Twitter で読んだけど ABC217-D「Cutting Woods」を Ruby でまじめに解いた人は対策ができていたらしい。自分は(略)なかった」 嘘だった。別解として BIT バージョンを通していた>提出 #28790707 (AC)。「対策」とは値から添字を逆引きする BIT のあまり一般的ではないメソッドのことであり、これを通したのがちょうどひと月前だってのに、どうして今日通せなかったの?■@2022-03-01 20220228で (30,60)-木を使って通したあとだけど、コンテスト中の最初の方針であった BIT を使っても D 問題を通したよ>提出 #29790983 (AC / 1944 ms / 後註)。Hash ベースの BIT でギリギリ間に合ってるのに最初の提出(Array ベースの BIT を使っていて有利)で RE/WA/TLE になったのなんでだろう。ともあれ、WA の原因は BIT の使い方に間違いがあったからなんだけど、貼り付けた自分のコードが信用できなくてサンプルを合わせるときに手を入れる場所を間違えたんだな。RE/WA だけならデバッグをがんばれたけど TLE もあったので諦めてしまった。□(註) さっきの提出のコメントに嘘があった。「
アクセス可能な範囲(0..@n-1)なら」の正しい範囲は
0..@n-2。スクリプトは合ってる。コメントだけ嘘。The series of pairs is separated by the ampersand, "&" (or semicolon, ";" for URLs embedded in HTML and not generated by a <form>...</form>. See below).」「
This convention is a W3C recommendation.[6] W3C recommends that all web servers support semicolon separators in addition to ampersand separators[9] to allow application/x-www-form-urlencoded query strings in URLs within HTML documents without having to entity escape ampersands.」 W3C がってところが今となっては、かなあ。もちろん立場が違えばセミコロンが解釈できなくて話が通じない相手とはそれまでっていうのが自分のスタンスなんだけど、AtCoder には合わせるしかない。■@2022-03-07 最近 OpenBD のデータが、抜けているというより常に取得できてないなと気がついて見たら、セミコロン区切りのせいでクエリが失敗するようになっていた。ここでもなのか。
no! if U[a,b] の no! を取り除くとダメになるケース(8 4/3 3 3 1 1 1 1 1/1 2/1 3/2 3/7 8)がある。この提出 #29483417 (WA×1) を阻んでいる random_21.txt が同等の(無駄な辺と森化による辺の必要数の減少が相殺する)ケースだと思う。■■■E 問題「Subtree K-th Max」。最近似た名前の問題がありましたね>「Prefix K-th Max」。一読して表現の微妙な変化に気がついたんですよ。ABC234で「K 番目に大きい値」という表現だったものが ABC239 では「
大きい方から Ki 番目の値」になっていた。それが「中途半端な値は見ようによって大きい値でもあるし小さい値でもある。自分に言わせればそれは単に「大きい方から K 番目の値」なんであって、大きい値でも小さい値でもない」をうけての変化だとは思わないけど、自分が理解しやすい表現になっていたのは間違いない。それなのに AC 前の5分で 2 WA しました(WA、WA、AC)。読んで、表現の変化にも気がついて、でも結局間違えるんだ。手癖で書いてるってことなんだろうなあ。■「AtCoderの公式生放送「あーだこーだー」 第51回 - YouTube」を聞いていると E 問題「Subtree K-th Max」に関連して Wavelet Matrix の単語が何度も聞こえてきた。E 問題では K の上限が意図的に小さく抑えられていて、ここを突破口にして解けよ、というヒントがあからさまだったけど、さもなければ Wavelet Matrix を使って解くことになったらしい。Crystal では通ってるぽいのに Ruby で TLE になるの悔しいよね。通ってほしい。参考図書『[単行本] 岡野原 大輔【高速文字列解析の世界――データ圧縮・全文検索・テキストマイニング (確率と情報の科学)】 岩波書店』は持ってるだけは持ってる。WEB+DB PRESS vol.42 の記事を読んで著者の名前を覚えていた。
プラスアルファで悉くつまずいて AC に辿り着けない」とか「
区間の左右端と節約回数の上下端が off-by-one エラーを誘発しやすい感じ(ドツボにはまった経験から書いています)」を今日も再現しておかしくはなかった。早々に愚直解とランダム入力を組み合わせてダメケースの発見に努めることができたのが運命の分かれ目。終了3分前の提出 #29545375 (AC)。これ水 diff なんだって。全く同じではないにしてもかつての黄 diff が形無しですよ。
1ビット分誤差が入るからダメって?」に対するツッコミにならないのでは?という疑問には、それはそうと思う。誤差が大きすぎるという納得はわからない。
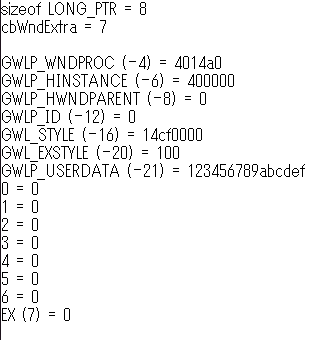
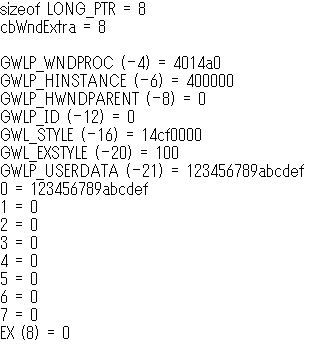
Valid values are in the range zero through the number of bytes of extra window memory, minus the size of a LONG_PTR」を読み間違えていた。有効な値は 0 から cbWndExtra までと 0 からマイナスポインタサイズまでではなく、0 から「cbWndExtra マイナス ポインタサイズ」までだった。えええええ、そこにカンマを入れる? そしてカンマひとつでここまで勘違いをひきずるか>自分。■オンラインでは見つけられなかったけど PC 内に日本語訳を見つけた。「
nIndex 取得する値に 0 から始まるオフセットを指定します。有効なオフセットは、0 から拡張ウィンドウメモリのバイト数 -8 までです。たとえば、拡張メモリが 24 バイト以上ある場合、16 を指定すると、3 番目の整数値が取得できます。その他の値を取得するときは、次のいずれかの値を指定します。」 具体例まで追加していい仕事してますよ。見つからんかったけど。
{kind=link}
{kind=link}
{kind=link}
{kind=link}