2009年09月23日 (水) Subversionの嫌なところ - 日記を書く [・w・] はやみずさん < 既に存在するリポジトリの形式はサーバープログラム(svnadminとか)をアップデートしたとしても自動ではアップグレードされないことになってる。明示的にコマンド(svnadmin upgrade)を打つか DUMP&LOADするまで。だから古いクライアントプログラム(svn)がお行儀悪く fileプロトコルでリポジトリを直接読もうとしても(他に原因がなければ)失敗はしないんじゃないかと。濡れ衣くさいので書いた。 <追記@2010-04-21>ワーキングコピーの話だったらそれはアップグレードされる。所詮ただのコピーなんだからクライアントごとにチェックアウトすればいいんですよ。</追記>
最終更新: 2013-04-29T21:18+0900
♪ [SakuraEditor] 矩形選択を普通の選択と同じ操作感に。(Shift+○という操作を Alt+○に置き換えるだけ)
いままでは、Alt+矢印で矩形選択モードに入った後、Altを放して、それから選択範囲の拡大を(矢印で。Shiftは不要)行う必要があった。また、知らないうちに矩形選択モードに入ってしまっていて驚かされることも何度かあった。それら、Altを放す必要や知らぬ間のモード変更がなくなる。
2000年にはそのための布石というか、コメントアウトされたプレースホルダが用意されていた。そのおかげで、全くたいしたことはしてないのだけど、これまで放置されてきた理由なり原因なりを何か見落としてる?
差分更新
- easy_box_selection.rev2.txt (30.6KiB, 2010-04-13)
- trunk2@1732に対する差分。
- キー割り当ての初期設定の間違いを一つ修正。
- 折り返し行頭への移動が本当の行頭(改行文字の直後)への移動だったのを修正。
@2013-04-27 Mocaさんによるパッチ
Sakura Editor / PatchUnicode / #449 矩形選択移動コマンドの追加
俺みたいにありもののコマンドで間に合わせるのでなく、足りないコマンドの実装までされています。
今思うと矩形選択しながらの、(折り返しでない本当の)改行単位での行頭・行末移動は不要だった気がする。プレースホルダはあったけど、使わないでしょう? 改行単位の GoLineEnd自体は、矩形選択と組み合わせては使わないにしても、なくて不便だった(20120227p01.02)ので必要だけど。
残念なのは、既存ユーザーの sakura.iniには Alt+↑、Alt+↓、Alt+←、Alt+→に対する「矩形選択開始」の割り当てが既に書き込まれていること。勝手に設定を書き換えることはできないから、プログラムをアップデートしただけでは利便性の増した矩形選択に気付けない。関連するキー割り当てがデフォルトのときだけ書き換えてしまうのはありかもしれない。アップデート後1回だけ ini書き換えを実行するために、iniにフラグのための項目を増やすことが考えられる。WSHで独立したスクリプトを書く方がオーバーヘッドは少ないが、実効性は著しく下がりそう。別に隠れ機能でもいいけどね。よく使う人ほどこれまでの操作に慣れてるだろうから。ヘルプに2通りの操作があることを書いておけば気付くでしょ。でも、慣れてるけど不便だと思ってる人に気付いてもらえないなあ。俺みたいにリリースノートを嬉々として読む人間ばかりではないだろうし。
2009年09月22日 (火) [790FX-GD70] BIOS v1.5
最終更新: 2016-03-05T00:30+0900
♪ [SakuraEditor][正規表現] 正規表現を使った検索・置換で、改行の意味を LFのみから CRも含むように。
経緯 > サクラエディタBBS[r7030]
差分 > fix_cr_handling_of_regex(下に修正版がある)
お試し > sakuraW.zip (547KiB)(下に修正版がある) (正規表現検索・置換を試すには bregonig.dll(Unicode対応版)が別途必要)
検索、置換を数度試したが機能しているみたい。ただ、$ が本当に改行の手前でマッチする関係で
^.*$
を空文字列に置換するという最初に提起されたケースでは、置換後の空行までが置換対象になってしまう(置換回数が 2倍)。目的に適う、より適切なパターンは
^.+$
あるいは、エディタの行置換機能を使っているのだから、もっと単純に
.+
で良い。
@2009-09-24
「正規表現 - SakuraEditorWiki」を見ていて気付いた。\c[、\c]、\c$、\c. という制御文字のひとつを表すパターンが存在する。「鬼車 正規表現 Version 5.9.1」によれば \C-[、\C-]、\C-$、\C-.、\M-[、\M-]、\M-$、\M-. も存在しうる。\M-\C-[ なども存在しそうに思ったけど、これはこういう結果になった。
irb(main):001:0> /\M-\C-[/
SyntaxError: (irb):1: too short escaped multibyte character: /\M-\C-[/
from c:/Program Files (x86)/ActiveScriptRuby-1.9.1/bin/irb.bat:20:in `<main>'
irb(main):002:0
制御文字なんて扱ったことがないからなあ(もはや relicだという認識)。対処の必要性がさっぱり感じられないけど……。
@2009-09-25
一括置換で $ が CRLFの CR直前、LF直前、LF直後(正規表現DLLに与えた文字列末尾)の三カ所にマッチしてしまうとの指摘 >サクラエディタBBS[r7039]。
逐一、置換を実行した場合は問題ないことを確認していたのだが、一括置換はライブラリに全部お任せで、検索開始位置を調整することもできないから動作が違っていたのだろう。$ が CRと LFの間にマッチするのはわかっていたが、明示的に \r を食べた場合にだけ影響があると思っていた。一括置換なんてありふれた操作でそれが明るみに出るとは思いもせず。
急いで修正 > fix_cr_handling_of_regex.rev2、sakuraW.rev2.zip (547KiB)(さらなる修正版 rev3が下に)
初めて戻り読みを使った。なんとなく反則的な手段の気がして、使わないですむ方法をいつも考えるのだけど無理だった。これで bregonig.dll依存が決定的になった。[] の入れ子のことだけなら ] が見つかったときに charset_levelを一気に 0 にするだけで BREGEXP.DLL対応もできたのだが。
\C-X、\M-X というのは Ruby向けなのかも。サクラエディタ(+bregonig.dll)で \C-[ を検索しようとすると「premature end of char-class」というメッセージが出る。となれば、\cX だけが引っかかった小骨ということになる。
対処 > fix_cr_handling_of_regex.rev3、sakuraW.rev3.zip
<追記>bregonig.dllでは \c\X が \cX の意味になるとか。もう知らねー。</追記>
個人プロジェクトでもないと色々大変そう。ドッグフードでも食べながら様子見します。とりあえず反応だけ。
2.非対応となっているBREGEXP.DLL(ANSI版)への対処方法 ANSI版とUNICODE版は別仕様としてしまうのか?
使用できる正規表現自体が別物なので BREGEXP.DLLは CBregexp::MakePattern()でよいかと。ユーザーを驚かさないための変更なので、. が \r にマッチすることを期待していた人以外に影響はないつもりでいる。
<追記>ANSI版+bregonig.dll向けのパッチを用意したので、別仕様は ANSI版+(BREGEXP.DLL/bregonig.dll)と Unicode版+bregonig.dllの間、または、 ANSI版+BREGEXP.dllと (ANSI版/Unicode版)+bregonig.dllの間のどちらでも選べる。BREGEXP.DLLのサポートするオーソドックスな(戻り読みをサポートしない)正規表現で、$を改行直後の行文字列終端にマッチさせない方法が見つからない限り BREGEXP.DLL対応は無理。</追記>
<追記>BREGEXP.DLL版も用意した。>_ANSI.rev2 >_ANSI.rev3</追記>
3.$ が改行なし最終行のEOF手前ともマッチするように改善すること $ を (?=\r\n?|(?<!\r)\n|(?<[^\r\n])$) に置き換える方法を試してみたけどエラーで動きませんでした。
肯定の戻り読みは (?<=) でした(なにせ使用経験がないもので)。気を取り直して、パターンを (?=\r\n?|(?<!\r)\n|(?<=[^\r\n])$)* に置き換えたところ、検索は予想通り、最終行がEOFのみの場合を除いて文書末にマッチするようになったのだけど、置換が行われない。(以前は行われていたのだろうか? マッチのインデックスが文書の長さと同じ(=1つはみ出した状態)になっているはずだから特別な対処が必要なのだろう)
「以前は行われていたのだろうか?」< 行われていなかった。なら、(間違ってるけど)おいておこう。
4.検索強調表示が検索時の選択反転表示と一致すること $ を (?=\r\n?|(?<!\r)\n) に置き換えた版で $ を検索すると、改行文字自体は選択反転表示にはならない(マッチしない)のに検索強調表示されている。 また、なぜか上方向検索では改行文字自体にマッチしたかのように選択反転表示になる。
$で検索したときに改行文字が強調表示されるのは、幅0のハイライトには意味がないので、実用面から今のように最低でも幅 1を保つべきだと思っていた。
上検索で改行が選択されてしまうのは間違いなので修正したい。これまでが、知らず $ が改行にマッチする仕様に依存していたのかもしれず、こういう修正は正しい方向に向かうためのものだと考えている。
修正した(rev4)。無限ループを避けるためにマッチ幅が 0のときに検索開始位置を特別にインクリメントするんだけど、そのタイミングが悪くて検索開始位置だけでなくマッチの範囲までがインクリメントされていたのが原因。
5.正規表現キーワードでの $, . 指定も検索・置換と挙動が一致すること 現状、正規表現キーワードには $, . に検索・置換でやっているような細工が入っておらず、素の正規表現ライブラリ挙動になっている模様。 検索・置換時の . の細工([^\r\n]への置換)が追加されると、今よりも差異が大きくなって混乱しそう。
すでに書いたように、. が \r にマッチすること、$ が CRLF の真ん中にマッチすることを期待していた人(いるのか?)以外は違いに気付かないだろう。
\r\n$ みたいな書き方をしていた場合にマッチしなくなる。このケースはなくはないかも。
6.検索・置換や正規表現キーワードの複数行対応への順応性
ノーチェック。sフラグが含まれる( . があらゆる文字にマッチするようになる)ときには . を置き換えないようにする、mフラグが含まれない( ^、$ が行頭、行末にマッチしなくなる)ときには $ を置き換えないようにする、とか?
>fix_cr_handling_of_regex.rev4、sakuraW.rev4.zip
2ch民は 1.6.5.0をつかうのね。♥マークはいらないんだ。Consolasも使いたくない⁑んだ。(これは俺の理由だけど) r1663を使おうぜ。
@2009-09-28
Unicode版Revision1662>http://sakura-editor.svn.sourceforge.net/viewvc/sakura-editor?view=rev&sortby=date&revision=1662
Ansi版Patch>http://sourceforge.net/tracker/?func=detail&aid=2869238&group_id=12488&atid=312488
勘違いしていた。Unicode版のサクラエディタで使用できる正規表現ライブラリは bregonig.dll(Unicode版)だけだ、という事実がいつの間にか、bregonig.dllは Unicode版専用だ、という思い込みにすり替わっていた。
だったら、採用の可否はともかく、Ansi版(trunk2の (Release|Debug)_Ansiビルドのことでなく trunkのビルド産物のこと、だろう)向けのパッチを作成する意味はあるわけだ。CBregexpのインスタンスがその寿命を通じて 1つの DLLだけを扱うのであれば、コストを初回に払うだけで、処理の振り分けを行うことができる。どっちかな?
>>> DLL初期化時に呼ばれる仮想関数がありました。(そのたびにチェックを行えばいい。実際は 1回しか呼ばれないだろう)
CheckRegexpSyntax() は癌だ。検索ボタンを押すたびに DLLのロードからはじめて、文法をチェックしたら使い捨てるって何事。文法チェックは Compile()で十分。その後の Match()のための準備にもなってちょうどいい。もろもろの手順を共通化したいのなら引数として CBregexpを受け取るべきだ。正規表現のチェックをしたい(=正規表現を利用したい)部分ではもちろん CBregexpなりなんなりをすでに持っているだろう。CheckRegexpSyntax()がこんな重量級のローカル変数をもつ必要はない。無効な検索パターンを履歴に追加したくないがために、検索の主体でない検索ダイアログが利用しているのかもしれないけど。
@2009-09-29
やっつけで一応。これで昨日書いた「コストを初回に払うだけで、処理の振り分けを行うことができる」が事実になった。昨日の段階では、検索ボタンを押すたびに DLLがサポートする文法をチェックする関数が実行されていた(初回どころではない)。これでもまだ、検索ボタンを押すたびに Compile()が 2回走るのは変わっていない。
おまけとして、bregexp.dllだけが sakura.exeの隣にある状態でエディタを起動し、その後 bregonig.dllを配置したとき、検索ダイアログでは 「bregonig.dll Ver....」と表示され、bregonig.dllしかサポートしない戻り読みを使用しても正規表現エラーにはならないものの、実際の検索には bregexp.dllが使用されるためだろう、戻り読みが機能していればマッチするはずの条件でもマッチ無しになってしまう、こういう、説明もややこしい起こりづらい状況が起こらなくなる。(文法チェックと実際の検索が CBregexpの同じインスタンスによって行われるようになるから)
本当は CBregexpが CDllHandlerを継承するのをやめて分離して、1つの CDllHandler(DLLインスタンス)を多数の CBregexp(BREGEXP構造体)から参照するのがいいのかも。もっといえば、BREGEXP構造体もコンパイル済みパターンとマッチ結果に分離したい。サポートする文法の情報はもちろん DLL付きの情報。CDllHandlerは汎用的すぎるから、その任には、CDllHandlerを継承したいまの CBregexpから BREGEXP構造体だけを追い出したものを充てればいい。
いまの CBregexpは InitDll()を呼び出されて、途中で違う正規表現ライブラリを読み込まされたとき、コンパイル済みの BREGEXP構造体を正しく解放できるのだろうか?
@2009-10-01
BREGEXP.DLLでも . と $ を置き換えるようにしてみた > fix_cr_handling_of_regex_ANSI.rev2(下に rev3)
副作用があって、XYZ(CR)(LF) という行に対して XYZを検索すると XYZ(CR)(LF) がマッチする。マッチ結果が改行に隣接しているとき、改行がマッチに含められます。$を検索すると (CR)(LF) がマッチするのは以前からの通り。ここが変わらないのは、一括置換での過剰な置換を防ぐ手立てがこれしか BREGEXP.DLLからは与えられていない、ということ。
ついでに気になった、\r\n を検索したときステータスバーに 1 bytes selected. と表示されるのを修正。>fix_selection_area_and_selected_byte_count_ANSI 選択領域が中途半端なサイズだったのも直った。それもこれも CLayoutが EOLの長さを常に 1とカウントしていたせい。マッチ範囲が勝手に 1切り詰められていた。
表示としては ↵ も ⇠ も ⇣ も同じ一字だから CLayoutのすることにも一理あるのかもしれない。それなら改行文字の部分の選択領域をせめて全角幅にして検索結果のハイライト部分と大きさをそろえよう。
ANSI版の View関連のソースを見てたら気が遠くなる。Unicode版で
- CRLFを全角幅で表示
- CRLFの CR、LFのみハイライト、選択
- LF、CRの全角表示、全角幅選択(or半角幅ハイライト)
- 行頭マッチ(^)でキャレット描画
あたり、なんとかならんかな。検索結果の選択範囲とハイライト領域のずれが気になる。
@2009-10-03
ANSI版を BREGEXP.DLLと組み合わせているときに、不必要に改行が検索結果に含まれてしまう場合を rev2より大幅に減らした。意地悪なパターンを与えられたときにどうなるかは把握しきれていない。
> fix_cr_handling_of_regex_ANSI.rev3(rev2と rev3にバグ発覚。rev4へ)
fix_cr_handling_of_regex_ANSI.rev4
どういうバグだったかというと、一括置換をしたときに改行や行文字列末尾付近で過剰に置換が行われないように、戻り読みが使えない BREGEXP.DLLのときは検索パターンと置換文字列に細工を施すのだけど、検索パターンの置き換え方がまずかった。
誤: /A|B/ -> /A|B((?:\r\n?|\n\r?)?)/ 正: /A|B/ -> /(?:A|B)((?:\r\n?|\n\r?)?)/
選択 | の結合順位は一番低いのでした。
バグは CBregexp.cppを好き勝手にいじっていた結果をテストしている最中にたまたま見つかった。
- メンバ関数に constをつけたり
- 正規表現フラグを指定する引数の型を intから専用のものに変えたり
- CBregexp::IsLookAhead(const char *pattern)が内部状態を変更して、CBregexp::Match()の結果に意図しない影響を与える可能性を排除したり
していた。これは単なる自己満足。
@2009-10-04
不必要に選択範囲が改行にかかっていたケースををさらに減少。> fix_cr_handling_of_regex_ANSI.rev5 検索パターンが LF直前や文字列末尾に幅0マッチしそうなときにだけ細工を行うことにした。なんというか、盆栽趣味?
バイナリ>sakura.zip
@2009-11-25
AINI版では LFCRの LFと CRの間に幅0マッチしそうなときも細工を行わないといけないだろうな。やらないけど。(LFCR?なにそれ?という立場)
2009年09月12日 (土) ブラウザとエディタで確認した。Ctrl+BackSpace、Ctrl+Deleteで単語単位の削除。
最終更新: 2011-03-25T01:34+0900
♪ [SakuraEditor] シンボリックリンクを開いたとき、更新通知の無限ループ
そして素朴な疑問。選択肢が 4つあるんだけど
- 再読込(&R)
- 閉じる(&C)
- 以後通知メッセージのみ(&M)
- 以後更新を監視しない(&N)
閉じるをクリックしても予想に反してエディタは閉じられないのと、(延々と表示され続けてもおかしくない)通知メッセージはどこに出ているのか?
@2010-07-08 補足。
シンボリックリンクを開くと、ショートカットファイルを開いたときと同じようにターゲットファイルの内容がエディタに表示される。そして他で何もせずとも、最初に必ず更新通知ダイアログが表示される。だから「再読込」を選ぶと読み込み後にまた更新通知ダイアログが表示されることになって無限ループ。「閉じる」(=ダイアログを閉じる=更新を無視する)を選ぶと今度はターゲットファイルが本当に更新されたときも察知できなくて永遠に黙る。
対策は、シンボリックリンクを開いていることを意識して、常に(ファイルの読み込みと更新監視で共通して)ターゲットファイルの更新時刻を調べるようにすること。
っていうほど単純でもない。更新日時だけ特別扱いしたらファイルの属性に一貫性がなくなる。更新監視部分でだけターゲットファイルの更新日時を比較するのが影響範囲が最小だけど更新日時を保存するメモリ領域をどこかの管理下に用意しないといけない(だれが管理する?もちろん CEditDocのメンバの CAutoReloadAgent)。一番面倒がないのはシンボリックリンクのターゲットをたぐってそのファイルを開いたことにすること(ショートカットと同じ)。なんとなくこれが嫌なのはカレントディレクトリが変わってしまうこと。他にもいろいろあると思う。ショートカットでなくシンボリックリンクを使うのは、ターゲットファイルがそこにあるようにアプリケーションをだましたいときだから、サクラエディタも(今はタイムスタンプ取得方法の一貫性のなさからかおかしなことになっているうえ、だまされているせいで更新の監視ができていないが)上手にだまされてほしい。
@2010-07-08 更新通知ダイアログがわかりにくい
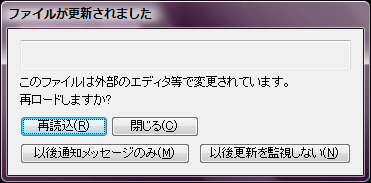
- 「閉じる」って何を閉じるの?
- 「以後通知メッセージのみ」「以後更新を監視しない」って結局再読み込みするの?しないの?
ので、こうした(improve_fileupdatequery_dialog.patch)。
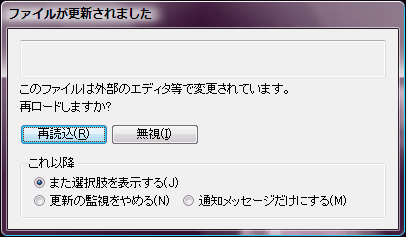
わかりにくいと感じてるのは俺だけじゃなくて、sakura-dev:3014で wmlhq氏が書いている。
なお、更新通知ダイアログはわかりづらいようなので、次のようにしてください。 ---------------------------------------- <!> このファイルは別のプログラムによって変更されました。 読み直しますか? ---------------------------------------- [ ]今後、ステータスバーに通知する [ ]今後、通知しない ---------------------------------------- [はい] [いいえ] ----------------------------------------
日記を書く段になって見直したんだけど wmlhq氏のメッセージのほうが良い。
- 「更新の監視をやめる」という俺のメッセージは不正確だから。(タイマーは常に動いていて、タイムスタンプの比較をしなくなるだけ)
- 通知メッセージがステータスバーに表示されることがわかる。
- サルでも答えられる Yes/Noクエスチョン。
2009年09月02日 (水)
最終更新: 2009-09-02T23:44+0900
♪ [SakuraEditor] http://coderepos.org/share/browser/platform/sakura-editor/
キーワードファイルなんかはみんなでいじくって改善するのにちょうどいいものだと思ったら、やはり、CodeReposにあった。ただし PHPのみ。
キーワードの羅列には興味がないけど(php-mkkwd.phpは別)、正規表現キーワードは共有して他人のも見てみたいなあ(楽ができるから)。javascript_re_keywords.rkw。Ruby_re_keywords.rkw。
2009年08月25日 (火) Emacsってイーマックスだったのねん。エマックスだとばかり……。VMAX(名前からの連想)みたいなデカブツは好みじゃないんだよね……って、どちらも重量級だからそれでいいのか。Emacsは(名前も含めて)好きにならないだろう。
最終更新: 2010-05-19T17:19+0900
♪ [SakuraEditor] クォーテーション文字列の色分け。
確かに変ですが、ここの部分をきっちりやろうとするとレイアウト処理性能にシビアに影響するみたいです。 ざっと試したところでは、ファイル読み込みで1.5~3倍くらいの処理時間がかかるようになってしまいました。 右端で折り返す設定で画面幅を変化させるときの応答にも同様に効いてきます。
さらりと、できなくはないと書かれているが、どうやるんだろう?
sakura_core\view\colors\CColorStrategy.cpp の後半(「色開始」部分)をこう書きかえてみても中途半端な結果。ファイルの内容は同じでも、文字の追加や削除、アンドゥなどの操作によって、意図通りの結果になったり現行通りだったり。処理速度に関しては、5MBのファイルを開いてファイルタイプをいろいろ切り替えてみたら、変更前よりプログレスバーの進みが明らかに遅い。1.5から 2倍というのは体感に一致している。
bool CColorStrategyPool::CheckColorMODE(
CColorStrategy** ppcColorStrategy, //!< [in/out]
int nPos,
const CStringRef& cLineStr
)
{
//色終了
if(*ppcColorStrategy){
if((*ppcColorStrategy)->EndColor(cLineStr,nPos)){
*ppcColorStrategy = NULL;
return true;
}
}
//色開始
if(!*ppcColorStrategy){
for(int i = 0; i < (int)m_vStrategies.size(); ++i) {
if(m_vStrategies[i]->BeginColor(cLineStr, nPos)) {
*ppcColorStrategy = m_vStrategies[i];
break;
}
}
}
return false;
}
違う。CheckColorMODE()のときに正規表現キーワードは働いてない。そもそも CheckColorMODE()の目的って? CLayoutMgr::Match_Quote()がとりあえず行末を返す( return cLineStr.GetLength(); )のって? それでどうやって行をまたげているんだろう。
白々しさ爆発だけど書く。下は sakura/trunk2/sakura_core/doc/CLayoutMgr_DoLayout.cpp から削除されたコード(の一部)。この部分が修正を加えられたうえで sakura_core/view/colors/CColorStrategy.cppに移動している。return falseを使わずに breakしているあたりがさらに嘘くささを増してるけど、別に、このときの変更をロールバックしたかったわけじゃない。知らなかったし、参考にしたのは SColorStrategyInfo::DoChangeColor()の方。
if(!*ppcColorStrategy){
CColorStrategyPool* pool = CColorStrategyPool::Instance();
for(int i=0;i<pool->GetStrategyCount();i++){
CColorStrategy* pcSample = pool->GetStrategy(i);
if(pcSample->BeginColor(cLineStr,nPos)){
*ppcColorStrategy = pcSample;
//bRet = true;
break;
}
}
}
俺が感じたプログレスバーの進みの遅さはたぶん基底クラスからの仮想関数の呼び出しに伴うものだったんだろう。一歩戻って進んで、ふりだしに戻る。
CheckColorMODE()がないとクォーテーション文字列が行をまたげない。
レイアウト(禁則処理とか折り返しとか)とクォーテーション文字列(+コメント)の関係がわからない。癒着してるなら、ボトルネックにもなってるらしい CheckColorMODE()をなくして、正規表現キーワードが行をまたぐことでカバーしたい。
@2010-05-19 関連ログ発見
http://sakura-editor.sourceforge.net/cgi-bin/cyclamen/cyclamen.cgi?log=dev&v=4079#4083
サクラエディタの色分け解析ルーチンは、全部で3つあって、
- 行データの変更に、各レイアウト行の先頭色を決めるもの(CLayoutMgr)
- 実際の作画時に各文字の色を決定しつつ作画するもの(CEditView::OnPaint)
- 対括弧の色を戻すときに各文字の色を決定するもの(CEditView::GetColorIndex)
2009年08月24日 (月) [Vista] エクスプローラは痴呆気味だけど「>explorer .」でカレントディレクトリを開けるのがえらい。MDIEに乗り換えなかった理由の一つ。
最終更新: 2009-09-24T04:29+0900
♪ [SakuraEditor] 最近使ったファイルを名前でソートしないで!
方法は sakura/trunk2/sakura_core/sakura_rc.rcから CBS_SORTを一か所削除するだけでした。CRecentImp.AppendItem()が名前に反してあえて「アイテムを先頭に追加」しているけど、俺もそれが自然だと思う。「開く...(ドロップダウン)」ツールバーボタンから出るポップアップメニューには CBS_SORTみたいなフラグがないのだろう。ソートはされていない。望み通り。でも Windowsはスタートメニューの最近使った項目をファイル名でソートしてる。そういう考え方もあるんだろう。好きにやります。
ダイアログつながりで、拡張子補完も完全に切った。お節介は不要。拡張子補完って主にエクスプローラで拡張子を隠したままにしてる人のためにあると思う。
2009年08月08日 (土) docs.tdiary.orgがルートから 403 Forbiddenで読めない。プラグインの説明が読めない。
最終更新: 2019-12-01T02:10+0900
♪ [SakuraEditor] サクラエディタの正規表現キーワードを SHJS相当にしたい。
行単位で処理してるのはどちらも同じだし、サクラエディタの既存の設定はすべて State0のパターンとして扱えばいい。行をまたぎたいときや凝った処理がしたくなって初めて State移動を使えばいいだけのこと。patternStackと currentStyleを行ごとにキャッシュしておけば、変更のあった行から即座に色分けを再開できるはず。文書の最初から色分けをやり直す必要はない。変更のあった行より後ろの行にジャンプするときは、変更によって何行後ろまでの patternStackと currentStyleに変化を与えたか、というキャッシュが無効化される範囲を見極める時間が必要になりそう。*.cファイルの編集中に /*の *を削除したりアンドゥしたりしたあとで Ctrl+Endするのは厳しいですよ、と。patternStackは一行一行でそうそう変化するもんじゃないからキャッシュの圧縮が効きやすいだろう。(妄想するだけなら気楽だなあ)
@2009-09-06
色分けが正規表現キーワードだけによって行われるのでないところが難しい。他の色分け機能(コメントとか文字列とか強調キーワードとか)による先食いを考えないといけないから。
今のサクラエディタで、正規表現キーワードで引用符を食べるとその行では組み込みのクォーテーション文字列の色分けが無効になるけど、次の行からクォーテーション文字列が始まってしまう理由がわかった気がする。その逆をやろうとしていたことに今やっと気付いた。正規表現キーワードも先食いされる可能性を考えないといけない。
@2009-09-07
ショック! BREGEXPのインターフェイスには検索開始位置を指定するパラメータ ――JavaScriptでの /pattern/g.lastIndex―― がない。対象文字列を指すポインタを進めればそこ(文字列途中)が開始位置だ、と言ってよいものではない。それでは ^ のようなアンカーが毎回マッチしてしまうだろうから(試したわけではない)。むむむ。BREGEXPには引退してもらいたい……。サクラエディタは自前で特定のパターン(行頭・行末アンカー、先読み)の有無を、検索パターンに対するパターンマッチングでチェックしてますね。怪我の元に思えるので避けたい方法だけど、これまで信じられないぐらいうまく動いてるのは事実(でも半信半疑)<追記>bregonig.dllや Bregexp.dll for SAKURAを使用しているときは BMatchEx(これは検索開始位置を示すポインタが引数の1つに加えられている)が使用されていたのだった。道理でソースを見ながらいじわるなパターンを与えても正しく動いたはずだ。ちなみに鬼車の APIではさらに検索終了位置を指すポインタを、対象文字列末尾を指すポインタとは別に渡せる。</追記>年代が違うから比較は酷だけど、Javaだか .NETだかの正規表現では渡した対象文字列の、(あるかもしれない)続き次第でマッチ結果が変わってくる可能性をさえ知ることができたはず(よく知らない。そこまでするか、と驚いた記憶だけがある)Javaだった。
正規表現リテラルの影響があるのも嫌だな。パターンとフラグをスラッシュで連結せずに別の引数に分けたら、パターンの中のスラッシュをエスケープする必要がなくなるのに。preg_matchを思い出した。文字列で正規表現リテラルを表現しようだなんて(笑止)。リテラルである(=余分なエスケープが必要ない)ことに価値があるのに、引用符とスラッシュで二重にパターンを囲ませる意図がわからない。
<追記@2009-09-23>サクラエディタのソースにエスケープを付加する処理が見あたらないなと思ったら、スラッシュでなく 0xFFFF をデリミタに使用していた。なるほど。パターン中にそんな値は出てこないだろうな(そんな気がするだけ)。0xFEFFや 0xFFFEは BOMだけど、0xFFFFは空いてるのかな。</追記>
@2009-09-08
CColor_RegexKeywordだけをいじるんでなく、CColorStrategy関連を作り直して CColor_*をそれに対応させるのがゴール(だということに気がついた)。CColor_Quoteに対する特別扱いをレイアウト部から切り離して SColorStrategyInfoに内包させる、みたいな。SColorStrategyInfoは CColorStrategyのドライバという位置づけ。
でもやっぱり色分けにレイアウトがからんでくるのがわからない。SColorStrategyInfoのメンバの
//参照 CEditView* pcView; CGraphics gr; //(SColorInfoでは未使用) //描画位置 DispPos* pDispPos; DispPos sDispPosBegin; CLogicInt GetPosInLayout() const; const CDocLine* GetDocLine() const; const CLayout* GetLayout() const;
こういうの。
与えられた行に対して、これからはそれより前の行の色分け結果も参照しつつ、一行分の色分け結果をまとめて返すから、描画はそちら(CEditView)でどうぞ、検索語のハイライトとの重ね合わせもそちらでよろしく、といいたいんだけど。
CColor_* って 1つのインスタンスを 1つのプロセス(=1つのドキュメント)で使い回してるのに、(1つの行、直前のメンバ関数の呼び出し、に依存した)状態を持ってるってのが嫌。strtok()並に嫌い。そういうのも SColorStrategyInfoに移したい。
BREGEXPの情報は「BREGEXP DLL」を見てたんだけど、そこには載ってない BMatchEx()というものもあるみたい(どこにあるのかは知らない)(BSubstEx()もあった)。サクラのソース(CBregexpDll2.h)でみつけた関数の型はこう。
typedef int (__cdecl *BREGEXP_BMatchExW2) (const wchar_t* str, const wchar_t* targetbeg, const wchar_t* target, const wchar_t* targetendp, BREGEXP_W** rxp, wchar_t* msg); typedef int (__cdecl *BREGEXP_BMatchW2) (const wchar_t* str, const wchar_t* target, const wchar_t* targetendp, BREGEXP_W** rxp, wchar_t* msg);
これは期待できるなあ。
ざっと検索して一か所でだけ BMatchEX()が使われていた。CBregexp.cppのこの部分
// 拡張関数がない場合は、行の先頭("^")の検索時の特別処理 by かろと
if (!ExistBMatchEx()) {
/*
** 行頭(^)とマッチするのは、nStart=0の時だけなので、それ以外は false
*/
if( (m_ePatType & PAT_TOP) != 0 && nStart != 0 ) {
// nStart!=0でも、BMatch()にとっては行頭になるので、ここでfalseにする必要がある
return false;
}
// 検索文字列=NULLを指定すると前回と同一の文字列と見なされる
matched = BMatch( NULL, target + nStart, target + len, &m_pRegExp, m_szMsg );
} else {
// 検索文字列=NULLを指定すると前回と同一の文字列と見なされる
matched = BMatchEx( NULL, target, target + nStart, target + len, &m_pRegExp, m_szMsg );
}
「拡張関数がない場合」もあるんですか……。BMatchExの google検索結果もたった 7件だなあ。UNICODE版の正規表現DLLは bregonig.dllしかないから BMatchEx()が存在するものとして BMatch()対策はいらないな。
@2009-09-12
BMatch()の戻り値は int。だが boolean扱いしてはいけない。BMatch関数のサンプルとして
while (BMatch(patern1,t1+pos,t1+lstrlen(t1),&rxp,msg)) {
(マッチング結果の処理)
}
みたいに書いてあるので騙されたけど、サクラエディタの CBregexp.cppにはこうある。
// 検索文字列=NULLを指定すると前回と同一の文字列と見なされる matched = BMatchEx( NULL, target, target + nStart, target + len, &m_pRegExp, m_szMsg );
if ( matched < 0 || m_szMsg[0] ) {
// BMatchエラー
// エラー処理をしていなかったので、nStart>=lenのような場合に、マッチ扱いになり
// 無限置換等の不具合になっていた 2003.05.03 by かろと
return false;
} else if ( matched == 0 ) {
// 一致しなかった
return false;
}
負数の時はエラーらしい。なんだこの落とし穴。そしてパターン文字列を何度も渡さなくてよいという新事実。struct BREGEXP.parapにパターン文字列が保持されてるから 2回目以降の呼び出しでは 2つのパターン文字列(異なっているかもしれない!)を渡すことになるのが気持ち悪かったのだ。ひょっとしたら 2つのパターン文字列を比較して、違っていたら再度コンパイル、みたいな処理があるかもしれないじゃない(そんな処理があってもなくても嫌だ)。
@2009-09-14
レイアウトと色分けの関係。変更のあった行を知ろうと思うと CDocEditAgentを通って CLayoutMgrへたどり着いてしまうような……。CDocEditAgentのくれる情報はすごく役に立つんだけどエディタ上のテキストの変更がすべてここを通過するんだろうか? CLayoutMgr::InsertData_CLayoutMgr()と LayoutMgr::DeleteData_CLayoutMgr()の二カ所で行の変更を通知するようにした。(後で Replaceも入れて三カ所) <追記@2009-10-14>Deleteは使われてなくて、Insertと Replaceだけで済ませてるみたい。だったら Insertもいらないじゃんねえ。</追記>
次の行以降に影響する文字( " など)を入力しても即座には反映されない(最小化して元に戻すと反映されている。アンドゥ、リドゥすると反映されている)。再描画を行う範囲が最適化されているから、次の行以降の色分けが変わっていて再描画が必要なことを知らせる必要があるみたい。どうすれば……?
@2009-09-15
before
bool CEditView::DrawLogicLine( HDC _hdc, //!< [in] 作画対象 DispPos* _pDispPos, //!< [in/out] 描画する箇所、描画元ソース CLayoutInt nLineTo //!< [in] 作画終了するレイアウト行番号
after
bool CEditView::DrawLogicLine( HDC _hdc, //!< [in] 作画対象 DispPos* _pDispPos, //!< [in/out] 描画する箇所、描画元ソース CLayoutInt* pnLineTo //!< [in/out] 作画終了するレイアウト行番号
第3引数を双方向にして CEditView::DrawLogicLine()の呼び出し元にさらなる DrawLogicLine()呼び出しと描画領域の拡大をしてもらうことになった。
……ということをやってもらうために SLayoutWork.bNeedChangeCOMMENTMODEや SLayoutWork.pnExtInsLineNumが用意されてたみたい。どうしたもんかな。
@2009-09-17
やっぱりきたよ分割ビュー問題。表示する行の若い順に再描画すればいいかと思ったけど、通ると思った実行パスが使われていない。別方面で解決。Ctrl+Endでいきなり文書末に飛んだときなんかも最初はエラーだった。
あとは
- CEditView::IsCurrentPositionURL()を対応させる。
- 一行だけ return true; と書いたようなざる実装を埋める。
- ユーザー設定を反映する。(色分けする、しないとか)
- ハードコーディングされてる正規表現キーワードの構築部分をファイルから読み込むようにする。
- 空間効率の改善。(一行一要素を RLEにする。< 何行目までがこう、何行目までがこう、というデータだから run lengthではなかった。相対指定でなく絶対指定だという違いだけで似たようなものだけど)
- 既存の色分けコードを消す。(今は色の設定部分だけを削除した状態)
折り返し、WSHマクロ、矩形選択、置換などはまだ試してない。落ちてから対応する。(分割ビューと Ctrl+Endは乗り越えたけど、折り返しも怖いなあ)
自分が忘れてたので覚え書き。この変更で
正規表現キーワードで複数行にわたる色分けが可能になる。
設定のフォーマットが悩ましい。RxKey[000], RxKey[001],...では表現できないし、ついでにキャプチャグループを利用した、一つのパターン内での色分けを可能にしてもいい。GUIはあきらめてるから SHJSの lang/sh_*.jsを直接読んでやろうか。JSONフォーマット*とかいって……。
正規表現キーワードと組み込みの色分け機能が互いに文字の先食いをできる。
たとえば、正規表現キーワードが組み込み機能より先に引用符を色分け対象にしたとき、次の行から組み込みの色分けが始まることがない > サクラエディタBBS[r7015]。
再帰的な構造に対しては、JavaScriptで動く SHJSに対して鬼車が使えるサクラエディタはもともと後れをとってなかったので、SHJS方式になったところでとくに変化なし。
ときどき落ちる(落ちないはずがない)
レアな機能を呼び出したときが危ない。
@2009-09-18
JavaScriptで使っていた正規表現パターンを鬼車で動かすにあたっては、[文字集合] の中の [ をエスケープしなければならない、のかな? それだけ?
@2009-09-19
- 「CEditView::IsCurrentPositionURL()を対応」済み。
- lang/sh_javascript.jsをまるまるハードコーディングして、色分けのバグ取り。ヘッダファイルを整理して⁑⁂*4
自分に対しても仕様を明確にしたい。もはや色分け結果は、良くも悪くも以前のものと変わらない。
@2009-09-20
- 「ユーザー設定を反映」済み。(正規表現キーワード以外)
@2009-09-30
ファイルIO 面倒くさい。それは経験値がゼロだからだ、ということに気付いた。他人の力を借りよう。JSON_checkerなんて使いやすそうだけど JSONフォーマットには正規表現リテラルもコメントも存在しないのでそのまま使えないのが問題。shjs/lang/sh_*.jsを JSONフォーマットに予め変換しておくのが簡単だけど……(SHJSの言語ファイルをそのまま放り込める、というのがやりたいんだよなあ)。
@2009-10-02
JSON_checkerを修正して使用することにした。修正内容は……
- コメントの埋め込み可。(コメントが埋め込み可能な場所はさらに調整が必要だと思う*5)
- オブジェクトや配列の値に正規表現リテラルが使用可。
- オブジェクトや配列の値にシングルクォーテーション文字列が使用可。
- オブジェクトのプロパティ名部分に文字列だけでなく識別子が使用可。(大部分の Unicode文字、\uXXXXエスケープシークエンスが使用不可な不完全実装です)
> allow_comment_and_regex_literal_and_single_quotation_string_and_identifier_as_a_object_key
遷移表が 30×31(=930エントリ)から 40×35(=1400エントリ)へ 50%増加している。ま、気にすることではないな。
enum modesと enum statesをヘッダへ移動させたら、あとは文字を食わせながら JSON_checkerの modeと stateを参照して情報を取り出すだけ。(解釈の段階でバグが発覚しないことを祈る)
(どうでもいいこと: JSON_checker.cの enum定義部分だけが LFでなく CRLF改行だった)
「SHJSの言語ファイルをそのまま放り込める、というのがやりたい」<< 色指定が互換でないから土台無理だった。
sh_preprocとか sh_functionという色指定をいちいち正規表現キーワードN という色指定にマッピングすればいいのかな。sh_string を SQTにするか WQTにするかは決められないけど。
@2009-10-06
オブジェクトとか配列とかその要素を取得できるようになった。Cに耐えられず、ついでに C++化。ところが、JSON_checkerが最初からガチガチに隙のない C++ライブラリだったら敬遠して手を出さなかったんだよね。他人の C++コードは読めない!
enumの要素(ラベル)が定数に置き換えられて構文エラー。これだからマクロは!!! ヘッダの中だから勝手に #undefもできない。どうすれば……。
#undef IN した。これは windows.hで定義されていたもの。
@2009-10-09
でけた。GUIがないから iniファイルのディレクトリに rkw2/タイプ設定名.rkw2というファイルが存在すれば勝手に読み込んで色分けする。SHJSの言語ファイルをそのまま放り込むのは無理で、JSONっぽく仕立てないといけない。つまり、ifと代入部分(セミコロンも!)を削除して、オブジェクト配列の配列だけにする必要がある。SHJSの言語ファイルは 0.5と 0.6の間でフォーマットが変わってるけど、それはたぶん効率上の理由だけだから、可読性の高い 0.5のフォーマットにだけ対応。色指定は SQT、RK1というのと、強調キーワード1、正規表現キーワード1というのの両方に対応したつもり(日本語での指定は確認していないした)。SHJSの色指定は sh_normal、sh_keyword、sh_string、sh_comment、sh_number、sh_urlだけがサクラエディタの色指定にマッピングできた。課題は正規表現パターンで、文字集合の中のエスケープされていない [ 。これは BREGEXP.DLLと bregonig.dllの橋渡しをするために色分けと関係なく対応しないといけない。
BREGEXP.DLLしかないときだったら色分け能力が飛躍的に向上した、と言えるんだけど bregonig.dllができる子なので、行またぎぐらいしか色分け能力的には変わりがない。行またぎにしたって誤爆恐さで積極的に使いたいものではないし……。
「rkw2/タイプ設定名.rkw2というファイルが……」
C/C++とか PL/SQLというタイプ設定名をどうしよう。全角に変換しようか。……。した。<<< 曖昧な書き方だった。タイプ設定名を全角にしたのではなく、読み込むファイル名を全角のものにした、という意味。
ヘッダの減量中。ヘッダは公共の場、最小が美徳。実装は、何でもインクルード、定義して目的のために邁進する、俺の世界。というイメージ。
@2009-10-10
正規表現キーワードN という色名がわかりにくいのと、rkw2の色指定をポータブルにするために(強調キーワードNや 正規表現キーワードNという色は各人各様に役割が定められていてポータビリティがない)、正規表現キーワード用の色を増やした。
| 短い名前 | EColorIndexType | 長い名前 |
|---|---|---|
| RKB | COLORIDX_REGEX_KEYWORD | 正規表現キーワード(予約語) |
| RKC | COLORIDX_REGEX_TYPE | 正規表現キーワード(型) |
| RKD | COLORIDX_REGEX_VARIABLE | 正規表現キーワード(変数) |
| RKE | COLORIDX_REGEX_CONSTANT | 正規表現キーワード(定数) |
| RKF | COLORIDX_REGEX_ASSIGN | 正規表現キーワード(代入) |
| RKG | COLORIDX_REGEX_OPERATOR | 正規表現キーワード(演算子) |
| RKH | COLORIDX_REGEX_FUNCTION | 正規表現キーワード(関数) |
| RKI | COLORIDX_REGEX_OBJECT | 正規表現キーワード(オブジェクト) |
| RKJ | COLORIDX_REGEX_BLOCK | 正規表現キーワード(構造単位) |
| RKK | COLORIDX_REGEX_RXPATTERN | 正規表現キーワード(正規表現パターン) |
| RKL | COLORIDX_REGEX_DATE | 正規表現キーワード(日付) |
| RKM | COLORIDX_REGEX_TIME | 正規表現キーワード(時刻) |
どなたかの受け売りで代入( = など)と演算子( == など)を分けた。この日記での色分けも以前からそうしている。
タイプ別設定のデフォルトに JavaScriptと Rubyがない!!! PHPも Pythonもないけどね。設定17、設定18、...、設定30という固定長のユーザー設定用プレースホルダもださい。exe一つのポータビリティだけでなく iniファイル一つにもこだわっているのでなければ、iniファイルのディレクトリにサブディレクトリを掘りたい。ディレクトリが空だったり存在しなければ作成してデフォルトを充填する、というポリシーで。
- types/ が存在しない → すべてのタイプ別設定のデフォルトを充填。
- types/タイプ設定名/ が存在するが空 → 基本設定のコピーもしくは、タイプ設定名が既知であれば予めカスタマイズされた設定を充填。
- types/タイプ設定名/タイプ設定名.iniが存在しない → 基本設定のコピーもしくは、(略)
付け加えるなら、コピーされる基本設定とは基本設定のデフォルトではなく、現在の基本設定を優先したい。
カスタマイズされたタイプ設定というのも、すべての項目を持つのではなく、基本設定からの差分、ここだけは譲れないという設定だけを持つようにしたい。強調キーワード、コメント形式、タブ幅、とかそういうのだけ。大部分を基本設定から引き継ぐようにすればカスタマイズの手間が省ける。タイプ別の iniファイルにも、基本設定と異なる設定のみを記録するようにすればいつまでも基本設定を引き継げる。
さらに、強調キーワードをタイプ別設定に移して、ファイルで管理したい。
- types/タイプ設定名/keyword01.kwd
- types/タイプ設定名/keyword02.kwd
- (以下 keyword10.kwdまで)
キーワードの名前、大文字小文字を区別するかどうかのフラグ、と、あとは単語の羅列だけの内容なのでテキストエディタで強調キーワードの管理ができるようになる。sakuraW.iniのスリム化にも役立つ。フォント設定もタイプ別でいいよね。<< やっぱり、プロポーショナルフォントが選べないうちはフォント設定が一つだけでもいいや。
スリム化といえば、MRU関連を別ファイルに保存したい。共通設定、タイプ別設定、フォント設定などと MRUなど履歴情報は更新頻度が違いすぎる。ファイルを分ければ sakuraW.iniの不意の破損を防ぐことにもつながる。設定画面を呼び出して設定を変更しない限り、sakuraW.iniが読み込み専用でも運用できるようになればいい。(ツールバーやステータスバーの表示・非表示設定は微妙だけど sakuraW.ini入りかなあ)
全く関係ないが思い出したこと。既存のファイルを名前を付けて別名で保存したときだったかに、カレントディレクトリがあわせて移動しなくて、外部コマンドの実行で不都合があった。外部コマンドの産物が期待したところ(編集ファイルの位置)に作成されなくて見つけられなかった。
@2009-12-16 カレントディレクトリの件がこの修正で直ったんじゃないかな。>1073
一つだけ棚上げされていた CColor_Foundの移植完了。検索語のハイライトがドキュメントではなくビューに属していたとは知らなかった<追記>あらら不具合扱いだ>画面分割でハイライトが引き継がれない</追記>。棚上げの理由はそれとは関係なくて、検索語の開始位置と終了位置をどこに保存するか、というもの。ともあれ、これで既存の色分けロジックを完全に置き換えることができた。
重さとか、気になるなあ。気がつけば CPUや GPUよりケースやクーラーにお金をかけていた今の PCだけど、腐っても PhenomⅡ720BEだから。Atomの載ったマシンなんて持ってないし。(フルHDとかいうわけでは全くない)DivX動画の再生にも苦労した K6-2でどうだろうか。(ちなみに PhenomⅡは K10)
「ヘッダファイル only (Kazuho@Cybozu Labs: 今更 C++ で JSON パーサ「picojson」を書いたわけ)」というのは考えたことのない*6価値基準だ。そのこころは?
@2009-10-11
移植ミスかと思って ANSI版 1.6.5.0をダウンロードして試したがどうもそうではない。
\w{10} というパターンで検索をする。F3を押す度に次の 10文字に選択範囲が移動する。Ctrl+F3を押してハイライトを解除する。と、検索語が最後に選択されていた 10文字そのものになってしまうのだ。検索オプションも変わってる。もう一度 F3を押しても、Ctrl+F3を押しても元の状態には戻らない。これは正規表現を使わない検索では問題にならないが、パターン検索では困る。Ctrl+F3を押しただけで検索条件が変わっては困る。ちなみに、「カーソル位置の文字列をデフォルトの検索文字列にする」設定とは関係がない(OFFだから)。
CViewCommander.cpp
こうしてみた。
//検索マークの切替え // 2001.12.03 hor クリア を 切替え に変更
void CViewCommander::Command_SEARCH_CLEARMARK( void )
{
this->m_pCommanderView->m_bCurSrchKeyMark = ! this->m_pCommanderView->m_bCurSrchKeyMark;
this->m_pCommanderView->RedrawAll();
return;
}
これで本当に Ctrl+F3が検索語ハイライトの切り替えになったし、パターン検索でも問題がなくなった。2001年から現在までに何かがあったのだろう。
<追記@2010-06-20> 検索条件が選択文字列で置きかわるのは意図された動作だった。つまり「検索マークの切替え(Command_SEARCH_CLEARMARK)」は選択文字列をハイライトしたいときに実行するコマンドだということ。ハイライトが消えるのは選択文字列が空のときに限られた動作。はっきりいってこれは名前が悪い。「クリア を 切替え に変更」したときに主客転倒してしまってる。別のコマンドにせーよ。 </追記>
@2009-10-12
脈絡もなく突然死する。abnormal program terminationと出るから、throwしてる部分が原因。どうしてそこを実行するような状態になるのかがわからない。色分けの反映が、外因による再描画が起こるまで遅れることも、やはり前後の脈絡なく起こる。徐々に壊れていってるのか?
@2009-10-13
昨日の突然死はコードと仕様を整理して適当に書き換えてるうちに出なくなったみたい。だがその過程で新たなミスを仕込んでいた。無効化されたイテレータ。変数名にしてたった 5文字のミス。そのミスをした次の行ではちゃんと意識して避けていたのに……。これのせいで描画範囲の最適化(いまはわかりやすさから常に全面を書き換えている)が進まなかった。
@20009-10-14
仮想関数を持ったベースクラスがあって、継承するからには必ずオーバーライドしないと意味のないメンバ関数を = 0; で純粋仮想にして、そうでない、必ずしもすべての派生クラスにとって必要ではないものをデフォルト付きの仮想関数にしていた。具体的にいうと、デフォルト付きの仮想関数は正規表現キーワードのためだけに用意されたようなもののことだ。
気付かなかった。継承した正規表現キーワードのクラスでオーバーライドに失敗していたことに。関数が constか非constかの違いで失敗していて、別の仮想関数を定義していただけだった。だから C#には overrideキーワードがあるんだよぉ。 .NETが 1.0βのときから*7落とし穴だって事は知ってたさ。気付くまで、ちょっと、丸一日かかっただけで……orz
派生クラスで分かり易さのためにわざわざ virtualって書いてるんだから、そのときに overrideって書かせてくれていたら、コンパイラが「おまえ何をオーバーライドしようとしてるんだ(そんな対象は存在しない)」って教えてくれていたはずだ。
関連。C#のえろい人の話>「Versioning, Virtual, and Override」
degradeの回復はもううんざりだお。次はこれをする。
- 文字集合内のエスケープされておらず、コロンが後ろにない、[ をエスケープ。<<< POSIXブラケットだけじゃなかった。普通の文字集合を文字集合の中に書いて集合の和や積を表現できるんだ(たしかに、おおざっぱに範囲を指定して、一部を取り除きたいときがある。使える機能だ)。エスケープ必須なのには理由があった、ということで無理。
- 一つのパターン内での色分け。
- いまいち機能していない空間効率の改善。
@2009-10-15
パターン内での色分けに対応した。
JavaScriptの正規表現と違ってキャプチャの位置がわかるので、SHJSの仕様に従ってかっこを
/(A)(B)(C)/
というように隣接させる必要がない。入れ子にすることも許される。入れ子にしたら一番内側の色が適用されるようにしたつもり。
- ファイルに改行が一つもなく、末尾の文字が正規表現キーワードの色分け対象だったときに無限ループに陥っていたのを修正した。
@2009-10-17
- 改行部分の検索ハイライトが消えなかったのを修正した。
- パターンのコンパイルエラーを報告するようにした。(結果的に 1つのパターンを 2回コンパイルすることになって無駄なんだけども、色分けに失敗する原因を特定する時間を短縮する方が大事)
@2009-10-11に書いた Ctrl+F3での検索語ハイライトの切り替えについて。ANSI版、UNICODE版に共通するパターン検索の問題として、ハイライト対象かどうかの判断が(おそらく)常に行頭からのマッチングによっているの対して、F3や検索ダイアログの検索開始位置はキャレットのある場所からと、異なっている。\w{10} というパターンを検索するとき、ハイライトは行頭から探して 10文字を対象とするが、検索はキャレットの位置から探した 10文字を選択する。
検索語ハイライトのやり方を変えないといけない。
先に、さらに別の問題の、上検索で行末からの検索が行われていなかったのを修正した。たとえば、"0123456789" という数字10文字の行があって、行末から \d{6} を上検索したときに "012345" が選択されてしまい、"456789" ではない、という問題。
まだ直っていないのはキャレットを "3" と "4" の間に置いて \d{6} を下検索したときに、ハイライトの範囲が(行頭から探した数字6文字) "012345" なのに対して、選択範囲が(キャレットの後ろから探した数字6文字) "456789" となり、一致しない問題。
@2009-10-18
検索語ハイライトのやり方を変えた。パターン検索でも検索開始位置を尊重したハイライトができるようになった。ただし、従来の色分け方法では、CColor_Found::BeginColor()や CEditView::IsSearchString()に与えられる引数が十分でないために、検索開始位置に配慮した判断ができない。というわけで、ここまでの一連の変更に対する上積みの修正となった。(本家へのパッチは UNICODE/ANSI版ともに作成できません)
@2011-03-31 ハイライトが原因で1行3000桁を超える程度のファイルで検索がすんごく遅くなってたので、ハイライトは検索開始位置を考慮しないように戻した。
Luaちゃんのためにブロックコメントを行コメントより優先した。Luaのブロックコメントは --[[ から ]] までで、行コメントが -- から行末まで。rkw2/Lua.rkw2ファイルを用意して正規表現キーワードで色分けすればなんなりと対応できるけど、コメントに関しては専用フォームが用意されてるからそちらでできた方が良い。ひょっとして Luaとは逆のパターン:行コメントを優先しなければいけない言語があるだろうか? その場合、開始文字の長さでソートして長い順に色分け機能を登録しないといけなくなるが。(ところで Luaにはデクリメント演算子がなさそう。コメントより強調キーワード、強調キーワードより正規表現キーワードの方が優先順位が高いので、どちらかで -- を登録するとコメントじゃなくなってしまうだろう。こっそり書いたが、強調キーワードに記号が登録できるように仕様変更したつもりだ。英字とハイフンを混ぜられるわけではないが、&& みたいに全体が記号だけならいけるはず)
>>'\0'も置換できるように >正規表現で \x00 とすれば出来ます。
無理。俺は NUL文字を考慮していない。
> // 前の行のNULL文字(\0)にもマッチさせるために+1 2003.05.16 かろと
というコメントを CSearchAgent::SearchWord() @ CSearchAgent.cpp で見つけたときに嫌な予感はしたけどもう遅い。
設定ファイルのことを考えるときには共有メモリのことを考えないといけないんだ*8。個々のプロセス(=一つの文書)にとって必要なタイプ別設定は一つだけだから共通設定と基本設定だけを共有メモリに置いておいて、他のタイプ別設定は個別に自分のメモリ空間にロードすればいい気がするけど、そうするとタイプ別設定の同期が必要。変更して iniファイルに保存したときにブロードキャストするだけ? タイプ別設定を共有メモリに載せる必要はある? > タイプ別設定数を可変長に
正規表現インクリメンタルサーチなんて機能がある! ひえぇ。
>正規表現による複数行検索対応(簡易版) 正規表現ライブラリに適切なインターフェイスがない限り、ファイルサイズに比例したメモリを消費しないと完全な対応はできない気がする。
- マッチに失敗したのは対象文字列を一行しか与えなかったせいかもしれない。
- マッチに失敗したのは対象文字列を二行しか与えなかったせいかもしれない。
- (以下 EOFまで繰り返し)
既存の APIに適合させるための非効率的なごり押し(に思える)や、バッファに格納する行数を事前に入力させるような設計(行数に制限があることと設定の手間。あと、指定させるなら行数よりバッファサイズでしょう。ユーザーの利便性よりコンピュータの効率よりプログラマの都合を優先させてどうするの?)には尻込みしてしまう。たとえば <table>タグで囲まれた部分を探そうとしたときに、その中身が最大で何行ぐらいあるだろうかとか、考えたくはない。
@2009-10-19
色分けのために行ごとに保存するキャッシュを、シフトする機能は価値があるかも。数MB、35000行程度のファイルで、一行削除する度にスクロールを待たされるのはたまらない。マシンスペックにもよるが、PageDownキーを押し続けるだけでは待たされない。Ctrl+Endやスクロールバーを掴んだときに顕著。しかもこのファイルは色分け対象ではなかった。さらに遅くなるってことだ。
- 幅0の上検索がいつまでもその場足踏みしてないで上へ進むように修正。
- キャレットより前の、幅0の行頭マッチがハイライトできていなかったのを修正。(あんまりやりにくいので CViewCommander::Command_SEARCH_PREV()から gotoを取り除いて、不必要に選択範囲を保存するのをやめた)
- 強調キーワードが語の境界を気にしていなかったのを修正。(少し前にいらない気がして削除した部分がやっぱり必要だった、という)
- $ や \b などの幅0のパターンを検索したときにキャレットが表示されたままになるのを修正。(実はキャレットではなく空の選択範囲だった)
@2009-10-20
昨日の空の選択範囲が消えない対策として空のときは範囲選択をしないことにしたら、今度は下検索が先へ進まない。現在の選択範囲が空かどうかでその場足踏み対策をしていたからだった。やっぱり正攻法の、空の選択範囲の表示をキャレットの移動に伴ってきちんとクリアすること、で解決するのがよさそう。そのへんのコードの流れがよくわからないから手を付けなかったんだけど。
空の選択範囲はキャレットと表示がかぶってしまって、キャレットの点滅が一巡するまでキャレットを見失うデメリットもある。いっそ描画しないのがいいのでは。それがいいとは思わないけど、幅のない矩形選択範囲も現在は描画されていないのだし。
わかってきた。空の選択範囲が消えないのは改行記号を描画していないからだ。
というわけでもなかった。
選択開始時というのは幅0の選択をしている状態である。そのときにCViewSelect::DrawTextArea()を呼ぶことで選択範囲の始点の反転・反転解除の対応がとれたと思う。空の選択範囲のゴミは残らなくなった。そのおかげで幅0の矩形選択範囲を不具合なくある程度の幅で描画できるようになった。
そもそもどの変更でゴミが残るようにしてしまったんだろう?検索と色分けのあたりしかさわってないが。
// 2005/04/02 かろと 0文字マッチだと反転幅が0となり反転されないので、1/3文字幅だけ反転させる // 2005/06/26 zenryaku 選択解除でキャレットの残骸が残る問題を修正 // 2005/09/29 ryoji スクロール時にキャレットのようなゴミが表示される問題を修正
こういうコメントが残っていて、繊細な部分だったという言い訳はできそうだ。
ここ数日は一退一進で進んでいない。
18日から 20日にかけて、exeのサイズが 50KB、diffのサイズが数KB縮んでいる。mergeのやり方を変えたんだが、失敗しているとしか思えない。
@2009-10-20
色分けは別スレッドにするのがいいな。CPU使用率を(3コアだから) 33%にはりつかせて、ユーザーをなすすべもなく待たせて、やってることが色分けだなんてアホすぎる。>@2009-10-19
中心となるデータ構造は一つ。行ごとの色分け開始状態。コンテキストといってもいい。前の行から続くコメントの中なのか、文字列の中なのか、一番外側なのかを表した配列。
色分けスレッドは、未確定の要素のうち一番小さいインデックスを持つもの、の一つ前の行をひたすら色分けして確定に変えていく。
メインスレッドは、行の内容に変更があったからその次の行が未確定に変わったこと。ある行からある行にかけて削除されてしまったからその後ろが軒並み未確定に変わってしまった(賢ければ、対応する要素を取り除いて後ろの要素を前にシフトし、未確定にするのは先頭の一要素だけで済ませてよい)ことを知らせる。色分け結果はタイムアウト付きで受け取り、間に合わなければ色分けなんてせずに文字の表示を優先する。
- 排他処理。
- 未確定要素が存在しないときに色分けスレッドの実行をブロック。
- タイムアウト。
こういう機能はどうやったら手に入るだろう。特に 2番目と 3番目。イベントとかシグナル? C++標準は無し?
そもそも、配列を所有するオブジェクトがこういう機能を提供するのだろうけど、そのオブジェクトはどのスレッドに属しているのか。第3?
違う違う。両方のスレッドがそのオブジェクトのメンバ関数を起動するから排他処理が必要になるんだって。
Unicodeリテラル(>20091007)といい、正常進化だよね。>「C++0xのマルチスレッド機能(2/3):CodeZine」難しい部分はコンパイラとライブラリ作者に任せて、便利な部分を享受するだけの末端アマグラマ拝。
非キーワード文字を含む強調キーワードの色分けを可能にした。空白が入っていてもハイフンが入っていてもバッククオートで始まっていても、キーワードの先頭と末尾が語の境界にありさえすれば色分けする。今は文字を 3種類に分類して語の境界を検出している。即ち、空白類、キーワードに使用できる文字、キーワードに使用できない文字。おおざっぱだけど結構大丈夫。この変更は単独パッチにできる。
正規表現でたとえると、従来の色分けは \b\w+\b を色分けする。昨日までは \b(\w+|[^\w\s]+)\b を色分けしていた。今日のは \b\S.*?\b を色分けする。(\bは \wと [^\w\s]、\wと \s、[^\w\s]と \sの境界)
弱点は、最長一致ではないから共通の接頭辞を持つ複数のキーワードが一緒に登録されていると長い方は絶対に色分けされないこと。A-Bと Aが登録されていたとき、A-Bは絶対に色分け対象にならない。面倒だけどキーワードセットを二つに分けて、長い方を強調キーワード1、短い方を強調キーワード2に割り当てると、番号の若い強調キーワードが優先されるので、長いキーワードも色分けできるようにはなる。
<追記@2010-04-04> やはりというか、掲示板(unicode:1156)で最長一致について言及されてしまった。rev2パッチで最長一致に対応したつもり。 </追記>
@2009-10-22
昨日おかした間違いにトイレで気がついたよ。<どうでもいい
長さが足りなくて登録キーワードと一致しなかったときに、キーワード文字かどうかに関わらず続く語を加えて、改めてキーワードかどうかお伺いをたてるようにしたのが昨日の変更。それで、その結果が結局不一致となったときにカーソルを巻き戻すのを忘れていたせいで、キーワードの見落としが起こっていた(はずだ)。
予想通りだった。修正した。
こういうケース。
# 強調キーワード(2つ) 本日は、晴天なり 晴天じゃないよ # テキスト(1行) 本日は、晴天じゃないよ。
晴天じゃないよ、の部分が見落とされていた。
@2009-10-24
ハイライトの描画が古い情報に基づいていたのを修正した。なにが大丈夫だから省略、だ。> 過去の自分
@2009-10-27
@2009-10-20での矩形選択始点にゴミが残る問題の修正の結果、普通の選択でゴミが残るようになっていた。それならこれでどうだ。
@2009-10-30
組み込みの「半角数値」の色分けが単語の境界を認識せず、数字とみれば見境なく色分けするようにしてしまっていたのを修正した。
検索語ハイライトがおかしい。CEditView::IsSearchString()の仕様が正規表現検索とそうでない場合で異なっていたことに気付かず、正規表現を使用しないときは、一行につき一つしかハイライトできていなかった。正規表現を使用した検索でも、ハイライトすべき語が周期的にスキップされてしまう。
修正した。
@2009-10-10で書いた、「どなたかの受け売りで代入( = など)と演算子( == など)を分けた。この日記での色分けも以前からそうしている。」の元ネタを再発見した。これを以前読んでいたのだ。
With syntax highlighting it would be possible to mark "=" and "==" in different colours. Yay! A good reason for implementing syntax highlighting! But — and at this point it probably won't surprise you — every colour scheme I've come across uses the same colour to highlight both "=" and "==".
@2009-10-31
ちょっと考え直して正規表現キーワードの優先順位を、強調キーワードの下に下げた。正規表現キーワードのフォーマットは難しく、強調キーワードのは簡単なので。「何でこのキーワード、登録して設定したのに色分けされへんの?ムキー!」ってならないように。(容易に想像できる通り、今日の自分がそうだったからです)
@2009-11-01
正規表現キーワードの色設定のチェック状態が反映されていなかったのを修正した。以前の正規表現キーワードと違い、一つのパターンが一つの色設定にひもつけられるわけではないので、チェック状態は機能の ON/OFFを意味しない。チェックが外れていた場合は「テキスト」色に色分けすることにした。
@2009-11-02 検索語を複数の色でハイライトできるようにした。
>複数検索結果のハイライト表示 Request/197 - SakuraEditorWiki
最初に一言。検索履歴を利用して複数の色分け対象を探すのは、使いやすいインターフェイスがみつからないだろう。
検索機能は大枠で三種類ある。パターン検索、単語検索、それとただの検索。今回変更したのは単語検索。単語検索では検索語が一単語でない場合、たとえば空白やピリオドやハイフンを含んでいた場合、これまでは絶対にマッチが見つからなかった(と思う)。だから検索語を単語に区切って各々を違う色に塗り分けても悪影響はないだろう、むしろ望むところ?という判断。
ツールバーの検索ボックスを単語検索専用にするか別に用意すれば、すごく使いやすくなる。
@2009-11-04
検索文字列の色設定のチェック状態を反映するように修正。
@2009-11-15
Very Sleepyを試してみた。Ctrl+Endを押すと wcschr()がものすごい勢いで呼ばれているらしい。それを呼ぶのは文字変換系などを除くと WCODE::IsZenkakuKigou()がくさい。さらにそれを呼ぶのは CWordParse::WhatKindOfChar()。これは単語の境界判定で使われている。
改行文字36223個、折り返し64935行のファイルの先頭で Ctrl+Endを押すと、以下のような呼び出し履歴を伴って CWordParse::WhatKindOfChar()が○百万回呼ばれていた。笑うしかない。と書こうとしたが終わらない。回数は数えられなかった。どうやら Visual Studioが張り付いた状態では限界が低くなるらしい。このファイルの内容を、サイズが 100MBを超えるくらいまでコピペを繰り返したファイルでも無限ループ状態になるのを確認している。(何時間も終わらなければ無限でしょう)
sakuraW.exe!CWordParse::WhatKindOfChar(const wchar_t * pData=0x027dd078, int pDataLen=134) 行 120 C++
sakuraW.exe!CWordParse::WhereCurrentWord_2(const wchar_t * pLine=0x027dd078, int nLineLen=134, int nIdx=125, int * pnIdxFrom=0x0017f76c, int * pnIdxTo=0x0017f768, CNativeW * pcmcmWord=0x00000000, CNativeW * pcmcmWordLeft=0x00000000) 行 49 + 0x10 バイト C++
sakuraW.exe!CEditView::IsSearchString(const CStringRef & cStr={...}, int nPos=125, int * pnSearchStart=0x026338f4, int * pnSearchEnd=0x026338f8) 行 307 + 0x24 バイト C++
sakuraW.exe!CColorML_Found::IsStartOfKeyword(const CEditDoc * const pDoc=0x02740048, const int nLineNumber=40057076, const int nPosWithinLine=125, EColorIndexType * const outColor=0x0017f80c, void * * userData=0x04af1e94) 行 56 C++
sakuraW.exe!ColorMLStrategy::HighlightEngine::DoHighlightLine(const std::vector<CColorML_Base * const,std::allocator<CColorML_Base * const> > & strategies=[2](0x026338a8,0x026338e8 {pView=0x0263a458 lineNum=1582 begin=-1 ...}), const CEditDoc * const pDoc=0x02740048, const int nLineNumber=1582, const ColorMLStrategy::HighlightEngine::StartingStrategy & startingStrategy={...}, ColorMLStrategy::Result * const outResult=0x00000000) 行 113 + 0x27 バイト C++
sakuraW.exe!ColorMLStrategy::HighlightEngine::HighlightLine(const std::vector<CColorML_Base * const,std::allocator<CColorML_Base * const> > & strategies=[2](0x026338a8,0x026338e8 {pView=0x0263a458 lineNum=1582 begin=-1 ...}), const CEditDoc * const pDoc=0x02740048, const int nLineNumber=36202, ColorMLStrategy::Result * const outResult=0x0017f9bc) 行 69 C++
sakuraW.exe!ColorMLStrategy::HighlightLine(const CEditDoc * const pDoc=0x02740048, const int nLineNumber=36202, ColorMLStrategy::Result * const outResult=0x0017f9bc) 行 200 C++
sakuraW.exe!CEditView::DrawLogicLine(HDC__ * _hdc=0x00008d6a, DispPos * _pDispPos=0x00000000, int * pnLineTo=0x0017fbe4) 行 546 C++
sakuraW.exe!CEditView::OnPaint(HDC__ * _hdc=0x01011734, tagPAINTSTRUCT * pPs=0x0017fc38, int bDrawFromComptibleBmp=18) 行 377 C++
sakuraW.exe!CEditView::DispatchEvent(HWND__ * hwnd=0x00080684, unsigned int uMsg=0, unsigned int wParam=0, long lParam=0) 行 693 C++
sakuraW.exe!EditViewWndProc(HWND__ * hwnd=0x00080684, unsigned int uMsg=15, unsigned int wParam=0, long lParam=0) 行 103 C++
- 検索語ハイライトが無駄に表示領域外の色分けに励んでいたのをやめさせた。
- そうすると次に、単独の関数として一番時間を食っているのが _wctomb_s_l()で、これは URLの色分け判定で使われる IsURL(@parse/CWordParse.cpp)から呼ばれている。IsMailAddress(@parse/CWordParse.cpp)も IsUrl()から呼ばれ、やはりかなりの時間を消費している。単語の境界判定を上位で行って IsURL()の呼び出し回数を減らした。
- CDocLineMgrの実装がリストなので「ドキュメントの○行目」を取得するコストが高い。個々の色分けユニットに、パラメータを通して CDocLineを渡すことにした。
CLayoutMgrの実装もリスト。ランダムアクセスの遅さ(=CLayoutMgr.SearchLineByLayoutY()の遅さ)がスクロールバーをドラッグしたときのカクカクした反応に現れている。メモリは潤沢にあるものとして、CPU速度と相談していくつまでならリストをたどっても満足なレスポンスを返せるかを決める。たとえばそれが 10000なら 10000行ごとにショートカット用のポインタを持っておけばいい。
インデックスのはりすぎは更新のコストがいやんなことになる@2013-07-26。10000行ごと、って決めてしまわずにルーズに管理して更新頻度を減らそうとすると、直近のショートカットを見つけるのが割り算一発からバイナリサーチになるなあ。
ポインタ二個分のオーバーヘッドをもった doubly-linked listなんかより、つなぎ合わせた vectorでいいじゃない。(そうするとこんどはリターンキーのレスポンスが気になるわけだけど)
@2009-12-21 われながら遠回りしてるよなあ
- 「ギャップバッファは GreenPad で知ったのだが、私は説明しないんで、別のページで勉強してください(Alpha のグダグダ日記)」
- 17:35 04/05/29 ギャップバッファ(w.l.o.g.)
Alphaは、GreenPadとならんで、ソースを参考にしたいエディタのにおいがする(まだチラ見もしてないけど)。Alphaのリポジトリの最終更新は 43時間前と、まだ生きてるのも嬉しい。
GreenPadはねえ、どこに機能があったのか?と見返してしまうほどにひとつひとつのファイルはすかすかで整然としてる。だからといってべらぼうにファイル数が多いわけでもない。テキストエディタなんてその程度の規模のアプリなんだと思わせてくれるのだけど、自分で書いたら管理不能なスパゲッティになるのが見えていて、知識とテクニックと設計能力の差を思い知るよね。
Alpha-0.7.5.16α-fix10で .rbファイルを開く。#のみの行で #がコメント色にならないとか、なんで設定変更できないの?とか枝葉末節はおいておいて、機能性もレスポンスの良さも申し分ない。文字の表示がきれい。軽やか。紙切れのようだ。100MB超のファイルを開くと CPU使用率 33%(1コアフルロード)でフリーズして応答が戻らないけど、そんなん耐久テストのみの世界だし。正規表現で複数行検索できるのが何よりすばらしい。それはやはり、Boost.Regexだからできたのかなあ >「2006-12-22 Boost.Regex で改行をまたぐ検索を その 8 (Alpha の अनुपयोगी な日記)」。入力はイテレータかストリームで与えたいよねえ。おっと、\w{10} の前検索が戻っていかない。(毛色の違う先端バージョン 0.7.9x系列の)Alpha-0.7.93.5αや、\w{10}\n というパターンだとバックしていくのだが。Alpha-0.7.93.5αは選択範囲の D&Dで落ちた。本当にアルファ版なんだ。
ソースの前に、日記(Alpha の अनुपयोगी な日記)も読み応えがあるなあ。グリフって何?レベルの人間には Unicode関連の話が理解できない。内部文字集合が Unicodeってだけでなく、すごく真面目に Localization(でいいのかな?)に取り組んでるのが伝わってくる。それとメモ帳。エディタを名乗るからにはこけおどしの機能をてんこ盛りにする前に文字の表示で、(世界中で販売されている Windowsに添付されている)メモ帳品質を超えていてほしいものだ。
@2009-12-23 l10n v.s. m17n
昨日は「Localization(でいいのかな?)」と書いたけど、2006年あたりの日記(Alpha の باطل な日記)を見てると Multilingualizationまで踏み込んでいる気がする。「気がする」のは用語の適用範囲がいまいちわかっていないから。Unicodeがモノリンガルであるということの意味がそもそもわからん。
@2009-12-24 パターン検索での上検索と下検索の対称性
破ってしまいました。
@2009-10-17に書いた「上検索で行末からの検索が行われていなかったのを修正した。たとえば、"0123456789" という数字10文字の行があって、行末から \d{6} を上検索したときに "012345" が選択されてしまい、"456789" ではない、という問題。」に伴う副作用だと思う。気付いたきっかけはこの日記。
サクラは '00000'00000 ←→ 00000'00000' だから、挙動に納得は出来る。 EmEditorは一見、真魚と同じに見えるが、 aaa1aaa1aaa1に対して、.+1で検索すれば、 順方向では開始位置から最後までがヒットするのに逆方向ではa1だけがヒットする。 これも全く納得できない理解不能な動作だ。
上検索で a1 ではなく aaa1aaa1aaa1 にマッチするようにはできる。副作用だけを取り除けるはずだ。正規表現マッチの基本は greedyだから、上検索で a1 にしかマッチしないのは自分も納得できない。
真魚の最新版(2.2.3.5)で aaa1aaa1aaa1 に対して .+1 を下検索すると全体がマッチするのに、上検索すると a1 に三回マッチするっていうのは全く納得できない理解不能な動作だ。どこかで心変わりしたのですか。
気にせず greedyな上検索にしてみたけど、中途半端な結果になった。
- aaa1aaa1aaa1 の末尾から .+1 を上検索すると aaa1aaa1aaa1 がマッチする。(期待通り)
- aaa1aaa1aaa1 の末尾の 1の手前から .+1 を上検索するとマッチなし。(先頭から aaa1aaa1にマッチしてほしい)
- aaa1aaa1aaa1 の末尾から .+?1 を上検索すると 1aaa1 にマッチする。(右から左へのマッチングを正当に行った場合は a1にマッチするのが正しいかもしれない。下検索の対称という観点では aaa1にマッチするのもありかもしれない。でもどちらでもない)
本家のサクラエディタは 3番目に対応している。上検索の実装が(行頭から始まる)下検索の巻き戻しだからだ。ところがそれではキャレット位置からの上検索ができないからと変更したのだった。その結果、下検索を繰り返してキャレットが進んでいくたびにキャレットより前のハイライト範囲(=上検索でのマッチ範囲)がうぞうぞと変化するようになったと自分で報告していたのだから、最初から上検索と下検索の対称性などのぞむべくもなかったのだ。
対称性は(自分の望んだ結果なのだから)捨てられるとしても、2番目と 3番目にはよりよいマッチが存在しているのに対応することができない。ひょっとしたら 2番目は鬼車の APIを直接使って「検索対象文字列の終端アドレス」とは違う「検索対象文字列の検索終了位置アドレス」を渡すことで、$が誤ってマッチする心配なしに、aaa1aaa1にマッチさせられるかもしれない。でも 3番目は .NET Frameworkの「RegexOptions 列挙体 (System.Text.RegularExpressions)」に用意されている RightToLeftオプションのようなものが予め用意されていなければ自作するしかない、ような気がしたが、\1 のような参照とキャプチャの前後を入れ替えられるわけもなく、.+?1 の上検索が a1にマッチするのを期待するのは無茶ってものだ。
行末やキャレット位置からの(中途半端におわってしまう)上検索より、(行頭からの)下検索の巻き戻しのように(大部分で)対称的に動作する上検索が、わかりやすさも使い勝手も勝ってるようだ。(すでに加えた変更を巻き戻すかどうか迷う)
CR、LF、CRLF、←、↓、↵
同じく、真魚の作者の日記から
正しくは、 CR:← LF:↓ CRLF:←曲がって↓ LFCR:↓で一行、←で一行 こんな表記になる。 あきらかに間違っているのはサクラエディタで、CRとLFの矢印が逆だ。 いや、Windowsの間違いにわざと乗ってやってると言うべきなのか。 CR:↓(逆) LF:←(逆) CRLF:↓曲がって←(逆+逆) LFCR:←曲がって↓(一行にまとめてはいけない)
今は ANSI版、Unicode版ともに CRと LFの逆転は解消され、CRは←で、LFは↓で描画されている。CRLFはそのままだがこれは、LF(↓)と CR(←)の組み合わせなのではなく、リターン記号(cf.リターンキー(ja.wikipedia.org))だったんだよ、Windowsにおいて改行と CRLFとリターンキーは切っても切れない関係なんだから、という強弁で乗り切ろう。
@2010-01-23
URLの色分けがいつからかできてないや。
2009-11-16からだ。アルファベットかをどうか調べる関数に、文字(wchar_t)のかわりにその文字の文字列中でのインデックス(int)を渡していた。
intと wchar_t(オプションにより組み込み型扱いになっている)は全くの別物だと思うんだけどなあ。
相変わらずマージってやつは泥臭い作業で自信が持てない。同じコードブロックが複数回連続してるような場所がみつかってもまったく驚かないよ。
@2010-04-14 バグ修正
行をまたぐ色分けに問題があって、たとえば一画面に収まらない長大な複数行文字列があったとして、何度も上下にスクロールしたり改行を入力したりするだけで色分けが変わってしまっていた。
@2010-04-23 ちょっとしたバグ
括弧類を色分け対象にしていて、「対括弧の強調」も有効になってる場合、キャレットが括弧から離れるときに、閉じ括弧の表示が閉じ括弧の次の文字と同じになってしまう。
ちょっとしたバグ、解決。
このブランチ単体でも、純粋な公式 trunk2でも再現しないからその差分を見ていたら見つけた。
http://sakura-editor.svn.sourceforge.net/viewvc/sakura-editor?view=rev&revision=1723
Index: sakura_core/view/CEditView_Paint_Bracket.cpp
===================================================================
--- sakura_core/view/CEditView_Paint_Bracket.cpp (.../shjs_style_regex_keyword) (リビジョン 45197)
+++ sakura_core/view/CEditView_Paint_Bracket.cpp (.../build_my_sakura) (リビジョン 45197)
@@ -138,7 +138,7 @@
if( IsBracket( pLine, OutputX, CLogicInt(1) ) ){
// 03/10/24 ai 折り返し行のColorIndexが正しく取得できない問題に対応
// 2009.02.07 ryoji GetColorIndex に渡すインデックスの仕様変更(元はこっちの仕様だった模様)
- nColorIndex = GetColorIndex( pcLayout, OutputX );
+ nColorIndex = GetColorIndex( pcLayout, OutputX + 1 );
}
else{
SetBracketPairPos( false );
+1したら次の文字の色になるのも当然。GetColorIndex()の中身がブランチの方で別物になってるから、公式で行われた上のような呼び出し部分の変更はマージしてはいけなかった。
ここらで続く。
sakuraW+rkw2.zip (645KiB, 2011-05-25, 2.0.2.0(r1913)ベース)
shjs_style_regex_keyword(trunk2@1711).patch (352KiB, 2010-04-14)
svn co https://sakura-editor.svn.sourceforge.net/svnroot/sakura-editor/sakura/trunk2/@1711
- 突然エラー終了しても泣かない。
- 突然応答がなくなって強制終了するしかなくなっても泣かない。
- 数千文字ある行に対して . をパターン検索するなどして数千回のマッチングが行われそうな場合、応答がなくなる。(待っても返ってくるかは不明)
- bregonig.dll(Unicode版)が exeの隣にないと、当然機能しない。
- タイプ設定名と rkw2ファイルの名前を一致させないと機能は ONにならない。
- タイプ設定名にファイル名に使えない文字が使われている場合、その文字を対応する全角文字に置き換えた名前のファイルを作成すればいい。
- あ、この文字( \ )が円マークに見えてる人も、全角の \ に置き換えないとファイルを見つけられないので。
- たまたまこの日(2009-08-08)の日記に SHJSのバックトラックのことが書いてあるが、その機能はない。\(改行)で JavaScriptの文字列が次行に継続することならば確認できる。
- 無限ループ対策をしていないので、ある Stateから同じ Stateへ、一文字も消費しないで遷移するルートが存在すると抜けられない。先読みを使って遷移先を振り分けるときは注意。
気ままな変更がちらほら。
- 設定のデフォルトを、常駐OFFに変更。ルーラー、カーソル行アンダーライン、改行文字、タブ、EOF表示をOFFに変更。正規表現キーワードの色分けを ONに変更。
- 常駐はしないのが普通。(俺は、ブラウザの次によく使うからスタートアップに入れて常駐させてるけども)
- 改行もタブも空白としてありふれた文字だから表示するとうるさい。視認する必要も一般人にはあまりない。
- いきなりの自己否定。一般人はサクラエディタ、っていうかエディタ自体使わないんだよね(伝聞)。画像はフォトショ、テキストはワード、みたいな。jpgを表示するだけならフォトショップよりブラウザ、ブラウザより IrfanView(たとえが古いな)が軽いだろうけど、そんなことは気にしない、アイコンをダブルクリックするだけ、というイメージ。
- 今や実在も疑わしい EOFを、わざわざ表示する必要はなかろう。
- ルーラー? カーソル行アンダーライン? 存在理由がわからない。(ルーラーにこだわる人がいるのは知っているが)
- 正規表現キーワードは表示までにユーザーの設定が別途必要なので、色設定は予め ONの方がわかりやすい。
- 色設定を二つのファイル( view/colors/EColorIndexType.h, .cpp )に集約。
- パターン検索でも、検索開始位置を尊重した上検索とハイライトを行う。
- \w{10} のようなパターンで F3(Shift+F3)を押していけば、キャレットが通り過ぎたあとのハイライト範囲がうぞうぞ変化するのがわかるかと。
- 幅0の矩形選択範囲が見える。
- 空白やハイフンを含んでいたり、バッククオートで始まっている強調キーワードを色分けできる。(最長一致)
- 検索語を複数の色でハイライトできる。
- 文脈依存変換パッチrev3.3(SourceForge.net: Sakura Editor: Detail: 2972711 - IME前後フィードバック機能)
- 拡張子の存在しないファイルはファイル名を拡張子とみなして適用するファイルタイプを決定する。(guess_filetype_of_extlessfile.patch 拡張子リストを「mak makefile」としておけば MAKEFILEにもファイルタイプを適用できる。副作用で a.makefileや MAKというファイルにも適用される)
SHJS-0.5/lang/sh_*.jsから rkw2フォーマットへの変換。
- ifや代入部分(セミコロンも!)を削除して、オブジェクト配列の配列だけにする。
- パターン中の文字集合の中の [ をすべてエスケープする。
- \xXXというパターンを Unicode形式にするか削除する。(JavaScriptではこのへんをうまく扱ってくれる*9のだけど鬼車は違った)
色分けされないときのチェックリスト
- ファイルの配置は正しいか?
- sakuraW.iniファイルのあるフォルダに rkw2フォルダを置かないといけない。sakuraW.exeや sakuraW.exe.iniのあるフォルダではない。
- 正規表現キーワードの色指定をデフォルトから変更したか?
- 色分けの結果が「テキスト」と同じでは区別できない。
Javaだった java.util.regex.Matcherクラスの requireEnd()や hitEnd()がそう。他にも AnchoringBoundsや TransparentBoundsが用意されているなど至れり尽くせり。こういう生真面目さが Javaの良さであり、冗長さや遅さを許す一因だったのかも、と今は思う。
* WikiPedia(ja)を見たら JSONで表現できるデータタイプに正規表現がない!ポータブルじゃないからか? ほかにも有効でないエスケープシークエンス(\Gとか \qが Gや q自身を表す)とか \(改行)というエスケープシークエンスが無効。シングルクォーテーション文字列もない。JSON_checkerによるとマイナスの後に空白を入れるのも、プラスを明示的に付けるのも許されない。窮屈だけど、\x[ や \x] というエスケープシークエンスの存在が正規表現パターンの簡易的な解釈を一段面倒なものにしていると感じていた(>[[20090922p01]])ところなので、悪くはない。
⁑ 内部で使用するだけの型の完全な情報を実装(cppファイル)に閉じ込めようと思ったら、ヘッダの中のクラスはその見せる必要のない型をポインタで保持するしかないのか? privateメンバーの詳細(サイズとか)なんてどうでもいいから隠したいのだが、ポインタで保持することにするとコンストラクタで newすることになるのが嬉しくない、というジレンマ。デストラクタが呼べないからと std::auto_ptrにすることもできず生ポインタをメンバにしないといけないのも困りもの(明らかに「所有」しているのに、生ポインタではそれが伝わらない)。
⁂ @2009-10-24 デストラクタが呼べないのは、auto_ptrをメンバに持つクラスのデストラクタがコンパイラの生成するデフォルトのデストラクタだったから。ヘッダでデストラクタを宣言して実装で空のデストラクタを書けば解決。ビョルン・カールソン『Boost』(2008, ピアソン・エデュケーション)に書いてあった。「implクラス(構造体)の寿命管理を scoped_ptrに任せ、デストラクタから pimpl_(implオブジェクト)の delete文を削除する(scoped_ptrを使えば deleteは不要となるのです)だけで作業は完了です。ただ、デストラクタそのものは定義しておく必要があるということを覚えておいてください。その理由は、コンパイラが暗黙のデストラクタを生成する時点では型 implが不完全であり、pimpl_のデストラクタを呼び出せないためです。implの格納に auto_ptrを用いた場合、こういったエラーを含むコードがコンパイルされてしまうことになりますが、scoped_ptrを用いることでエラーを検出できるのです。」auto_ptrの場合に起こる「こういったエラー」が何なのかわかっていないが……。
*4 @2010-01-29 『More Exceptional C++』を読み返していたら、これにも原因の説明と対処法が載っていた。読んでいたはずだけど、一度自分で穴にはまらないと気付きにくい問題だろうね。
*5 今のままでは正規表現のフラグとフラグの間にコメントが埋め込めそう。コメントは空白文字だとして、returnStateに戻る代わりに state_transition_table[returnState][C_SPACE]に戻れば良さげ。
*6 現在までに書いた C++コードの 99%以上がここ 1、2か月のものだという、にわかではあるけども。
*7 というか、そのときの C#しか知らない。
*8 共有メモリにオブジェクトを置いて初期化されていないゴミメモリにアクセスしたり、だったら placement newの出番だ、とコンストラクタを呼んだんだけど、(想像では)似非共有オブジェクトが私的に確保したメモリは共有されてなくてやっぱりエラーになった、少し前の記憶がよみがえる。
@2013-07-26 Scintillaでの行管理の工夫。「[[Scintillaのデータ設計 - maneman8000の日記|http://d.hatena.ne.jp/maneman8000/20110206/1297006996]]」インデックスの更新が必要なエリアはある点から始まり必ず末尾で終わる。ある点をひとつ記憶しておくことで更新範囲をある点とある点の差分にすることができる。
*9 文字列の内部表現が Unicodeなのに \xXX という ASCIIコード指定を、意味が変わらないように解釈してくれる。
2009年06月22日 (月) 関数の外の const intと static const intは同じ?
♪ [SakuraEditor] メニューバー右端のメッセージ表示改善
縦書き編集機能とか実装できるほどのスキルがあればいいんだけどねえ。
2chに化けるという書き込みがあって試してみたら表示が消しゴムで消すように欠ける。描画漏れだと思ったんだけど、後で調べたらそもそもメッセージを保存していなくて再描画するつもりがない。だったら改善す"べき"とまでは思えないんだよね。(タイポのようなものの指摘はできても、自分の考えを押しつけることまではできないし)
ステータスバーが非表示のときにメニューバー右端に表示されるメッセージの、再描画に対応。一時メッセージだとしてもメッセージが半欠けの状態で表示されてたらバグととられても仕方ないから。> fix_menubarmessage.diff
この修正中にこんな処理が行われていたことを知ったのだけど……
// 編集ウィンドウ切替中(タブまとめ時)はタイトルバーのアクティブ/非アクティブ状態をできるだけ変更しないように(1) // 2007.04.03 ryoji // 前面にいるのが編集ウィンドウならアクティブ状態を保持する
タブ切り替え時に二つのサクラエディタウィンドウが重なる瞬間があって、Aero Glass効果が有効だとこの時にタイトルバーの透明度が下がる(色が濃くなる)。結果、対策もむなしくちらついて見える。これに対応した対処法はあるかな?
ツッコミを受けての追記。
行・列番号の表示よりも右の部分にゴミが表示されます。
Vistaしかないので制御文字が半角空白に置き換えられたときに区別できるように、メッセージの余白を「 」ではなく「*」で埋めて表示してみたけれど表示は変わらない。この、メッセージの余白を埋める文字がすべてゴミになっているのだろうか。2chの
ステータスバーを消すとメニューバーの右端が化けちゃうんだけどどうすれば
というのを読んで俺は表示が欠けることを指して化けると言っているのかと思ったんだけど(繰り返すけど Vistaだとゴミは見えないので)、この書き込み主は Windows2000でも使っていて半角の「・」のことを指して化けると言っている可能性もあるかも(俺がバグを仕込んだのではないと思いたい)。
タブ切り替え時のちらつき防止はノーアイディア(あったら書いてる)。せっかく見映えの細かいところにまで気が配られているのに自分の環境で働いていないってのは悲しいから、Aero Glassにも対応できたらいいよね。
_tcsncpyが、コピー元が短いときにコピー先の末尾に埋める '\0' が「・」に変換されるんだ。Cの林立する文字列操作関数が大嫌いでいつも(といって片手で数えられるほど)は std::stringに逃げるんだよね。元々のソースはちゃんとやってたのに、俺がテケトーなことをしたわけだ。確保した領域の一つ先に書き込むとか言い訳できないミスもしてるし……。
今度は右端に埋め文字(「 」の代わりの「*」)が見えた > fix_menubarmessage(rev2).diff
さらなるチョンボ(泥沼の様相を呈してきました)。さっきの改訂でメッセージが空になることがなくなったので、表示したメッセージのクリアが行われないはずだ。
もう最後にしたい > fix_menubarmessage(rev3).diff
2009年06月03日 (水) [SakuraEditor] (要望) 新しく開いたファイルを現在のタブのすぐ右側に追加する機能。
最終更新: 2009-08-26T17:01+0900
♪ [SakuraEditor] 新しく開いたファイルを現在のタブのすぐ右側に追加する機能。(2009-06-04)
要望を書いて次の日になんとかするセルフサービス > open_tab_right.diff
便利なメソッド( CTabWnd::ReorderTab )が既に用意されていたので楽でした。
結果はわりと希望通りの動作。
- エディタに対して Ctrl+Oで、すぐ右のタブにファイルを開く。
- エディタに対して Ctrl+Nで、すぐ右のタブに新しいファイルを作成。
- エディタに対して Ctrl+Gで、すぐ右のタブに GREP結果。
- エディタに対してファイルドロップで、すぐ右のタブにファイルを開く。
- トレイアイコンから新規作成では、右端にタブを追加。
- トレイアイコンから最近使ったファイルでは、右端にタブを追加。
バックグラウンドでタブを開く機能はないから、連続してファイルを開いたときに新しいタブが右に延びるか左に延びるかということは考えていない。(01234...となるか 0...4321となるか。特別に考慮しなければ後者になる)
タブを閉じたときに次にアクティブになるタブは、多分直前にアクティブだったタブ。理想とする Firefox + TabsOpenRelativeだと、基本的に閉じたタブの右側のタブがアクティブになるものの、ある条件で元のタブ(閉じたタブの左側のタブ)がアクティブになる。タブを閉じたとき次にアクティブになるタブにこだわりはないので変更していない。

知らなかったけど svk diffの出力をリダイレクトしたファイルが CR/CRLF混合。diff自身のメッセージが CR区切りになってるからみたい。いったいどこの diffを使ってるんだ。
よくみると CRの部分は改行がダブってる。CRCRLFが CR+CRLFと解釈されてるみたい。CRLFの LFに誤って CRを補ってしまったのかも。(だれが?)
あとは、常に「前回開いていたファイルを復元する」機能が欲しいところ。タブの順序、カーソル位置、スクロール位置、検索文字列、アンドゥ記録(は無理か)などなどの復元も込みで。
2009年05月26日 (火) レンタルサーバーに /usr/local/bin/ruby18 というリンクがある。/usr/local/bin/rubyが 1.9になるのはいつになるだろう。
最終更新: 2009-09-02T23:17+0900
♪ [SakuraEditor] 正規表現キーワードの色分けがおかしい。
- クォーテーション文字列の色分けを正規表現キーワードで行っている。
- 正規表現キーワードの色指定を「ダブル(シングル)クォーテーション」にしている。
- 組み込みの色分けを無効にするために、クォーテーション文字列の色指定のチェックを外している。
おかしい。チェックが外れていると正規表現キーワードによる色分けも無効になる。
まずはこちら
242 //色指定でチェックが入ってなければ検索しなくてもよい …… 249 //正規表現では色指定のチェックを見る。 …… 255 //正規表現以外では、色指定チェックは見ない。 256 //例えば、半角数値は正規表現を使い、基本機能を使わないという指定もあり得るため
このコメントを読めばまさしく現在の状況が考慮されていることがわかる。
- 正規表現キーワードに正規表現キーワード1などという色指定がされている場合、チェックがついていなければ色分けをするためにマッチを検索する必要がない。
- 正規表現キーワードに半角数値などの色指定がなされている場合、チェックの有無は基本機能による色分けの使用・不使用を表すのみで、正規表現キーワードの有効無効には影響を与えない。
仕様がねじれている気もするが、正規表現キーワードに「正規表現キーワード3」という色指定より「ダブルクォーテーション文字列」という色指定をしたいのだよね。基本機能を無効にして正規表現キーワードだけを使いたい場合もあるし(今回のように)、基本機能を使いつつ正規表現キーワードを使って、標準的でない文字列形式(Rubyの %!string! など)を補いたい場合もあり、そのときに複数の色指定を同じに保つより「ダブルクォーテーション文字列」という一つの色指定で色を管理したい、という要求がある。この両方を満たすのが以前の仕様。
待ってても直らないかもしれないので*他人の修正を待てないので調べた。
17 if( TypeDataPtr->m_bUseRegexKeyword
18 && pcView->m_cRegexKeyword->RegexIsKeyword( cStr, nPos, &nMatchLen, &nMatchColor )
19 ){
20 this->m_nCOMMENTEND = nPos + nMatchLen; /* �L�[���[�h������̏I�[��Z�b�g���� */
21 this->m_nCOMMENTMODE = ToColorIndexType_RegularExpression(nMatchColor);
22 return true;
23 }
24 return false;
21行目の ToColorIndexType_RegularExpression(nMatchColor); とは実質的に
(EColorIndexType)(COLORIDX_REGEX_FIRST + nMatchColor);
こういうことだ。nMatchColorとはそのまま色指定なのだから COLORIDX_REGEX_FIRSTという下駄をはかせる必要はなくて
(EColorIndexType)nMatchColor;
これで十分のはずだ。正規表現キーワードだからって正規表現キーワードNという配色とは限らないのだよ。
[訂正] これはわざとだった。どんな色指定をされていても正規表現キーワードを他と識別するために行っている。同じファイル(sakura_core\view\colors\CColorStrategy.h)内に下駄を外す処理もある。
デバッガで nMatchColorの値を見てみたら 29であって、これはシングルクォーテーション文字列に対応した色インデックスだから期待通り。でも色分けはなされない。
なんでだろー。
223 /* 現在の色を指定 */
224 void CEditView::SetCurrentColor( CGraphics& gr, EColorIndexType eColorIndex )
225 {
226 //インデックス決定
227 int nColorIdx = ToColorInfoArrIndex(eColorIndex);
228
229 //実際に色を設定
230 if( -1 != nColorIdx ){
231 const ColorInfo& info = m_pcEditDoc->m_cDocType.GetDocumentAttribute().m_ColorInfoArr[nColorIdx];
232 if( info.m_bDisp ){
233 gr.SetForegroundColor(info.m_colTEXT);
234 gr.SetBackgroundColor(info.m_colBACK);
235 gr.SetMyFont(
236 GetFontset().ChooseFontHandle(
237 info.m_bFatFont,
238 info.m_bUnderLine
239 )
240 );
241 }
242 }
243 }
232行目。色指定のチェックの有無のチェックを無効にしたらとりあえず色分けはされた。正規表現キーワードが正規表現キーワードN以外の色指定をしている場合、チェックの有無をみてはいけない。ここでのチェックを期待しているコードがある場合、悪影響がある。
* r1576@2009-05-27 21:15 で直りました。
2009年05月19日 (火) ステータスバーの各部分をダブルクリックすると動作モードを変更できるらしい。知らなかった。マウスポインタを「手(=clickable)」に変えたうえで、シングルクリックでトリガされるべきだとおもた。
最終更新: 2009-11-26T01:48+0900
♪ [SakuraEditor] ぐちぐち。
改行コードの意図しない混在が嫌で、ファイル中に存在する改行コードをステータスバーに列挙してみた。
 CRLF改行のみの一般的な画面 CRLF改行のみの一般的な画面 |  LFと CRLFが混在。コピペなんかしてるとよくこうなる。 LFと CRLFが混在。コピペなんかしてるとよくこうなる。
|
") まずないだろうという判断のもと表示スペースを削った結果、一部の文字が切れてます。(CRとLFとCRLFが混在) まずないだろうという判断のもと表示スペースを削った結果、一部の文字が切れてます。(CRとLFとCRLFが混在) |  改行がなければステータスバーにも表示なし。 改行がなければステータスバーにも表示なし。
|
publicなメンバ変数、豊富なアクセサ、中身すけすけで便利な friendクラス指定、管理下のデータメンバを非constで晒す C...Mgrクラスの constメンバ関数。どれも利用する側からすれば便利だったけど、オープンすぎて必要最小限の変更をつかまえることができずに毎回のフルスキャン。
どうするのがいいのかなあ。
Ctrl+Sに改行コードチェックマクロ(これから書く)を割り当てて、保存前に「改行コードが混在してるがそれでいいのか?」と確認しようか。すでに Ctrl+Sには Subversionを使ったバックアップマクロが割り当てられているが、どちらも JScriptなので片方を eval()でチェインして……。
2008年06月04日 (水) 状態表示系のボタンが好き。でも基本はツールバー非表示。
最終更新: 2010-07-05T02:44+0900
♪ [SakuraEditor] 現在適用されているファイルタイプを表示/変更するツールバーボタン
既存のコード(主に検索ボックス)の切り貼りで、とりあえず機能するものに。
")
ソース面の難はニンともしがたいが機能面の問題くらいは何とかしたいところ。以下、わかっている問題点。
検索ボックスより右に表示できない。(済み)リストにフォーカスがある状態では(検索ボックスと同様に)共通設定で割り当てたキーボードショートカットが効かない。(済み)マウスオーバーでツールチップが出ない。(対応しない)頭文字を利用した選択。(Jを押すと Jで始まるアイテムを順番に選択する機能)(済み)ツールバーを非表示から表示にしたとき、現在のタイプ別設定を反映していない(2010-06-29追記&修正済み)。
追記@2008-06-05: 「検索ボックスより右に表示できない。」を修正した。
switch-caseで break忘れというまぬけぶりが原因だった。
フォント(HFONT)の削除漏れも修正した。
ツールチップはリストの上下数ピクセルで出ていた。(役に立たない!でもマウスオーバーでツールチップが出てもうるさいだけなのでそのまま)
追記@2008-06-05: リストのキーボード操作「頭文字を利用した選択」を有効に。
他に、WM_PAINTで行っていた処理を、本来あるべき位置である WM_COMMAND(CBN_SELCHANGE)で行うように変更した。
キーボードアクセラレータを有効にするのは難しい。矢印や PageUp/PageDownキーまでが登録されているから、単純に有効にするとアクセラレータにそれらの入力を奪われてリストの操作が行えなくなる。
追記@2008-06-14: キー割り当てを有効に。
ドロップダウンリストにフォーカスがあるときでもエディタのキーボードショートカットを有効にした。優先順位は
- リストの操作(↑, ↓, ←, →, PageDown, PageUp, Home, End, F4, Alt+↓で全部かな?)
- キーボードショートカット (↑, ↓, ←, →, PageDown, PageUp, Home, End, F4を使わないものと、Tab、Shift+Tab以外のもの)
- 頭文字を利用したリストアイテムの選択
なぜ一部のキーボードショートカットを無効にするかというと、リストの先頭のアイテムが選択されているときに Homeを押してもリストはこの入力を処理しない(すでに先頭が選択されているから)のだが、リストの選択位置に依存してキーの意味が変わってしまう(リストの先頭を選択↔キャレットを行頭に移動)のは不自然だと思うから。同様のキーをわかっている分だけ無効にした結果が上記リストの 2。モディファイアキーの状態やリストの選択位置を考慮して、もっと多くのキー入力をキーボードショートカットとして渡す余地はある(が、こんなアドホックな対処にこれ以上の手間をかけるのもどうかと)。
SakuraEditorに欲しい機能
ウィンドウのリサイズに追従する「現在のウィンドウ幅で折り返し」
追従しないことにむしろ驚いた。ブラウザにできてテキストエディタにできないはずがない。
標準入力から編集テキストを読む機能
ファイル名も与えられていた場合は、それを上書き保存先にしてくれると尚良し。長めの出力をコマンドプロントからエディタに流して読んだりできる。
svn diff hoge.rb | sakura --stdin "hoge.rb.diff"
追記@2009-07-19: アップデート > SakuraEditor(Toolbar-FileTypeBox)_rev2.diff
Set/GetWindowLongPtr(hwnd, GWLP_USERDATA, ) の代わりに Set/Get/RemoveProp(hwnd, TEXT("MyData"), ) を使うようにした。
参考> http://hilbert.elcom.nitech.ac.jp/~taki/program.html
1. そもそもあった疑問: GWLP_USERDATAはウィンドウクラスに属するのかウィンドウに属するのか?
以下のものを見つけた。
- Set/GetClassLongPtr()
- WNDCLASSEX.cbClsExtra
- WNDCLASSEX.cbWndExtra
答え。GWLP_USERDATAはウィンドウに属し、その領域は WNDCLASSEX.cbWndExtraの値に従って確保される。
2. ぎゃっ! WNDCLASSEX.cbWndExtraなんて変更してなかった。
いったいどこを読み書きしていたんだろう? クラッシュしなかったのは Windowsが俺みたいなうっかりもののために余白を空けていたから?
言い訳。msdnのこの記述は非常に誤解を招きやすいと思う。予め 32ビットだけメモリが確保されてると勘違いしても仕方ないじゃない?
GWLP_USERDATA | ウィンドウに関連付けられた 32 ビット値を取得します。この 32 ビット値は、ウィンドウを作成したアプリケーションで使用する目的で各ウィンドウが持っているものです。この値の初期値は 0 です。
現状の理解で、この「32 ビット値」の出所は、読み書き(Get/Set)の単位が 4バイトだというところから。LONG=32ビットだから。
ここで、LONG_PTRが 64ビットのとき、GetWindowLongPtr(,GWLP_USERDATA)は 64ビット値を取得するのでは?ドキュメントあってる?という新たな疑問。
3. いずれにしろ
GWLP_USERDATAのように汎用的な場所から取得した値を恐る恐る CMainToolbar* にキャストするより、特別な名前をつけた場所に保存した値をキャストする方がまだ安心できる、という理由で改訂した。
ありふれた課題のようで GWLP_USERDATA を検索するだけで似たような話が見つかる。最初にリンクを張ったページは理解しやすかったが ATLのは難しい。これから読む > WTL/ATLのメッセージマップ実現のしくみ
GWLP_USERDATAと WNDCLASSEX.cbWndExtraが別物の可能性。
別物。GWLP_USERDATAは負のオフセット(-21)。cbWndExtraで確保した領域には 0から始まるオフセット(バイト単位)でアクセスする。
GWLP_USERDATAの有効な領域はポインタのサイズに関係なく、ドキュメント通りの 32ビットなのかについては winuser.hを見てもよくわからない。GWLP?_USERDATA(-21)から GWL_EXSTYLE(-20)まで差が 1しかないし……。GWLP?_* というのはオフセットでなく特別扱いされる値で、Windowsのソースを見ないと何もわからない、ということ? GWLP_USERDATAにポインタを格納できるのとできないのの差は大きいからハッキリ 64ビットサイズだと知りたい。
/* * Window field offsets for GetWindowLong() */ #define GWL_WNDPROC (-4) #define GWL_HINSTANCE (-6) #define GWL_HWNDPARENT (-8) #define GWL_STYLE (-16) #define GWL_EXSTYLE (-20) #define GWL_USERDATA (-21) #define GWL_ID (-12) #ifdef _WIN64 #undef GWL_WNDPROC #undef GWL_HINSTANCE #undef GWL_HWNDPARENT #undef GWL_USERDATA #endif /* _WIN64 */ #define GWLP_WNDPROC (-4) #define GWLP_HINSTANCE (-6) #define GWLP_HWNDPARENT (-8) #define GWLP_USERDATA (-21) #define GWLP_ID (-12)
追記@2010-06-29: ツールバーを非表示から表示にしたとき、現在のタイプ別設定を反映していないのを修正
// まだファイルタイプは取得できないっぽい。常に基本(0)になる。 //::SendMessageAny( m_hwndFileTypeBox, CB_SETCURSEL, m_pOwner->GetDocument().m_cDocType.GetDocumentType().GetIndex()+1, 0 ); ::SendMessageAny( m_hwndFileTypeBox, CB_SETCURSEL, 0, 0 );
とコメントアウトしていた部分を復活させて
::SendMessageAny( m_hwndFileTypeBox, CB_SETCURSEL, m_pOwner->GetDocument().m_cDocType.GetDocumentType().GetIndex(), 0 );
ちょっと修正した(謎の+1を取り除いた)だけ。
アプリケーションの起動と同時にツールバーが作成されるときであれば、コメントの内容は正しい。アプリケーションが起動してファイルが読み込まれた後でツールバーが表示する設定に変更されたとき(このときもツールバーが作成される)は、そうではなかった。
2008年01月16日 (水) Pythonかわいいよ、Python
♪ [SHJS][SakuraEditor][javascript] SHJSと SakuraEditor用のハイライトルールファイル
SHJSの javascript定義ファイル(lang/sh_javascript.js)の元になったファイル(javascript.lang)の中身がこれ。
include "java.lang" subst keyword = "abstract|break|case|catch|class|const|continue|debugger|default|delete|do|else|enum|export|extends|false|final|finally|for|function|goto|if|implements|in|instanceof|interface|native|new|null|private|protected|prototype|public|return|static|super|switch|synchronized|throw|throws|this|transient|true|try|typeof|var|volatile|while|with"
javaて……。キーワードにしても使ったことのないものがいっぱい。
あまりにあんまりなんで一から書いた。(sh_javascript.js, sh_javascript.min.js)。 参照したのは JScript5.5の HTMLHelpなので JScript.NETや ECMAScript4には対応していない。古典的な JavaScript。
ついでに同じものを SakuraEditorにも。(javascript_keywords.zip)
♭ ryojiパッチ(fix_menubarmessage.diff)を適用したものだと、 行・列番号の表示よりも右の部分にゴミが..