2012年02月14日 (火) iPad3の噂の解像度はそれだけで正義。ScanSnapが出力した JPEGを拡大してなお全体を表示する余地があるくらいだ。そんなことは PCででもできない。24.1インチの PCモニタよりずっと小さい大きさに、WUXGA以上の解像度。とにかく自炊 PDFの表示を一目見てみたい(疑っているのではなく圧倒されたくて)。■ガラス越しのタッチインターフェイスには慣れるもんなんだろうか。
最終更新: 2021-09-14T21:45+0900
♪ [ProjectEuler] Problem 191
Problem 191
別個に知っているが関連があるとは思っていなかった二つの Webサイト、「ときどきの雑記帖 再起編 2012年2月(中旬)」から「Problem 191 - もうカツ丼でいいよな」へのリンクがどういう観点で張られたのか、確かめるために*リンク先を読みたいがネタバレはいかん。との思いでがんばった。
まず問題がおかしい。欠席は3連続でなければ許されるのに遅刻は1回までとか⁑。まあどうでもいい。それより問題文が難しかった。punctuality(無遅刻)と forfeit(権利の喪失)の2単語は辞書を引いたし、カンマや関係詞で連続する文は主語述語修飾関係がわかりにくいので、細かいことを考えずに流れに注意して4、5回読み直した。81という数字がどういう経緯で出てきたのか(※OALの3文字で作る長さ4の文字列=3^4通り)、説明があれば問題文を理解する一助となったろうに、そんなものはなかった。
Half_period_strings行以降のバグてんこ盛りのぐだぐだは一重に処理時間と消費メモリを節約することが目的。正規表現でやることは最初からの方針だったのだけど改行で連結した 30-period stringsを検索しようとしたら Rubyがメモリ不足で落ちる。ワーキングセットが 2GiBを超えたあたりだったと思う。ならばと一行分ずつ逐一処理しようとすると時間がかかりすぎる(30分はかからないが)。Threadで分散してみようとしたが Ruby(1.9)には GVLとかいうのがあって CPUを 33%までしか使ってくれなかった。Fiberもそういう期待には応えてくれないみたい。プロセス間通信は面倒。時間が許すなら、
Thirty_period_strings = Joint_period_strings[
Fifteen_period_strings, Fifteen_period_strings
]
p Thirty_period_strings.inject(0){|count,tristr|
count + 1 + tristr.scan(/A|(?<=AA)O|(?<=A)O(?=A)|O(?=AA)/).length
}
これ(を配列を要求しないように書き換えたバージョン)だけで済んでしまうことなのに、15-period stringsと 30-period stringsの間には処理すべき量に雲泥の差があった。
戦略は、
- 一つまでしか許容されない Lをひとまず無視(scoreというのが Lの持ち込む派生語の数に関連した値)。
- (現実的に扱える量である)15-period stringsの連結を考える。
以下、偶然なのかなんなのか、答えは出たが説明できないスクリプト(ピリオドの置き方が Ruby 1.9専用みたい)。実行時間は1秒未満。
# PE 191
Letters = %w(O A).freeze
Re_filter = /^(?:(?!AAA).)*$/
Joint_period_strings = lambda{|*args|
return args.first.product(*args.drop(1))
.map{|_| _.join('') }
.select{|_| _.match(Re_filter) }
}
Three_period_strings = Joint_period_strings[
Letters, *Array.new(2){ Letters }
].freeze
Six_period_strings = Joint_period_strings[
Three_period_strings, Three_period_strings
].freeze
Fifteen_period_strings = Joint_period_strings[
Six_period_strings, Six_period_strings, Three_period_strings
].freeze
Re_score = /A|(?<=AA)O|(?<=A)O(?=A)|O(?=AA)/
IndexedScore = Struct.new(:num, :sum)
Half_period_strings = Fifteen_period_strings
l_index = Hash.new{|h,l_back| h[l_back] = IndexedScore.new(0,0) } # by ending codon. {'OOO'=>IndexedScore,'OOA'=>,...}
r_index = lambda{|r_front| return l_index[r_front.reverse] } # by starting codon. {同上} (実体はl_indexと共有)
Half_period_strings.each{|str15|
score = l_index[str15[-3,3]]
score.num, score.sum = score.num+1, score.sum+str15.scan(Re_score).length
}
p l_index.keys.product(l_index.keys).inject(0){|count,_| l_back, r_front = *_
joint = l_back + r_front
next count if Re_filter !~ joint
l_score, r_score = l_index[l_back], r_index[r_front]
joint_score = [joint, l_back, r_front].map{|_| _.scan(Re_score).length }.inject{|a,b| a-b }
next count + l_score.sum*r_score.num + r_score.sum*l_score.num + (1+joint_score)*l_score.num*r_score.num
}
p Process.times
@2012-02-15
他所を見て回った。得たヒントは「漸化式」「DP」「scoreは Oを数えるだけ」「prize stringは Lの出現回数(0-1)と先端部の Aの連続数(0-2)で classifyできる」。
「scoreは Oを数えるだけ」
実際、どちらでもいけた。だけど下の方が良いのは明らか。ビットを数える処理にも置き換えられるし、joint_scoreは不要になるし。
score = tristr.scan(/A|(?<=AA)O|(?<=A)O(?=A)|O(?=AA)/).length score = tristr.count(?O)
「prize stringは Lの出現回数(0-1)と先端部の Aの連続数(0-2)で classifyできる」
このヒントを基に以下のスクリプトができた。実行時間はコンマ1秒未満。10倍高速。早く書けてバグが無くて実行が速くて、昨日と一昨日の自分が何に頭を悩ませてたのか不思議になるよね。この着想に独力でたどり着けないところが己の限界。
# coding: utf-8
# PE 191
Extend_prize_strings = lambda{
L,A,O = 1,1,1
A0L0, A0L1, A1L0, A1L1, A2L0, A2L1 = *0..5
return lambda{|prize_strings| ❦=prize_strings
return [
# a=0; l=0
❦[A0L0]*O + ❦[A1L0]*O + ❦[A2L0]*O,
# a=0; l=1
❦[A0L0]*L + ❦[A0L1]*O + ❦[A1L0]*L + ❦[A1L1]*O + ❦[A2L0]*L + ❦[A2L1]*O,
# a=1; l=0
❦[A0L0]*A,
# a=1; l=1
❦[A0L1]*A,
# a=2; l=0
❦[A1L0]*A,
# a=2; l=1
❦[A1L1]*A
]
# a=3 (prize forfeited)
❦[A2L0]*A
❦[A2L1]*A
# l=2 (prize forfeited)
❦[A0L1]*L
❦[A1L1]*L
❦[A2L1]*L
}
}.call
Period = 30
# index of prize_strings: i = (a<<1)|l
# a = consecutive As at a prize string head. (0,1,2)
# l = occasion of L. (0,1)
# starting state(=prize string length is zero): a=0;l=0;prize_strings[i]=1
prize_strings = [1,0,0,0,0,0]
Period.times{
prize_strings = Extend_prize_strings.call prize_strings
}
p prize_strings.inject(&:+)
p Process.times
C++11だとコンパイル時に答えを出してしまいそうだ。再帰30回だし。
2012年02月09日 (木) しばらくの間 Firefox(3.6.26)を起動したくない理由があって IE9を開いた。アドレスバーに適当な文字列を打っても検索してくれたりはしないのね。だったら検索欄を残しとけよ。テンキーの 0を使って文字サイズのリセット(Ctrl+0)はできないのね。拡大(Ctrl++)と縮小(Ctrl+-)はどっちでもできるのに。(エラー画面以外の)何も表示する前からうんざりだよ。■俺が初めての PCで初めてのインターネットブラウザで初めて Webページを表示したときに助けになったのは IE(4か5)の検索ペインだった。メニューバーも検索ボックスも気のきいたアドレスバーもない IE9には何がある?■■■すばらしい。ぐちぐち文句を垂れるだけの自分とは違って行動してるね。「Firefoxの過去履歴を統合する - もの置き処」履歴切り詰めのトリガーがもしサイズやレコード数だったら結合してもすぐ……とか考えるけど、期待して Firefox 10.0上げ。■@2012-04-12 今は Fx11.1なんだけど、places.sqliteが暗号化されてるかデータベースファイルじゃないってエラーになった。sqlite3(3.7.7.1)コマンドで VACUUM;してやると正常に完了した。
2012年02月08日 (水) Calibreはいくつか前のバージョンから(0.8.38の今も) periodicalNameの切り出しルールを変えたのかな。どういう仕組みで決まるのか本当は知らんけど。titleが CNNだと後ろに続く日付までが periodicalNameに含まれてしまって、日付が違うだけで新しいシリーズとして Sony Reader上で場所をとってしまう。titleが C N Nだと大丈夫。Cnnだとアウト。NASAはセーフで、CNNNもセーフ。三文字頭字語のニュースソースってありがちだと思うんだけどな。■■■@2012-02-09 .pyoにコンパイルされてるから諦めてたけどソースを見つけた。sony_cache.pyの periodicalize_book()だ。logを見ると最近になって変更があったわけではない。[ (とその後に続く日付)より前の部分が空白を除いて4文字未満のときにそれを捨ててしまうのは最初からの仕様だ。変わったのは俺が、定期購読の「タイトルをタグに追加」しなくなったこと。これによって最初のフォールバックを素通りして最後の選択:book.title(日付つき)が使われるようになった。タイトルをタグに追加したくない理由は、タグはコレクションとなって Reader上に現れるから。定期購読にあるのと同じバインダーはコレクションにはいらない。一度に表示できる数は9しかないのだから。さて、どうしたものか。
2012年02月07日 (火) 履歴。Firefox4以降(いこうのいは(大なり)イコール/インクルーシヴのい。最近エレベータの注意書きに震度4以上の時と震度4以下の時の二通りが書かれているのを見た。震度4の時は相反する指示のどちらに従えと?)の履歴に絶望したのを何度も書いた。20110327,20110412,20110719,20111216。こういう履歴とか MRUっていうのは開いた日時で記録されるけど、俺にとって開いた順番は大した意味がない。むしろ、閉じた順番が大事。閉じる直前には確実にコンテンツをそれも長い時間、目にしているのだ。コンテンツをトリガーに想起されるのは閉じた順番であり日時であって、場合によっては前日やもっと前だったりする開いた日時ではない。Firefoxには 3.6までの履歴保存機能とともにそういうところにも目を向けて欲しい。あとね、履歴のプライマリキーは日時(+URL)であって、URLではない。最終訪問日時順に表示した履歴をもとにブラウジングしてみればいい。クリックする度に順番が入れ替わって使いにくさがわかる。今の Firefoxは記録期間も記録内容も貧弱なんだよ。
2012年02月06日 (月) Rubyの Array#eachに対して不安になること。これは要素を先頭から yieldしてくれるんだろうか?そうは明記されてないけど、というもの。そういうわけで、時々は添え字をカウントアップしながら配列を処理してる。Rubyっぽくないけどそういう要求があるときもある。
2012年02月05日 (日) ビットブリット。"The following list shows some common raster operation codes." COMMON? と思って検索すると名前のないのがいっぱい出てきた。「Ternary Raster Operations (Windows)」SourceビットとDestinationビットとPattern(Brush)ビットの2×2×2の組み合わせそれぞれの結果を1にするか0にするか、全256通りを選択できる。三度の呼び出しが一度に減って嬉しい。■使用例。Destは文字の背景。Srcは白背景黒文字のマスク(ただし白黒やグレイスケールではなく輪郭に色が出てるはず)。Patは(本来の)文字の色のブラシ。ROPは 0x00B8074A. 0xB8(0b10111000)というのが P,S,Dがそれぞれ 1,0のときの出力を特定の順番で並べたもので ROPコードのキー。ビットパターンで望みの結果を示すことはできるけどその結果を導くビット演算は理解できない。特にXORが関わっては。("if S=1 then D if S=0 then P" = 0xB8 = PSDPxax ※大文字は参照するビットのソース。小文字は演算。逆ポーランド記法)
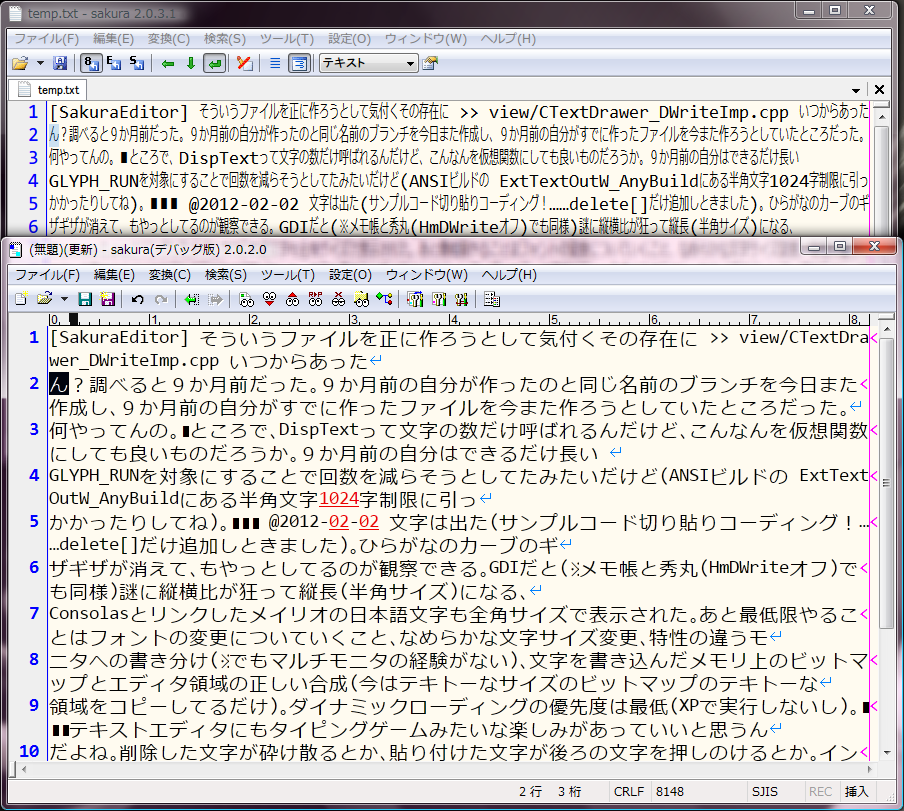
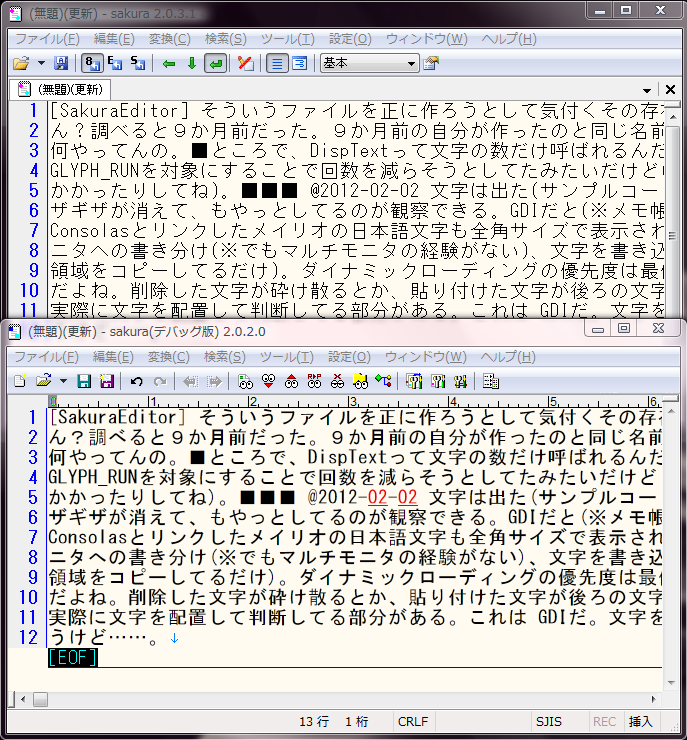
2012年02月01日 (水) [SakuraEditor] そういうファイルを正に作ろうとして気付くその存在に >> view/CTextDrawer_DWriteImp.cpp いつからあったん?調べると9か月前だった。9か月前の自分が作ったのと同じ名前のブランチを今日また作成し、9か月前の自分がすでに作ったファイルを今また作ろうとしていたところだった。何やってんの。■ところで、DispTextって文字の数だけ呼ばれるんだけど、こんなんを仮想関数にしても良いものだろうか。9か月前の自分はできるだけ長い GLYPH_RUNを対象にすることで回数を減らそうとしてたみたいだけど(ANSIビルドの ExtTextOutW_AnyBuildにある半角文字1024字制限に引っかかったりしてね)。■■■ @2012-02-02 文字は出た(サンプルコード切り貼りコーディング!……delete[]だけ追加しときました)。ひらがなのカーブのギザギザが消えて、もやっとしてるのが観察できる。GDIだと(※メモ帳と秀丸(HmDWriteオフ)でも同様)謎に縦横比が狂って縦長(半角サイズ)になる、Consolasとリンクしたメイリオの日本語文字も全角サイズで表示された。Consolas+メイリオだとグリフが表示されてなかった一部のUnicode記号も出た。あと最低限やることはフォントの変更についていくこと、なめらかな文字サイズ変更、特性の違うモニタへの書き分け(※でもマルチモニタの経験がない)、文字を書き込んだメモリ上のビットマップとエディタ領域の正しい合成(今はテキトーなサイズのビットマップのテキトーな領域をコピーしてるだけ)。ダイナミックローディングの優先度は最低(XPで実行しないし)。■■■テキストエディタにもタイピングゲームみたいな楽しみがあっていいと思うんだよね。削除した文字が砕け散るとか、貼り付けた文字が後ろの文字を押しのけるとか。インタラクションと打てば響くレスポンスが。■■■@2012-02-03 全角半角を、実際に文字を配置して判断してる部分がある。これは GDIだ。文字を DirectWriteで描いた場合、描画と判定が食い違うことがある。おかしな環境に限った話だと思うけど……。TODO:下線。斜体のオーバーハング。■■■DONE:下線, DPI-aware. TODO:斜体のオーバーハングと背景画像対応。画面内の文字の数に比例してカクついてる……。■ GDIだと描画がおかしくなる環境でしか積極的なメリットを見出しにくい Consolas 48での比較画像と Consolas 14での比較画像。MS ゴシックだとこっちはやらせかってぐらい明らかに違うけど(っていうか違うフォントだよね?※)、表示品質を気にする人は今更使ってないだろう(選択肢が豊富な英字等幅フォントにリンクされて表示されることはわりとあるかもね。日本語部分がMSゴシックになるときのがっかり感ときたら……)。※文字が1000分の100太いのは好みによる味付けです。gdippを使ってもほぼ同じ表示が得られてるのでフォントが違うってことはなかった。「MS~系のフォントの場合は、サイズが16pt以下の場合、ビットマップフォントが使われるようです」ということみたい。■DONE:背景画像対応。TODO:(背景画像なしのときの)斜体のオーバーハング。ノーマルのサクラは色の切り替わり部分を除いて切り落とさずに表示できてるんだけど。■■■@2012-02-05 Very Sleepyで DWriteCreateFactoryとして表される DWriteモジュール唯一のエントリから呼び出される memcpyで費やされる時間の合計が絶望的に長い。待ち時間の50%がこれ。DirectWriteを(効率的な)ハンコにするには DWriteTextLayoutをキャッシュしても駄目なのはわかっていて、GLYPH_RUNを再利用すべきなんだろうか、RenderTargetを GDIでなく D2Dにしないと駄目なんだろうか。一文字ハンコにするのがもう非現実的で、1以上の長さを持つ GLYPH_RUNを対象にすべきなんだろうか。教えて秀丸さん。■■■@2012-02-08「gdippの DirectWriteブランチ」でお勉強。■必要であるか否かに関わらず宣言的に IDWriteBitmapRenderTarget->Resize()を呼んでいたのだけど、これをやめると相当速くなった。それでも、Ctrl+V押しっぱなしの連続貼り付けが時々引っかかる。PageDownキーでの全画面書き換えはやっぱり待ちが入る。ブラックアウトしたまま 10秒以上待たされたりしなくなったというだけのこと。■■■TODO(追加):英字と日本語のベースラインを揃える(今は英字が浮いてる)。■DONE@2012-02-29 baseline揃え。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2012年01月26日 (木) 「僕の経験から言うと、日本人には「イングランド=英国」と考える傾向があるみたいだ。僕自身ですら、スコットランドのことを詳しく知らないしね。スコットランドは英国の一部、カリフォルニアが米国の一部であるように、そんな風に僕は認識してる・・・・・・・しかし、僕のスコットランド人の友達は、スコットランドはイングランドと別の国なんだと言って譲りません。(笑)」英語の時間に「イギリスは England」って習ったもんね。そのせいだ。高校の時には友人から「グレートブリテンおよび北アイルランド連合王国」みたいなのを聞いてへぇーとなって、「スコットランドヤード」というゲームでこれがイギリスの警察の名前だと聞かされて、まあそんな感じ。ニュージーランド人(コメ主)とスコットランド人と同じくらいの意識の隔たりがあるよね。今はイギリスっていうと UK(ユナイテッドキングダム)か GB(グレートブリテン)だろって思う。
2012年01月23日 (月) [SonyReader] ホーム画面に最後に読んだ3冊を表示するために PDFファイルの更新日時を操作してる(→20111101p01)せいだと思うんだけど、サムネイルの再作成と最後に読んだページのリセットが行われることがある。特に最後に開いていたページのリセットが困る。更新日時のセットってまさに読みかけの(最後に開いていた)本に対して行うわけだから。ページ履歴が残ってればページを探す苦労はないけど、cacheExt.xmlの肥大化対策として historyタグを削除する(→20111226)こともあるわけで。cacheExt.xml(それか cache.xml)の日付情報を併せて書き換えてファイルが新しくなったと誤認されないようにしないといけないのかも。■■■ 現在 PDF数 900以上。16GBメモリースティック 10GiB使用。32GB SDカード 20GiB使用。PCに接続して内容を書き換えた後、MS・SDなし、MSのみ、SDのみでは問題ないが、MS・SD二枚差しだと反応が極度に遅くて再起動を数回繰り返したりバッテリーがなくなるまで再起動を繰り返したりする。充電したりリセットしたり再起動したりしながら気長に待ってると最終的には使えるようになる。誰でも書き換えられるメモリーカードの中身に依拠して動作を不安定にしたらダメだよ。リカバリはできてるともいえるけど。他人には全く使用を薦められません。■■■ @2012-01-28 タイムスタンプが新しくなってもサムネイルの再作成は行われなかった。むしろ本来の更新日時を復元されて古くなった方のサムネイルが再作成された。いずれも、再開ページはリセットされていない。むむむ。この前はバッテリー切れまで再起動を繰り返すうちに本体の時刻までが狂っていたのだけど、そういう例外的な事象に関連してのことだったのか?そういえばシリーズものをひとつにまとめた PDFに続きをくっつけてサイズが変わっても続きから読めてたもんなあ(サイズと更新日時はどちらも cache.xmlに size, date属性として記録されているので、実際のファイルと食い違っていればわかる)。■■■@2012-04-20 ページ位置のリセットは本を「未読の書籍」コレクションから開いたときに行われる気がする。大丈夫なときは書籍一覧から開いたときだったような。■■■@2012-09-10 ページ位置のリセットの原因は PDFの保存形式の違いだと思われる。ChainLPで作成した PDFも Adobe Acrobat 9で結合した PDFも、一度 Acrobat 9で開いて[ファイル]>[名前を付けて保存]という決まった操作で保存するようにしてから全然起こらなくなった。
2012年01月22日 (日) [BAD BOY] 雨で濡れてるうちにリムとスポークの汚れを(初めて!)拭き取っていたら後輪のスポークの一本がゆるゆるなのに気がついた。後輪といえば去年の 11月に振れ取りをしてもらった方だが、そんなに頻繁に調整が必要なものか?■@2012-01-24 計ってみたら同じ(反フリー)側のスポークがみな 18-20目盛りだったのにその一本は 5目盛りだった。だけどこれを締めるとまあその部分がブレーキシューに接触するわけで、5目盛りでないとバランスが保てない。締めた上で妥協できる程度には振れをとったけど、ハブが中心になかったりリムが楕円形になってても知らないよ。
2012年01月20日 (金) えっと……、TVに赤色の B-CASカード(※Wikipediaで見たら青カードでも大丈夫そうだ)がささってるのを確認して、BSアンテナ(6500円)を仰角41度方位角220度で取り付けて、エアコンの穴からケーブルを通したら、BSフジは見られるの? もちろんすでに家に通ってる光ファイバーを使った CATVサービスに加入する手もあるんだろうけど(最低料金が毎月1300円(500円)+工事費)。■ 放映時間。実は録画せずに見られる深夜帯(23:50~)がありがたかった。夕方に放映される鈴鹿は毎年苦労していた。たぶん、録画したら見ない。チャンネル権とか子供の頃の遠い記憶だ。■ あっ。N!H!K! アンテナ隠さないと。
2012年01月19日 (木)
最終更新: 2012-01-20T00:09+0900
♪ [ProjectEuler] Problem 10, 12, 14, 17, 19, 21, 23
穴埋め。解ける問題がはやなくなってきたから……(完全になくなってはいないはずっ)。
Problem 10
時間コストを空間コストに置き換えて。
arr = [true] * 2_000_000
sum = 0
2.upto(arr.size-1){|i|
next unless arr[i]
sum += i
i.step(arr.size-1, i){|j|
arr[j] = false
}
}
p sum
p Process.times
Problem 12
Rubyに頼った。prime_divisionのこと。
require 'mathn'
trinums = lambda{
tri, n = 0, 1
return lambda{
tri, n = tri+n, n+1
return tri
}
}.call
loop{
tri = trinums.call
div = tri.prime_division.inject(1){|d,_| f,e = *_; d*(e+1) }
if 500 < div
puts tri
p Process.times
exit
end
}
Problem 14
ゴールから攻めようとか小賢しいことは考えずに。
number_of_chain = lambda{
memo = {1=>1}
this = lambda{|n|
return memo[n] || (memo[n] = 1 + this[n%2==0 ? n/2 : 3*n+1])
}
return this
}.call
p (1...1_000_000).max_by{|_| number_of_chain[_] }
p Process.times
Problem 17
面倒なだけ。
cc = lambda{
return this = lambda{|n|
count, num = 0, n
digit1000 = num / 1000
if 0 < digit1000
count += this[digit1000] + 'thausand'.length
num -= digit1000 * 1000
count += 'and'.length if num != 0
end
digit100 = num / 100
if 0 < digit100
count += this[digit100] + 'hundred'.length
num -= digit100 * 100
count += 'and'.length if num != 0
end
digit10 = num / 10
if 2 <= digit10
count += {
20=>'twenty'.length,
30=>'thirty'.length,
40=>'forty'.length,
50=>'fifty'.length,
60=>'sixty'.length,
70=>'seventy'.length,
80=>'eighty'.length,
90=>'ninety'.length,
}[digit10*10]
num -= digit10 * 10
end
if num != 0
count += {
1=>'one'.length,
2=>'two'.length,
3=>'three'.length,
4=>'four'.length,
5=>'five'.length,
6=>'six'.length,
7=>'seven'.length,
8=>'eight'.length,
9=>'nine'.length,
10=>'ten'.length,
11=>'eleven'.length,
12=>'twelve'.length,
13=>'thirteen'.length,
14=>'fourteen'.length,
15=>'fifteen'.length,
16=>'sixteen'.length,
17=>'seventeen'.length,
18=>'eighteen'.length,
19=>'nineteen'.length
}[num]
end
return count
}
}.call
p (1..1000).inject(0){|sum,n| sum + cc[n] }
Problem 19
問題文が難しかった。閏年の条件として "A leap year occurs on any year evenly divisible by 4, but not on a century unless it is divisible by 400." って書いてあったけど、centuryって XX01年から XY00年の 100年間を指す語だと思ってるから、"a century"が XY00年のことだけを示してるとは思わなくて、結果的に 100の条件を読み飛ばした上に 400の条件を逆にとらえてた。
days_of_month = lambda{|year,month|
return 31 if [1,3,5,7,8,10,12].include?(month)
return 30 if [4,6,9,11].include?(month)
return 29 if year % 400 == 0
return 28 if year % 100 == 0
return 29 if year % 4 == 0
return 28
}
dow = 1 # 日月火水木金土=0123456. 1=Monday. 1900-01-01 was a Monday.
(1..12).each{|month|
dow = (dow + days_of_month[1900,month]) % 7
}
# Now dow indicates the day of 1901-01-01.
count = 0
(1901..2000).each{|year|
(1..12).each{|month|
count += 1 if dow == 0
dow = (dow + days_of_month[year,month]) % 7
}
}
p count
Problem 21
愚直に(←これしか書いてなくない?)。
d = lambda{|n|
divsum = 1
t, tmax = 2, n
while t < tmax
q, r = *n.divmod(t)
divsum += (t!=q ? t+q : t) if r == 0
t, tmax = t+1, q
end
return divsum
}
p (1..10000).inject(0){|sum,n|
dn = d[n]
sum + (n < dn && d[dn] == n ? n+dn : 0)
}
Problem 23
そのまま(←愚直にを言い換えただけ)。
class Integer
def abundant?
divsum = 1
t, tmax = 2, self
while t < tmax
q, r = *self.divmod(t)
divsum += (t!=q ? t+q : t) if r == 0
t, tmax = t+1, q
end
return self < divsum
end
end
expressible = [false] * (28123+1)
abundant = []
(1..(28123-12)).select(&:abundant?).each{|n|
abundant << n
abundant.each{|a|
break if expressible.size <= a+n
expressible[a+n] = true
}
}
p (1..28123).inject(0){|sum,n| sum + (expressible[n] ? 0 : n) }