin/irb192.bat:20:in `<main>'
irb192>
2009-02-03版の ruby-1.9.2devでは、$SAFE=1のとき、カレントディレクトリのスクリプトを requireできない。これは $:($LOAD_PATH)に汚染されていない "." が含まれていようと、require の引数の文字列が汚染されていなかろうと、requireできない。見つけた抜け道は、絶対パスで requireするか、$:($LOAD_PATH)にカレントディレクトリを絶対パスで追加すること("."が含まれる場合はそれより前に追加する必要もある)。
ruby-1.9.1の結果は Release Candidateのときと変わらず、
irb191> RUBY_DESCRIPTION
=> "ruby 1.9.1p0 (2009-01-30 revision 21907) [i386-mswin32]"
irb191> $SAFE=1
=> 1
irb191> require "a"
SecurityError: Insecure operation - require
from (irb):3:in `require'
from (irb):3
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/bin/irb.bat:20:in `<main>'
irb191> require "a.rb"
a.rb required.
=> true
irb191>
ruby-1.9.1では、拡張子を付けてやるとカレントディレクトリのスクリプトも requireできる。拡張子を付けないときに requireできないのは ruby-1.9.2devも同じだが 、ruby-1.9.1には ruby-1.9.2devにない爆弾がある。$SAFE=1のときの拡張子を付けない requireは、添付ライブラリの requireであっても失敗したりする。
irb191> $SAFE=1
=> 1
irb191> require "stringio"
SecurityError: Insecure operation - require
from (irb):2:in `require'
from (irb):2
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/bin/irb.bat:20:in `<main>'
irb191> require "stringio.so"
=> true
irb191>
これが原因で、tDiaryを ruby-1.9.1で動かすのは絶望的だと思っている*。(ruby-1.9.1はリリースされちゃったし、スクリプトで対応できる範囲を超えているから)
この部分は SecurityErrorが出ない方向に修正されると思っていたから、ruby-1.9.2devで両方のパターンが SecurityErrorになったのは意外。
$SAFE=1で、汚染されたパスが $:($LOAD_PATH)に含まれるとき
ruby-1.9.2devでは、汚染されたパスが $:($LOAD_PATH)のどの位置にあるかが重要。
irb192> $SAFE=1
=> 1
irb192> $:.unshift "!tainted!".taint
=> ["!tainted!", "C:/Program Files (x86)/ruby/lib/ruby192/site_ruby/1.9.2", "C:/Program Files (x86)/ruby/lib/ruby192/site_ruby/1.9.2/i386-msvcr90", "C:/Program Files (x86)/ruby/lib/ruby192/site_ruby", "C:/Program Files (x86)/ruby/lib/ruby192/vendor_ruby/1.9.2", "C:/Program Files (x86)/ruby/lib/ruby192/vendor_ruby/1.9.2/i386-msvcr90", "C:/Program Files (x86)/ruby/lib/ruby192/vendor_ruby", "C:/Program Files (x86)/ruby/lib/ruby192/1.9.2", "C:/Program Files (x86)/ruby/lib/ruby192/1.9.2/i386-mswin32_90", "."]
irb192> require "cgi"
SecurityError: cannot load from insecure path - Y:/.../Desktop/!tainted!/cgi.rb
from (irb):3:in `require'
from (irb):3
from C:/Program Files (x86)/ruby/bin/irb192.bat:20:in `<main>'
irb192> $:.push $:.shift
=> ["C:/Program Files (x86)/ruby/lib/ruby192/site_ruby/1.9.2", "C:/Program Files (x86)/ruby/lib/ruby192/site_ruby/1.9.2/i386-msvcr90", "C:/Program Files (x86)/ruby/lib/ruby192/site_ruby", "C:/Program Files (x86)/ruby/lib/ruby192/vendor_ruby/1.9.2", "C:/Program Files (x86)/ruby/lib/ruby192/vendor_ruby/1.9.2/i386-msvcr90", "C:/Program Files (x86)/ruby/lib/ruby192/vendor_ruby", "C:/Program Files (x86)/ruby/lib/ruby192/1.9.2", "C:/Program Files (x86)/ruby/lib/ruby192/1.9.2/i386-mswin32_90", ".", "!tainted!"]
irb192> require "cgi"
=> true
irb192>
ruby-1.9.2devでは、$SAFE=1で、汚染された LOAD_PATHからスクリプトを requireすることはできないが、汚染されていない LOAD_PATHからスクリプトを先に見つけた場合は、requireに成功する。ruby-1.9.1(とruby-1.8.7-p72)ではどうだったかというと、より厳しくて、
irb191> $SAFE=1
=> 1
irb191> $:.unshift "!tainted!".taint
=> ["!tainted!", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/site_ruby/1.9.1", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/site_ruby/1.9.1/i386-msvcrt", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/site_ruby", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/vendor_ruby/1.9.1", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/vendor_ruby/1.9.1/i386-msvcrt", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/vendor_ruby", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/i386-mswin32", "."]
irb191> require "cgi"
SecurityError: Insecure operation - require
from (irb):3:in `require'
from (irb):3
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/bin/irb.bat:20:in `<main>'
irb191> $:.push $:.shift
=> ["C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/site_ruby/1.9.1", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/site_ruby/1.9.1/i386-msvcrt", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/site_ruby", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/vendor_ruby/1.9.1", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/vendor_ruby/1.9.1/i386-msvcrt", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/vendor_ruby", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1", "C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/i386-mswin32", ".", "!tainted!"]
irb191> require "cgi"
SecurityError: Insecure operation - require
from (irb):5:in `require'
from (irb):5
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/bin/irb.bat:20:in `<main>'
irb191>
ruby-1.9.1では、汚染されたパスが一つでも $:($LOAD_PATH)に含まれると、(相対パスでの) requireはできない。絶対パスならできるが、そんな書き方はしないので $:($LOAD_PATH)に追加するパスは常に untaintしなければならない。
ruby-1.9.2dev(2009-02-03)は概ね期待通りの動作だが……
requireしたときのカレントディレクトリの扱いに、不満が残る。
多分、従来の Ruby、ruby-1.9.1や ruby-1.8.7は $:($LOAD_PATH)の要素の汚染状況なんて気にしていなかった。$:に含まれるか含まれないかだけが重要。2005年から現在まで変わっていない、リファレンスマニュアルのこの記述がそれを物語っていないか。
Level 1以上では起動時に以下の違いがある
- 環境変数 RUBYLIB を $: に加えない
- カレントディレクトリを $: に加えない
- (以下略)
その方針に異議を唱えるものではないけれど、この方式には、セーフレベルによる分岐が起動時に限定されるという制限がある。コマンドラインオプション -T を指定したときにしか有効にならず、$SAFEを使ってセーフレベルをコントロールするシナリオでは機能しない。
ruby-1.9.2devは、$:($LOAD_PATH) の要素の汚染状況に注目することで、$SAFEを使ってセールレベルをコントロールする場合でも「環境変数 RUBYLIB を $: に加えない」「カレントディレクトリを $: に加えない」のと同等の制限を課せる可能性を持っている。つまり、「環境変数RUBYLIBとカレントディレクトリは常に $:($LOAD_PATH)に追加される。ただし汚染された状態で。」ということ。
それなのに現在の ruby-1.9.2devの、$SAFE=1の下での requireに対するカレントディレクトリの扱いは、ruby-1.8.7より、むしろ退化している。
ruby-1.8.7では $:($LOAD_PATH)に "." を追加したり取り除いたりすることでカレントディレクトリの扱いを、セーフレベルによらず、スクリプトがコントロールできた。
拡張子の有無で結果が変わる、動作に筋の通らない ruby-1.9.1の requireは論外として、
ruby-1.9.2devでは、カレントディレクトリのスクリプトの requireは $:($LOAD_PATH)によらず、SecurityErrorになる。カレントディレクトリを絶対パスで $:($LOAD_PATH)に追加することでコントロール可能だが、既に含まれているかもしれない "." が邪魔をする。ruby-1.9.2devは、$:($LOAD_PATH)に含まれる "." の汚染状況(あるいは "."が $:に含まれないこと)によってのみカレントディレクトリの扱いを変えるべきで、カレントディレクトリが特別に SecurityErrorになる、現在の ruby-1.9.2devには同意できない。
セールレベル1ではまだスクリプトを信用しているのだから、少なくとも ruby-1.8.7と同等のコントロールをスクリプトに渡して欲しい。
requireが利用する File.expand_pathの仕様によりカレントディレクトリからの相対パスが汚染されるのだろうが、File.expand_pathは requireが $:($LOAD_PATH)に依拠していることを知らないのだから requireが何とかすべき。
* その後の変更で、ruby-1.9.1らしき挙動の requireを検出したときはセーフレベルを 1から 0に下げてプラグインを実行することになっている。セーフレベル0なら今回のことは関係ないから。セーフレベルを下げるという発想は全く頭になかった。なんか、こう、負けた気がするからだろう。ruby-1.9.0だとセキュアモード(セーフレベル4)で動かないという話もあったけどどうなったんだろう。
2009年01月22日 (木) Ruby-1.9.1-RC2出ました。
♪ [tDiary] tDiary on Ruby-1.9.1-rc2 -> Encoding::CompatibilityError
#<Encoding::CompatibilityError: incompatible character encodings: UTF-8 and ASCII-8BIT> (plugin/00default.rb):571:in `comment_form_text' (plugin/00default.rb):616:in `comment_form' (TDiary::Plugin#eval_src):79:in `block in eval_src' Y:/server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:787:in `eval' Y:/server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:787:in `block in eval_src' Y:/server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:112:in `block in safe'
なにが ASCII-8BITだったかというと Cookie。
plugin/00default.rb:575: #{comment_name_label}:<input class="field" name="name" value="#{h( @conf.to_native(@cgi.cookies['tdiary'][0] || '' ))}">
ならばと UTF-8への変換を試みたならば
@cgi.cookies['tdiary'][1].encode("utf-8")
#=> #<Encoding::UndefinedConversionError: "\xE3" from ASCII-8BIT to UTF-8>
クッキーみたいに何が送られてくるかわからないものは、慎重に慎重にエラーに備えて取り扱わないといけない、ということですね。(面倒くさいなー)
CGIパラメータなんかも、取り扱い注意、だよね。cgi.rbの支援はないのかな?(他力本願)
補足。エラーの原因の心当たり。
「Testing tDiary on Ruby1.9.1」と題した日記にも関わらず、少しの間、うっかり 1.8.7で動かしていた。そのせいでキャッシュが原因のエラーが出たし、キャッシュを削除したら今度はクッキーが原因のエラーが出たという次第。
サーバーの Rubyを 1.8.7から 1.9.1にアップデートしたタイミングでそのサーバーの日記を閲覧できなくなる人(過去3か月間にコメントした人限定)が続出、とか。ないだろうか。
追記@2009-01-24: Ruby-1.9での cgi.rbとその代替(Rack)。
cgi.rbも変わっていたのでした。
どちらも日付が今日(2009-01-24)だ! Googleクローリング早い。
tDiaryの文脈で Rackの名前を見かけてたんだけど、名前から Rakeのようなものを想像していた。Web方面だったのね。
2009年01月19日 (月) Wassrという Webサービスがあって、そこに tDiaryというチャンネルがあって、Firefoxにはライブブックマークとかいうものがあって、と、いろいろなものを発見。(コミットログの確認が svk sync + viewvcより簡単だ。古い記事がちょこちょこ投稿されると思ったら delicious..から tDiaryタグの付いた URLを拾っているとか。ほへー)
♪ [Ruby][tDiary] requireと $SAFE=1と汚染された $LOAD_PATH
>irb
irb(main):001:0> RUBY_DESCRIPTION
=> "ruby 1.8.7 (2008-05-31 patchlevel 0) [i386-mswin32_90]"
irb(main):002:0> $SAFE=1
=> 1
irb(main):003:0> $:.unshift "hoge".taint
=> ["hoge", "C:/Program Files (x86)/ruby/lib/ruby/site_ruby/1.8",..., "."]
irb(main):004:0> require 'cgi'
SecurityError: Insecure operation - require
from (irb):4:in `require'
from (irb):4
from :0
irb(main):005:0>
1.8.7でもこうなのだから知らない俺が抜けているのだが、$SAFE=1のときに汚染された文字列を $LOAD_PATHに追加する(pushでも unshiftでも)と、一切の requireができなくなる。
期待したいのは、hoge/cgi.rbや hoge/cgi.soなどが存在するときには、このパスは汚染されているので SecurityError。存在しないときはファイルの探索を続けて C:/Program Files (x86)/ruby/lib/ruby/1.8/cgi.rb (このパスは汚染されていないはず)を読み込む、という動作なのだけど……。
実際はそうではないのだから tDiaryの
tdiary.rb:12: $:.insert( 1, File::dirname( __FILE__ ) + '/misc/lib' )
というのは __FILE__ が汚染されているときに、わりと危険な操作ということになる。問題が起きないのは SAKURAのレンタルサーバの Rubyが 1.8.6だからなのか、__FILE__、File.dirname(__FILE__) が汚染されていることが稀だからなのか。(汚染されていることが実際にあるのは、20090117p01で書いたように、untaintすることで状況が改善したことから推測できる)
問題が起きないのは SAKURAのレンタルサーバの Rubyが 1.8.6だからなのか、__FILE__、File.dirname(__FILE__) が汚染されていることが稀だからなのか。
両方でした。__FILE__が汚染されているのは Ruby-1.9.1RC1だから(多分)。
$SAFE=1のときに汚染された文字列を $LOAD_PATHに追加する(pushでも unshiftでも)と、一切の requireができなくなる。
書きながら誇張だとは気付いていたのだけど(一切の、の部分が)、そうでない例を自分で見つけたので追記(2009-02-02)。
Windowsで、フルパスで、あるいは拡張子(.rb)なしのフルパスでなら requireできる。
Y:\...\Desktop\a>irb
irb(main):001:0> RUBY_DESCRIPTION
=> "ruby 1.8.7 (2008-05-31 patchlevel 0) [i386-mswin32_90]"
irb(main):002:0> $SAFE=1
=> 1
irb(main):003:0> $:.push "".taint
=> ["C:/Program Files (x86)/ruby/lib/ruby/site_ruby/1.8", "C:/Program Files (x86)/ruby/lib/ruby/site_ruby/1.8/i386-msvcr90", "C:/Program Files (x86)/ruby/lib/ruby/site_ruby", "C:/Program Files (x86)/ruby/lib/ruby/vendor_ruby/1.8", "C:/Program Files (x86)/ruby/lib/ruby/vendor_ruby/1.8/i386-msvcr90", "C:/Program Files (x86)/ruby/lib/ruby/vendor_ruby", "C:/Program Files (x86)/ruby/lib/ruby/1.8", "C:/Program Files (x86)/ruby/lib/ruby/1.8/i386-mswin32_90", ".", ""]
irb(main):004:0> require "a"
SecurityError: Insecure operation - require
from (irb):4:in `require'
from (irb):4
from :0
irb(main):005:0> require "a.rb"
SecurityError: Insecure operation - require
from (irb):5:in `require'
from (irb):5
from :0
irb(main):006:0> require "./a.rb"
SecurityError: Insecure operation - require
from (irb):6:in `require'
from (irb):6
from :0
irb(main):007:0> require "Y:/.../Desktop/a/a"
=> true
irb(main):008:0> require "Y:/.../Desktop/a/a.rb"
=> false
irb(main):009:0> require "a"
SecurityError: Insecure operation - require
from (irb):9:in `require'
from (irb):9
from :0
irb(main):010:0>
2009年01月17日 (土)
♪ [Ruby][tDiary] 昨日(「引き続き rexml/source.rb:16の requireが SecurityErrorになる原因を探る」)の続き。
step1 load.c:147 (rb_feature_p) if (!load_path) load_path = rb_get_expanded_load_path(); step2 load.c:44 (rb_get_expanded_load_path) VALUE path = rb_file_expand_path(RARRAY_PTR(load_path)[i], Qnil); step3 Insecure Operation - require (SecurityError)
いました。Ruby1.9.1で SecurityErrorを量産する rb_get_expand_path()が。どうも、汚染された load_pathの一つを展開しようとして SecurityErrorになってる気がする。
$:($LOAD_PATH)の要素が汚染されてるのは、こちらの責任では?と思って確かめてみた。
SecurityErrorの直前で、$:の各要素が tainted?かどうかを TDiary::Config#debugを使って出力した結果。
D, [2009-01-17T23:36:46.289008 #1212] DEBUG -- : false Y:/server_root/www/ds14050/tdiary_on_ruby191 D, [2009-01-17T23:36:46.289008 #1212] DEBUG -- : true Y:/server_root/www/ds14050/tdiary_on_ruby191/misc/lib D, [2009-01-17T23:36:46.289008 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/site_ruby/1.9.1 D, [2009-01-17T23:36:46.289985 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/site_ruby/1.9.1/i386-msvcr90 D, [2009-01-17T23:36:46.289985 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/site_ruby D, [2009-01-17T23:36:46.289985 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/vendor_ruby/1.9.1 D, [2009-01-17T23:36:46.289985 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/vendor_ruby/1.9.1/i386-msvcr90 D, [2009-01-17T23:36:46.290961 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/vendor_ruby D, [2009-01-17T23:36:46.290961 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/1.9.1 D, [2009-01-17T23:36:46.290961 #1212] DEBUG -- : false C:/Program Files (x86)/ruby/lib/ruby19/1.9.1/i386-mswin32_90 D, [2009-01-17T23:36:46.290961 #1212] DEBUG -- : false .
ひとつ、ありましたね。tDiaryが該当パスを $LOAD_PATHに挿入する部分で、下のように untaintをつけるだけで理不尽な SecurityErrorが解決しました。(ただし、ASRでは依然 SecurityErrorになる。解決したのは、20090116p01で書いたように、load.cの 501行目をコメントアウトした Ruby-1.9.1RC1での話)
{kind=link}
{kind=link}
-tdiary.rb:12: $:.insert( 1, File::dirname( __FILE__ ) + '/misc/lib' ) +tdiary.rb:12: $:.insert( 1, File::dirname( __FILE__ ).untaint + '/misc/lib' )
今回の一連の流れ(20090113p01、20090114p01、20090116p01)で、$SAFE=1が、SecurityErrorで使い物にならなくなる(>添付ライブラリの requireにも失敗する)、二つのルートが見つかった。それらは requireするライブラリの拡張子を明示したり、$LOAD_PATHの中身をすべて untaintすることで回避できたり、load.cの一行をコメントアウトしたりで回避できたが、スクリプトで対処すべきものではないと考える。file_expand_pathが $SAFE>0のとき、汚染された入力を一切受け付けないという前提のもと、(rb_)file_expand_pathを呼び出しているコードを見直すか、file_expand_pathが汚染された入力を受け入れて適切に処理するか、どちらかの変更が必要だと思う。「file_expand_path()の結果が汚染された入力や $LOAD_PATHの汚染された一要素に基づくとき、その展開されたパスも汚染されている。」「$SAFE=1のとき、最終的に requireするファイルのパスが、汚染された引数や、$LOAD_PATHの汚染された要素に基づくとき、SecurityError。」というのではいけないのだろうか。Ruby-1.8.7はそのへんうまくやっているのだが……。
改めてドキュメントを読んだら、汚染された文字列を引数にした Fileのクラスメソッド、インスタンスメソッドは禁止されていた。($SAFE=1のとき)
ドキュメントに従うなら rb_file_expand_pathが SecurityErrorを出すのは正しいのかも(Ruby-1.8.7がまちがっている)。それならば、$LOAD_PATHの汚染された要素を不用意に展開しようとして SecurityErrorを出したり(load.c:44:rb_get_expanded_load_path)、もともと汚染されていなかった文字列を複数回展開しようとして SecurityErrorを出したり(load.c:501:search_required)するほうを修正しなければ。
私見では、(最下層で実際の仕事を行う)file_expand_pathは汚染フラグを適切に伝播させるものの SecurityErrorは出さないでおき、(スクリプトから呼ばれる)File.expand_pathの実体である rb_file_s_expand_pathか、file_expand_pathに仕事を丸投げする rb_file_expand_pathでセーフレベルに基づくチェックを行うのが、呼び出し側にとって便利だと思う。
tDiaryのプラグインの recent_list.rbを書き換えたのは、今思えば不要だったみたいだ。(Rubyの方が変わるに違いないもの)
2009年01月16日 (金)
♪ [Ruby][tDiary] Ruby1.9.1RC1で「Insecure Operation - require (SecurityError)」が頻発する原因。
20090113p01や20090114p01で発生したエラーを起こす最小のスクリプトとそれを回避する方法。
>type a.rb
puts "a.rb required."
>ruby19 -v
ruby 1.9.1 (2008-12-30 patchlevel-0 revision 21203) [i386-mswin32_90]
>ruby19 -e "$SAFE=1; require 'a'"
-e:1:in `require': Insecure operation - require (SecurityError)
from -e:1:in `<main>'
>ruby19 -e "$SAFE=1; require 'a.rb'"
a.rb required.
二つの違いは requireするライブラリの拡張子(.rb)を明示しているかどうか。拡張子なしの場合に発生する SecurityErrorは間違いだと思う。そうでないと $SAFE = 1がまるで使い物にならない。添付ライブラリだってまともに動かなくなるんだから。
ところで、Ruby 1.9 - 1.9.1 RC2 issues - Ruby Issue Tracking Systemにはチケットを作成するためのフォームがない。ruby-dev MLはアーカイブをときどき閲覧しているが購読はしていない。是非ともこの SecurityErrorは消して欲しいのだが、報告を受け付ける間口が狭い。直通ルートがない。どうすべ。
どうすべ、と言ってる間に原因究明。
load.c:500: type = rb_find_file_ext(&tmp, loadable_ext); load.c:501: tmp = rb_file_expand_path(tmp, Qnil);
501行目が不要に思える。そしてこれが SecurityErrorの原因。rb_find_file_extは内部で rb_file_expand_pathや file_expand_pathを呼び、その結果を tmpにコピーしてくれている。二度目を呼ぶ必要はないのでは? rb_file_expand_pathは適宜汚染されたStringオブジェクトを返し、また $SAFE>0のとき、汚染された引数を SecurityErrorで拒絶するので、複数回の (rb_)file_expand_path呼び出しは容易に SecurityErrorを引き起こす。これは Ruby1.9.1の、Ruby1.8.7とは異なっている動作。
>irb
irb(main):001:0> File.expand_path("a")
=> "Y:/a"
irb(main):002:0> File.expand_path("a").tainted?
=> true
irb(main):003:0> File.expand_path(File.expand_path("a"))
=> "Y:/a"
irb(main):004:0> $SAFE=1
=> 1
irb(main):005:0> File.expand_path(File.expand_path("a"))
=> "Y:/a" # $SAFE>0で、taintedな文字列でも展開する。(Ruby1.8.7)
irb(main):006:0> exit
>irb19
irb(main):001:0> File.expand_path("a")
=> "Y:/a"
irb(main):002:0> File.expand_path("a").tainted?
=> true
irb(main):003:0> File.expand_path(File.expand_path("a"))
=> "Y:/a"
irb(main):004:0> $SAFE=1
=> 1
irb(main):005:0> File.expand_path(File.expand_path("a"))
# $SAFE>0で、taintedな文字列を引数にすると SecurityError (Ruby1.9.1RC1)
SecurityError: Insecure operation - expand_path
from (irb):5:in `expand_path'
from (irb):5
from C:/Program Files (x86)/ruby/bin/irb19.bat:20:in `<main>'
irb(main):006:0>
問題設定が間違っていたのか? load.cの一行をコメントアウトしたことで、たしかに一つの SecurityErrorは消えたが tDiaryは動かない。20090114p01のエラーがまだ出る。
ただ、20090114のタイトルにちらっと書いた、open-uriの SecurityErrorはでなくなってる。
>irb19 (野良パッチ済み) irb(main):001:0> $SAFE=1 => 1 irb(main):002:0> require 'open-uri' => true irb(main):003:0> open 'http://www.example.com' => #<StringIO:0x2b8e924> irb(main):004:0>
比較として ASRでエラーが出るのを確認する。ただ、ASRでも二回目以降の openはエラーにならない。謎の挙動。この SecurityErrorも本来発生すべきものではないのだろう。
>"C:\Program Files (x86)\ActiveScriptRuby-1.9.1\bin\irb.bat"
irb(main):001:0> $SAFE=1
=> 1
irb(main):002:0> require 'open-uri'
=> true
irb(main):003:0> open 'http://www.example.com'
SecurityError: Insecure operation - write
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:375:in `write'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:375:in `<<'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:375:in `<<'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:322:in `block (3 levels) in open_http'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/protocol.rb:373:in `call_block'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/protocol.rb:364:in `<<'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/protocol.rb:88:in `read'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:2333:in `read_body_0'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:2288:in `read_body'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:321:in `block (2 levels) in open_http'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:1120:in `block in transport_request'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:2251:in `reading_body'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:1119:in `transport_request'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:1103:in `request'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:312:in `block in open_http'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/net/http.rb:564:in `start'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:306:in `open_http'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:767:in `buffer_open'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:203:in `block in open_loop'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:201:in `catch'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:201:in `open_loop'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:146:in `open_uri'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:669:in `open'
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/open-uri.rb:33:in `open'
from (irb):3
from C:/Program Files (x86)/ActiveScriptRuby-1.9.1/bin/irb.bat:21:in `<main>'
irb(main):004:0> open 'http://www.example.com'
=> #<StringIO:0x2b611a4>
irb(main):005:0>
引き続き rexml/source.rb:16の requireが SecurityErrorになる原因を探る。(tDiaryを起動しないと再現させられないのが辛い)
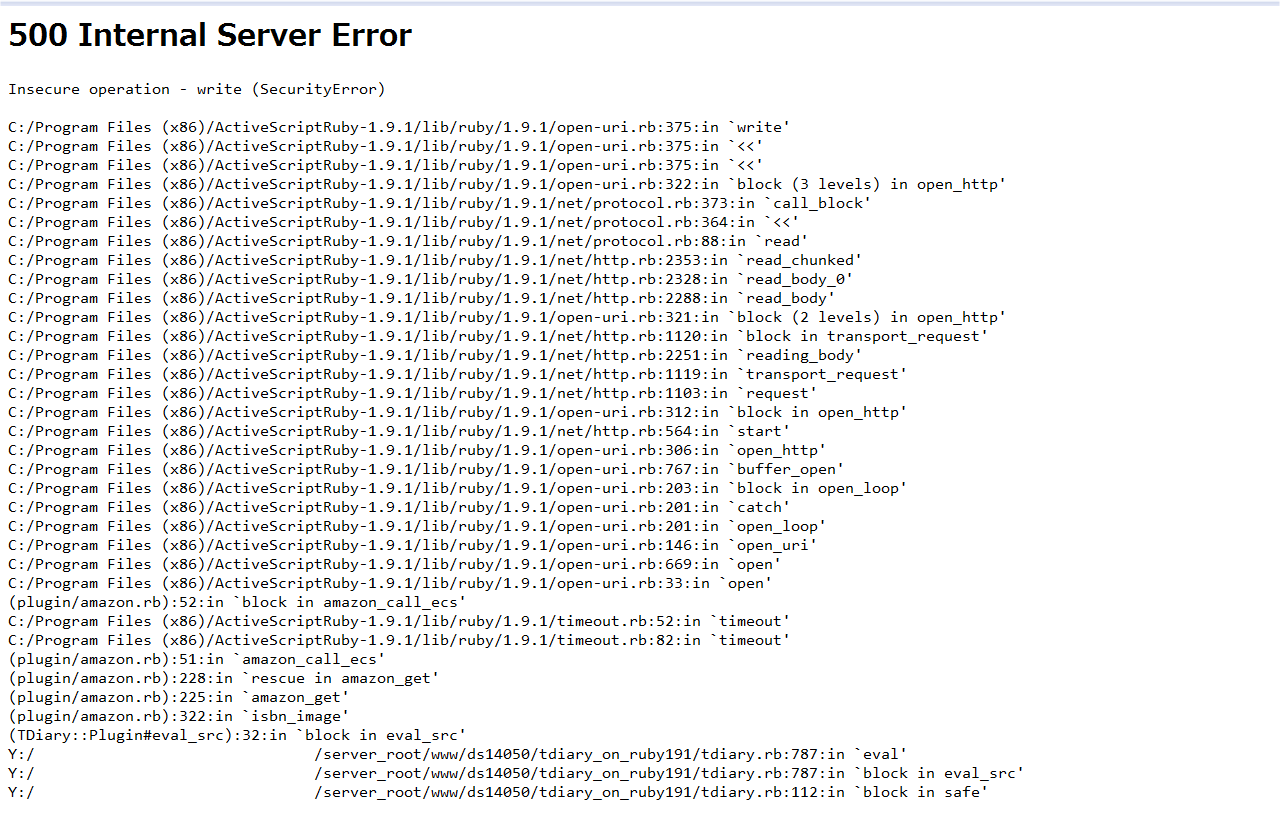
2009年01月14日 (水) $SAFE=1だと添付ライブラリ(open-uri)が SecurityErrorを出しまくるんだけど……。260行目の require 'net/http' で出る。375行目の StringIOに書き込むところでも出る。破綻してる気がする。
♪ [tDiary][Ruby] 昨日のつづき。recent_listを実際に修正。
方針は昨日書いたとおり、プラグインが自由に日記データを取得できる手段を提供した。
日記を一日書いたとたんにエラーということはなくなったみたい。

$SAFE=1で requireが失敗する(ファイル名の untaintもしているのに)のがそもそもおかしい。open-uriや rexmlで同様に requireで SecurityErrorエラーが生じていることからも、疑惑の目がウチの Rubyに向いてきた。「1.9.1RC1だから」ではなく「ウチでコンパイルしたから」、あるいは(開発者に)利用者が少なそうな 「Windows(それも Vista)だから」なのかもしれない。
ASRをインストールしてみたけどダメだった。同じ。tDiaryをセキュアモードで動かしているわけではないので Rubyのセーフレベルは最高でも 1。taintedな文字列を使った requireが失敗するならわかる。でも rexml/source.rbの 16行目は「require 'stringio'」だ。べったべたのリテラルだ。
500 Internal Server Error Insecure operation - require (SecurityError) C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/source.rb:16:in `require' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/source.rb:16:in `create_from' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/parsers/baseparser.rb:146:in `stream=' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/parsers/baseparser.rb:123:in `initialize' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/parsers/treeparser.rb:9:in `new' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/parsers/treeparser.rb:9:in `initialize' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/document.rb:228:in `new' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/document.rb:228:in `build' C:/Program Files (x86)/ActiveScriptRuby-1.9.1/lib/ruby/1.9.1/rexml/document.rb:43:in `initialize' (plugin/amazon.rb):231:in `new' (plugin/amazon.rb):231:in `amazon_get' (plugin/amazon.rb):322:in `isbn_image' (TDiary::Plugin#eval_src):32:in `block in eval_src' Y:/.../server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:787:in `eval' Y:/.../server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:787:in `block in eval_src' Y:/.../server_root/www/ds14050/tdiary_on_ruby191/tdiary.rb:112:in `block in safe'